Американские ученые проанализировали, как мозг обрабатывает речь в людном и шумном помещении. Оказалось, что разница в этом процессе зависит от того, насколько легко мы можем уловить речь и фокусируемся ли на ней. Исследователи использовали нейронные записи, сделанные с использованием инвазивной ЭЭГ у пациентов с эпилепсией, и компьютерное моделирование, чтобы показать, что когда мы следим за речью, которая тише общего уровня и перекрывается шумом, то наш мозг кодирует эту информацию, если она исходит от нашего собеседника. А если речь громче общего уровня, то мозг воспринимает речь не только того человека, на ком мы концентрируемся, но и остальных говорящих. Исследование опубликовано в журнале PLoS Biology.
Способность людей распознавать голоса среди шума и концентрироваться на одном диалоге, когда вокруг много говорящих, известна как «эффект коктейльной вечеринки». Наш мозг может разделять стимулы на разные потоки и решать, что из этого ему нужно, а что нет. Если говорящих несколько, то такая речь делится на целевые «проблески» (когда целевой говорящий говорит громче, чем фон) и на «маскировку» (когда целевая речь заглушается нецелевой и мы улавливаем «проблески» нецелевой речи). При этом, даже если мы сконцентрированы на беседе и одном говорящем, наш мозг все равно обрабатывает общий фон и нецелевую речь, что позволяет нам в момент беседы услышать, что кто-то позвал нас в толпе по имени.
Целевая и нецелевая речь обрабатывается по-разному. Речь, которая связана с задачей, кодируется в областях вторичной слуховой коры, включая верхнюю височную извилину, а та, что инвариантна к задаче — в первичной слуховой коре, включая извилину Гешля. Области верхней височной извилины реагируют на речь целевого спикера вне зависимости от того, насколько она была замаскирована. Но то, как происходит отделение целевой речи от нецелевой в среде, где много говорящих, и как мозг потом ее обрабатывает, до конца остается не ясным.
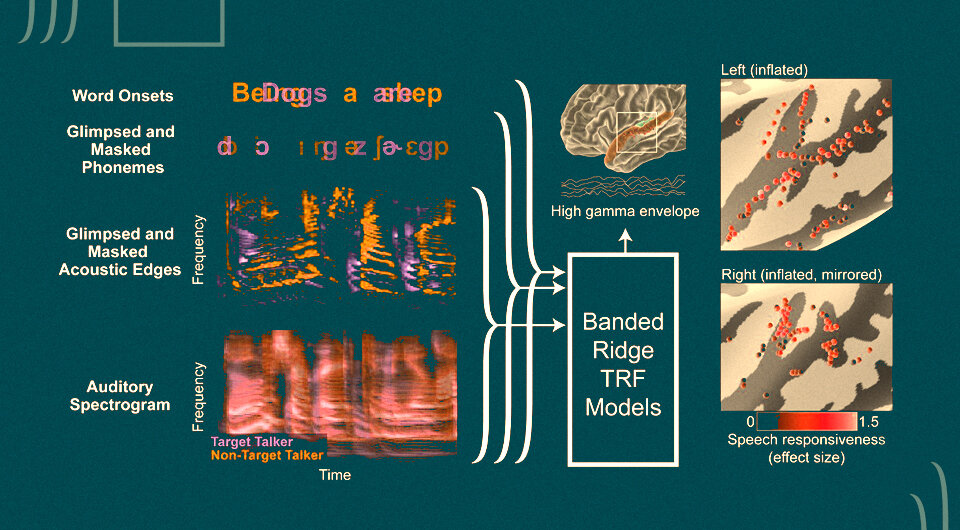
Исследователи из Колумбийского университета и Института медицинских исследований Файнстайна в США во главе с доктором Нимой Месгарани (Nima Mesgarani) изучили данные внутричерепной ЭЭГ семи пациентов, страдающих эпилепсией. Для мониторинга активности мозга и точного определния зоны начала приступа таким пациентам на поверхность или в структуры мозга подключают инвазивные эелектроды. У двоих пациентов электроды были имплантированы над левой височной долей, включая верхнюю височную извилину (STG), а у одного из них электроды разместили в левой извилине Гешля (HG). У остальных пяти пациентов электроды покрывали различные области левой и правой акустической коры.
Пациенты слушали рассказы, записанные мужским и женским голосом, одновременно. Задание было разделено на блоки и в начале каждого участников просили сконцентрироваться на одном из говорящих и игнорировать другого. Иногда рассказы прерывались и пациентов просили повторить последнее предложение целевого спикера. При этом иногда целевой голос был громче («проблеск»), а иногда тише («маскировка»). Исследователи изучали не только то, как мозг реагировал на акустические стимулы, но также и различия в восприятии фонетических признаков. Затем данные ЭЭГ были использованы, чтобы создать прогностические модели активности мозга.
Результаты показали, что существует иерархия в обработке «проблесков» и «маскировки», кодирующихся в слуховой коре. Быстрее всего кодируется акустическая смесь речи говорящих в извилине Гешля — от 70 до 95 миллисекунд. Фонетические признаки речи, которая была громче фона, кодируются как в первичной, так и во вторичной слуховой коре. При этом при кодировании во вторичной слуховой коре большую роль играет фактор внимания, то есть является ли речь целевой, а кодирование «проблесков» в первичной слуховой коре происходит вне зависимости от этого фактора. То есть мозг может улавливать фрагменты нецелевой речи, но только если она громче фона и уровня речи нашего собеседника. «Маскировки» же кодировались только тогда, когда они относились к целевой речи. Кроме того, «проблески» кодировались быстрее, чем «маскировка».
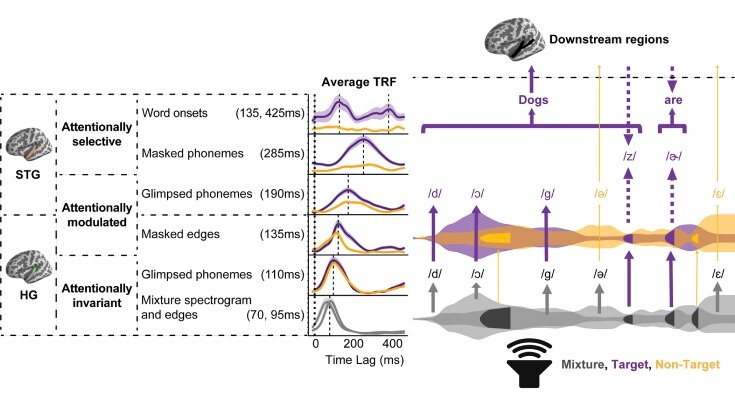
Таким образом, есть четкое разделение между целевой и нецелевой непрерывной обработкой речи. Если мы слушаем кого-то в компании с другими говорящими, то мозг потом восстанавливает те части, которые мы могли пропустить из-за шума. Понимание того, как мозг в окружающем шуме обрабатывает речь, может помочь усовершенствовать работу слуховых аппаратов. Современные технологии, используемые в слуховых аппаратах, либо усиливают все голоса, а не нужный пользователю, либо смешивает их и они становятся неразличимы.
Ранее доктором Месгарани была разработана технология, которая поможет создать слуховые аппараты, которые будут контролироваться мозгом. Алгоритм использовал электрические сигналы мозга, сортировал звуки и усиливал целевой голос и ослаблял другой. Данные его нового исследования могут помочь улучшить системы декодирования слухового внимания для создания слуховых аппаратов, управляемых мозгом.
Ранее N + 1 рассказывал, что ученые создали колхеарный имплант, который оптогенетически стимулирует у крыс слуховой нерв. Свет приводил к возбуждению слуховых центров ствола мозга и глухие животные могли слышать звук и реагировать на него.