Я уже написал некую обзорную научную статью, которая предлагает гипотетическую архитектуру для создания научного ИИ. Далее я опубликую несколько статей, которые популярно раскрывают основные идеи.
Давайте продолжим углубляться в тему того, что любое явление можно математически смоделировать. Даже всевозможные жаргонные понятия в языке. Т.е. можно буквально написать формулу или программу, которая строго кодирует ругательства с конкретными параметрами их грубости, отношения к женскому или мужскому телу, какому-то процессу или даже половой ориентации. Например, если мы говорим о негативной реакции на какое-то событие, то, регулируя параметр “обсценности”, можем начать с “досадно”, где этот параметр будет на нуле, до “блин” и куда более неприличных слов, которые в научной и даже научно-популярной статье употреблять нельзя. Для многих значений этого параметра может даже не быть слова в конкретном языке, но будет некоторый вектор, который формирует понятие. И уже это понятие может быть переведено на нужный язык в рамках его возможностей.

Представьте ситуацию, что у нас есть некоторое понятие “приём пищи”. В зависимости от времени суток наиболее вероятное его название - это “завтрак”, “обед” или “ужин”. В английском языке есть ещё “ланч” и “бранч”. Можно добавить туда какой-нибудь “ночной жор” или типа того. Т.е. мы берём “бедное” контекстом понятие “приём пищи”, регулируем параметр времени суток и получаем разнообразные слова. То слово, которое наиболее близко к заданным параметрам, затем в тексте и используем. Вообще говоря, почти так и работают нейронные сети, предсказывающие следующее слово в тексте. Они угадывают наиболее вероятное слово, не более того.
Понятие как вектор
То, что я пишу, может, не вполне явным образом, но уже сформулировано в работах классиков по развитию больших языковых моделей. Каждое слово или его часть записывается в виде “эмбеддинга” - некоторого вектора с большим числом параметров. Для GPT-3 это порядка 12 тысяч измерений, которые вряд ли получится наглядно изобразить. Но мы можем нарисовать очень упрощённый классический пример на плоскости.
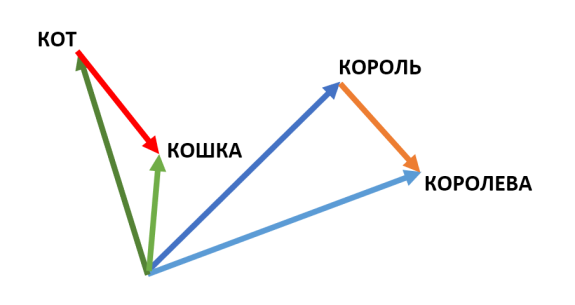
Когда мы сравниваем векторную запись разных слов, мы можем почти явным образом выделить некоторые систематические направления. В примере выше показано, что разница векторов для слов “король” и “королева” примерно равна разнице для слов “кот” и “кошка”. “Примерно” здесь появляется из-за того, что между королём и королевой всё-таки более глубокие различия, чем между котом и кошкой. Да и слово “королева” может быть связано с группой Queen или с британской королевой. Но это уже не относится к чистой семантической разнице между конкретно заданными людьми, которые отличаются только полом. Т.е. это скорее искажения от разнообразных культурных и не только особенностей языка и нашего быта, а также шумов в данных. Для многих прикладных задач нам специфика конкретной страны или группы людей будет не только не нужна, но и вредна. Таким образом мы можем определить ту ось, которая отвечает именно за гендерную принадлежность понятия. Это можно сделать технически. И оно будет работать. Если мы возьмём произвольное понятие, например, “конь”, добавим к нему уже известную по другим парам слов разницу между женской и мужской версиями, то мы можем получить более женственный вариант “лошадь”. Вероятно, из слова “аккумулятор” при таком упражнении может получиться “батарея”, потому что в русском языке аккумулятор мужского рода, а батарея - женского. Это может коррелировать с гендерными признаками, хоть и не является тем, что мы изначально закладывали в понимание пола. А для многих слов нового варианта не найдётся вообще, и наиболее вероятным словом останется исходное.
Разные записи одного понятия
Эту ось можно записать в виде конкретной комбинации из параметров уже известных векторов. Но одну и ту же точку в пространстве можно записать в виде большого числа разных вариантов. Снова, рисуя упрощённый пример, мы можем получить кота условно, как “4 лапы” + “шерсть” + “мальчик” + “вибриссы”. А можем взять отсылку к мультику “Котёнок по имени Гав”, добавить “взрослый” и уточнить, что речь о “заглавном герое”. Мы получим примерно одну точку, которая задаёт понятие “кот”.
Вы спросите, “причём тут наука в целом и эфиродинамика в частности?” Притом, что мы можем определить семантические оси, которые строго отвечают за те или иные характеристики понятий. Именно в науке и технических областях сделать это проще всего.
Нам даже потенциально не нужно переобучать модели. Мы берём уже известные обученные модели, смотрим, как записываются те или иные слова, делаем анализ по парам слов, которые преимущественно отличаются только по заданному критерию, выделяем из их “векторов-значений” ту часть, что отвечает за конкретный критерий и фиксируем её в отдельную переменную. И продолжаем это делать до тех пор, пока исходный вектор не будет близок к нулю. Затем удаляем или существенно “обедняем” старый вектор, убирая почти нулевые параметры, получая разбитый по строго интерпретируемым человеком осям вектор.
Это, конечно, гипотетический пример, который стоит испытать на практике. Но у него определённо есть потенциал. Именно двоякость трактовок и сложность интерпретирования текстов - важнейшие проблемы, стоящие перед большими языковыми моделями. Среди прочих важнейших проблем, конечно.