
Что такое база данных
Давайте вспомним, как раньше учителя вели учёт успеваемости в школах. Обычно они выставляли оценки сначала где-нибудь в тетради, затем переносили её в журнал. И такой журнал был свой для каждого класса. В журнале был список учеников класса, их оценки, пройденные темы и домашние задания по каждому предмету.
Но представим, что школа решила перейти на электронный формат. Нужно завести электронный журнал, где будут собраны все оценки, ученики и предметы. Как этот переход реализовать так, чтобы все данные хранились в удобном и доступном для понимания виде?
На первый взгляд можно было бы сделать одну большую таблицу и туда записывать абсолютно всё: фамилию ученика, дату рождения, предмет, фамилию учителя и оценку. Но очень быстро окажется, что таблица растянулась на сотни строк, и разобраться в ней невозможно.
Например, если мы хотим просто узнать, какие предметы ведёт конкретный учитель, придётся вручную фильтровать огромную таблицу. А если допущена ошибка в написании фамилии ученика, то система будет считать, что это два разных человека. Чем больше данных, тем сложнее поддерживать порядок.
Поэтому данные нужно организовать. Обычно начинают с отдельных таблиц. Давайте придумаем абстрактную таблицу: пусть это будет расписание уроков на понедельник в 11 «А» классе. Наша таблица будет содержать следующие столбцы:
- Название предмета
- Кабинет
- ФИО преподавателя
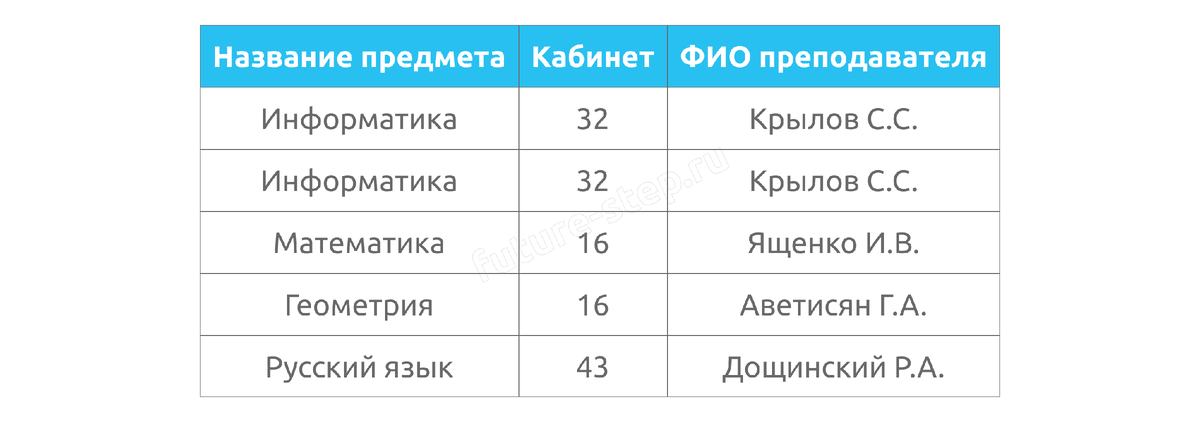
На первый взгляд – всё отлично. Мы видим, какие уроки есть у класса, где они проходят и кто ведёт. Но если взглянуть на таблицу глазами программиста или администратора базы данных, сразу видно проблему: в строках таблицы нет какого-либо уникального ключа, по которому можно было бы отличить, уроки друг от друга.
Почему это важно? Дело в том, что база данных должна уметь однозначно находить нужную запись. Представьте: вы хотите добавить к каждому уроку домашнее задание или поменять кабинет только у второго урока информатики. Как система поймёт, о какой записи речь, если обе выглядят одинаково?
Здесь на помощь приходит ключ. Это специальное поле, в котором хранится уникальный идентификатор каждой записи. Такой идентификатор принято называть ID (сокращение от слова identifier – «идентификатор»). Обычно это число, которое не повторяется в пределах таблицы (автоинкрементное число). С его помощью мы можем отличить даже два абсолютно одинаковых урока.
Давайте придумаем уникальные идентификаторы для нашей таблицы. Числа в наших примерах использовать не будем – с ними легко запутаться, да и в дальнейшем у нас будет несколько таблиц, одними цифрами не обойдёшься.
По-хорошему имя нашего идентификатора должно отражать его суть. Допустим, в таблице мы будем перечислять уроки (lessons), тогда логично будет назвать идентификатор «les-N», где N – номер урока (в реальной таблице мы бы ограничились только числом N).
Теперь всё стало куда понятнее. У каждого урока есть свой ключ, и никакая строка не потеряется.
Пока мы не перешли к более сложным темам, давайте закрепим терминологию, которой будем пользоваться в дальнейшем:
- Каждая база данных состоит из таблиц, в которых хранятся данные. Причем в одной базе данных может быть несколько таблиц.
- Таблицы состоят из записей, которые представляются строками этих таблиц.
- В каждой записи есть поляили же столбцы, которые содержат определённые данные (здесь полями являются «ID», «название предмета», «кабинет» и «ФИО преподавателя»). Причем одно из полей может быть ключом.
- Ключ – это уникальный идентификатор(ID) каждой записи, именно они позволяют связать данные между разными таблицами. В данном примере ключи записаны в первом столбце.
Структуру таблиц принято обозначать в виде такого прямоугольника (цвета и стили могут отличаться):
Сверху написано название нашей таблицы, для примера назовём её «Расписание». Первым полем указывается уникальный идентификатор «ID», который принято выделять среди других полей, например, иконкой ключа. Далее идут поля таблицы, у нас это — «Название предмета», «Кабинет» и «ФИО преподавателя».
Такие прямоугольники используются при построении диаграмм связей между таблицами, и называются они «сущностями», а поля таблиц в них называются «атрибутами». Но об этом мы поговорим немного позже.
Реляционный подход в базах данных
Мы уже разобрались, что данные лучше хранить не в одной гигантской таблице, а в аккуратных и понятных структурах с ключами. Но что делать, если таких таблиц становится несколько?
Очевидно, что они должны быть как-то связаны между собой. Ведь в реальной жизни всё взаимосвязано: ученики ходят на разные предметы, предметы ведут разные учителя, а оценки выставляются каждому ученику отдельно. Вот здесь и появляется реляционный подход.
Реляционный подход – это способ организации данных, при котором информация хранится в таблицах, а сами таблицы связываются между собой с помощью ключей. Слово «реляционный» произошло от английского relation – «связь».
То есть суть подхода в том, что таблицы не существуют поодиночке, они образуют систему, где каждая запись может быть связана с другой через уникальные идентификаторы.
Давайте разберём реляционный подход на примере нашего импровизированного электронного журнала. Заведём таблицу с учениками:
Здесь каждая строка описывает конкретного ученика, а поле «ID ученика» – это ключ, который делает запись уникальной.
Теперь создадим таблицу предметов:
Точно так же здесь у каждого предмета есть свой ID, который однозначно его определяет.
И, наконец, самое интересное – оценки. Их нельзя привязать только к ученику или только к предмету, ведь оценка ставится именно по предмету конкретному ученику. Поэтому создаём отдельную таблицу:
Здесь ключами выступают ссылки: ID ученика и ID предмета. Благодаря им мы понимаем, что по информатике (sub-1) сразу три человека получили оценки: две пятёрки у Селезнёвой Алисы (st-2) и одна четвёрка у Романова Петра (st-1). Также Алиса получила оценку по геометрии (sub-3), а Владимир (st-3) получил четвёрку по русскому языке (sub-4)
В чём удобство такого подхода? Во-первых, мы избегаем дублирования данных. Если бы мы всё записывали в одну таблицу, фамилия каждого ученика и название каждого предмета повторялись бы сотни раз.
Во-вторых, реляционная структура делает данные гибкими. Например, чтобы узнать все оценки Петра, достаточно найти все строки, где ID ученика будет «st-1», и соединить их с таблицей «Ученики».
Таким образом, реляционный подход позволяет хранить данные в отдельных, логически связанных таблицах.
ER-диаграмма
Мы уже видим, что данные в реляционной базе – это не просто набор разрозненных таблиц, а целая система, где всё связано между собой. Но чтобы человеку было проще разобраться в этих связях, используют графическое представление.
Такое представление называется ER-диаграмма (Entity–Relationship Diagram, или «сущность – связь»). Это способ наглядно показать, какие таблицы есть в базе, какие у них поля и как они соединяются друг с другом. ER-диаграммы помогают систематизировать информацию и увидеть всю структуру данных целиком.
Возьмём наш пример с таблицами «Ученики», «Предметы» и «Оценки».
- «Ученики» – сущность, которая описывает каждого школьника (с атрибутами вроде ID, имени и класса).
- «Предметы» – сущность, где хранятся названия дисциплин и преподаватели.
- «Оценки» – сущность, которая фиксирует результат: какой ученик получил какую оценку по конкретному предмету.
Каждая из этих таблиц имеет свой уникальный ключ. Именно через них строятся связи. Например, чтобы узнать, какую оценку Пётр получил по информатике, мы берём его ID из таблицы «Ученики», находим ID информатики в таблице «Предметы», а затем по этим двум ключам ищем строку в таблице «Оценки».
На ER-диаграмме это изображается так: три прямоугольника (сущности), внутри которых перечислены атрибуты. Уникальные ключи выделяются значком ключа или подчёркиванием. Между прямоугольниками проведены линии со стрелками, которые показывают связи: «Ученики» соединены с «Оценками» по ID ученика, а «Предметы» – с «Оценками» по ID предмета.
ER-диаграмма – это не просто иллюстрация. Она используется на этапе проектирования базы данных и помогает проверить, правильно ли продуманы связи, не дублируются ли данные и можно ли эффективно работать с этой системой.
Причём такие диаграммы нужны не только в учебных примерах. Они применяются в реальных проектах: в интернет-магазинах (товары, покупатели, заказы), в банковских системах (клиенты, счета, транзакции), в медицинских информационных системах (пациенты, врачи, приёмы). Везде, где нужно хранить и обрабатывать большие массивы информации, ER-диаграмма помогает навести порядок и выстроить чёткие связи.
Важно понимать: главная сила реляционных баз данных – в связях между таблицами. Эти связи строятся по ключам. В реальной жизни ключами могут быть номера транзакций, артикулы товаров, номера магазинов, ID сотрудников – любые значения, которые уникально описывают сущность.
Так как в реляционных базах данные разнесены по разным таблицам, нам нужно уметь «собирать» их вместе, чтобы получить цельную картину. Делается это именно через уникальные ключи: они позволяют переносить и объединять данные из разных таблиц.
Для этого используются специальные инструменты и функции. Например, в редакторах электронных таблиц существует функция ВПР() (вертикальный поиск), которая ищет нужное значение в одной таблице и возвращает связанный с ним результат из другой. Но об этих приёмах мы поговорим уже в следующей статье.