Предыдущая часть:
Когда я её начинал, то думал, что это простой пример. И совсем не ожидал, что открою банку с червями, как говорят американцы.
Поэтому весь выпуск будет исключительно про
Unicode
Само название Unicode это не кодировка, а таблица кодов для всех-всех символов.
Эта таблица отображается уже на конкретные кодировки:
- UTF-32 – кодировка с фиксированной длиной символа в 4 байта (32 бит). В неё напрямую отображается вся таблица Unicode, так что работа с ней получается простая как палка, но строки в такой кодировке будут занимать много места.
- UTF-16 – кодировка, аналогичная UTF-32, с фиксированной длиной символа в 2 байта (16 бит). Пользоваться ею в целом так же просто, а занимает места она в 2 раза меньше. Но есть нюанс: в ней, естественно, может поместиться только 64K символов. Этого хватает на все основные алфавиты (русский, арабский, китайский и т.п.), но уже не хватает на всякие эмодзи (будь они прокляты). Поэтому расширенные коды состоят из 4-х байт, и при работе со строками нужно проверять кое-какие краевые условия.
- UTF-8 – кодировка с плавающей длиной символа от 1 до 4 байт. Она самая экономная, так как символы не занимают больше места, чем нужно. Вторым её достоинством является то, что однобайтные символы совпадают с ASCII-кодировкой. То есть обычный текст в ASCII совместим с UTF-8. Недостатком же является то, что длину каждого символа надо проверять, а также то, что хранимые коды символов из-за префиксов длины не совпадают с табличными Unicode.
Какие проблемы?
Чтобы прочитать слово из консоли, я использую функцию fgets() с потоком stdin. Но как внезапно оказалось, при использовании ввода с клавиатуры из командной строки Windows русские символы приходят как нули.

Сама функция fgets() и сам поток stdin не виноваты: fgets() отлично читает Unicode-строки из файла, а если файл перенаправить в stdin, то отлично читает и оттуда.
Windows, как сообщают, использует внутри себя кодировку UTF-16, хотя в консоли у меня используется UTF-8 (это легко выяснить, запустив команду chcp). Вероятно, в самом консольном приложении cmd есть какой-то баг, приводящий к сбою преобразования кодировки, и в stdin поступают уже испорченные данные.
Проблема именно в Windows, потому что встречается и в других программах, написанных на Python и Rust. В Linux этой проблемы нет.
#include <windows.h>
Несмотря на увлекательные поиски, универсального кроссплатформенного решения не получилось. Придётся использовать специфические функции Windows.
Базовый код:
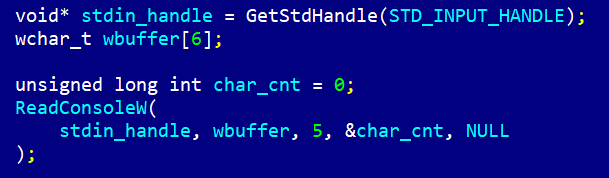
С помощью функции GetStdHandle() мы получаем какой-то специальный микрософтовский указатель на поток ввода stdin. Далее используем буфер с типом wchar_t, это тип для "широкого" символа (в нашем случае 2 байта). И читаем в этот буфер с помощью ReadConsoleW(). Один плюс – хотя бы количество прочитанных символов можно получить сразу в виде char_cnt.
Для переносимости этот код надо будет сделать условно-компилируемым с помощью директив препроцессора, но сейчас я разрабатываю под Windows, поэтому пока будет как есть.
Попутно можно сделать вот что:
Программа может хранить слова и манипулировать ими в своей собственной внутренней кодировке. Например, буква A = 1, буква Б = 2 и т.д. Тогда работа со словами не будет зависеть ни от каких внешних условий.
Извне данные могут приходить в любой кодировке. Если мы находимся в Windows, то получим слово в UTF-16, а если в Linux, то в UTF-8. Следовательно, нужно создать некий слой, который будет нормализовывать слово во внутреннее представление, с которым можно работать единообразно.
Так как меня интересуют только русские буквы, я попросил DeepSeek составить таблицу кодов русских букв в кодировке UTF-16:
Как видно, они находятся в диапазоне кодов 1040-1103 и расположены последовательно, за исключением букв 'Ё' и 'ё'. По правилам игры эти буквы нужно заменять на 'Е', так что мешать они не будут.
Значит, можно банально выполнить приведение одного диапазона кодов в другой. Заодно можно проверить корректность слова, так как оно должно содержать только русские буквы.
Также нам не надо отличать заглавные и строчные буквы. Какие бы пользователь ни ввёл, мы преобразуем их во внутреннее представление, где 'A' и 'а' это одно и то же.
Функция преобразования из UTF-16:
Возвращаемая сущность InputWord (описана в первой части) это не просто строка, но уже нормализованное слово для использования в игре. Читая буфер, мы проверяем значение на выход из диапазона 1040-1103. Если выходит, то это некорректная буква (включая 'Ё'). Тогда обнуляем первый байт в input.letters, таким образом создавая признак пустой строки, и возвращаем результат.
А если проверка прошла, то приводим значение к верхнему регистру (если оно больше 1071, то отнимаем 32), затем отнимаем от него 1039 и получаем уже свой диапазон 1-32 (без буквы 'Ё'). В таком виде и сохраняем значение в input.letters.
Меняем функцию get_word() на Windows-вариант:
Здесь происходят некие манипуляции с длиной буфера, которые надо пояснить. Всего нам нужно прочитать LETTER_CNT = 5 букв. Когда пользователь введёт 5 букв и нажмёт Enter, в строку также добавятся два символа "\r\n". И наконец, последним символом всегда будет вставлен 0. Поэтому в идеальном случае, когда пользователь ввёл ровно 5 букв и нажал Enter, нам нужен размер буфера LETTER_CNT + 3. А читать мы должны не LETTER_CNT, а LETTER_CNT + 2 символов, чтобы "\r\n" тоже попали в буфер. Они нам не нужны, но так мы прочитаем буфер без остатка за один раз (если введено корректное слово).
ReadConsoleW() заполняет счётчик прочитанных символов char_cnt. Ровно в позиции этого счётчика в буфере будет конец строки, а перед ним – символ '\n'. Поэтому проверяется wbuf[char_cnt - 1]. Если такой символ нашёлся, буфер прочитан полностью.
Если же нет, мы читаем повторно, увеличивая счётчик read_cnt и перезаписывая старое содержимое буфера. Оно нам уже не нужно, так как введённое слово уже заведомо длиннее, чем требуется.
Мы проверим счётчик считываний read_cnt, и если он больше 1, значит можно возвращать признак ошибки.
Функция from_utf16() заполняет ровно LETTER_CNT букв из буфера. Поэтому, если пользователь ввёл меньше, в буфере окажутся "\r\n", до которых перебор обязательно дойдёт и вернёт признак ошибки, так как это не русские буквы. Так что и от коротких слов защита есть.
Получение слов из хранилища
Ранее я разместил набор слов непосредственно в программе:
Наконец-то можно заменить слова на русские:
Они заданы в кодировке UTF-8, как и вся программа.
Будем пока считать, что массив слов это как бы внешний файл, а нужно получить новый массив с нормализованными словами. Для них я сделаю массив из структур InputWord, так как данная структура уже используется для нормализованного представления слова (вероятно, надо будет её переименовать):
InputWord dict_words[10];
Чтобы преобразовать символ из UTF-8, нужно сначала получить его Unicode-код, а потом этот код преобразовать как раньше, через дипазоны:
Здесь мы читаем по умолчанию 2-байтные символы типа wchar_t из буфера (все русские буквы 2-байтные), но преобразование из UTF-8 не тривиально, вот эта часть:
Сначала необходимо по младшему байту символа определить, что он действительно является двухбайтным кодом. Для этого три старших бита (по маске 0xE0) должны быть равны 110 (0xC0).
Если символ не двухбайтный, то дальше проверять смысла нет – возвращаем пустую строку.
Дальнейшие манипуляции получают из двух байт UTF-8 два байта UTF-16. Их опишу позже, потому что история с ними ещё продолжится.
Теперь преобразуем все слова из условного "входного файла" в наш внутренний список:
Заодно проведём и валидацию внешних данных. Если в них что-то не так, можно остановить программу (за это отвечает переменная result).
Вывод слов в консоль
Так как слова теперь хранятся во внутреннем представлении, вывод их в консоль не даст результата. Перед выводом их нужно преобразовывать в кодировку UTF-8.
Кстати, а почему ввод в UTF-16, а вывод в UTF-8?
Выводить будет проще, чем вводить. Можно просто использовать lookup-таблицу для прямого преобразования внутреннего кода в готовый к употреблению UTF-8. Ещё раз помогает DeepSeek:
Здесь только заглавные буквы и закомментирована буква 'Ё', так как все слова во внутреннем представлении нормализованы.
Можно также использовать lookup-таблицу для UTF-16, или просто прибавлять 1039 к внутреннему коду и получать из него UTF-16. А затем этот UTF-16 преобразовывать в UTF-8. А зачем, если есть первый способ?
Действительно, незачем, поэтому используем первый способ, а преобразование я допишу в конце статьи как бонус.
Функция вывода:
Создаём временный буфер достаточной длины, переносим в него коды, не забываем поставить нулевой байт в конце, и можно выводить.
Проверка работы
Введённые слова нормализуются, выводятся на печать и проверяются успешно. Далее нужно будет сделать:
- Чтение тысяч слов из файла
- Проверку слова на корректность и на существование, с соответствующим изменением логики интерфейса пользователя
- Обещанную доработку функции has_letter()
- Возможность компиляции под Linux
Полный текст программы:
Бонус про перекодировку UTF-8
Если присмотреться к списку кодов UTF-8, то можно убедиться, что просто отнять-прибавить диапазон, как в UTF-16, там нельзя. Коды идут не по порядку. Но если присмотреться сильнее, то можно увидеть, что старшие байты кодов идут по порядку: 0x90**, 0x91**, а младшие равны D0.
Значит, поменяв местами байты, можно всё-таки получить упорядоченный диапазон. Почему тогда мы не воспользовались этим в from_utf8(), вместо этого выполняя другие манипуляции? Данный диапазон будет работать только для заглавных букв. В строчных коды меняются, нарушая порядок. Так что простого решения всё равно не выйдет.
Давайте разбираться c перекодированием на примере русской буквы 'A' с десятичным Unicode-кодом 1040.
Значение UTF-8 содержит тот же код, но хранится он специальным образом.
В младшем байте UTF-8 три старших бита тратятся на признак 2-байтности: 110. В этом байте остаётся 5 свободных бит.
Во втором, старшем, байте два бита тратятся на признак того, что это не начальный, а продолжающий байт: 10. Остаются свободными 6 бит.
И вот в эти свободные 5+6 бит нам и надо вписать число 1040.
Наглядное представление шаблона двух байт UTF-8 с подготовлеными префиксами:
10----- 110-----
А вот двоичное представление числа 1040:
0000010000010000
Оно по факту 11-битное:
10000010000
Младшие 6 бит числа поместим в старший байт UTF-8:
10000 [010000] -> 10 [010000] 110-----
Старшие 5 бит числа поместим в младший байт UTF-8:
[10000] 010000 -> 10010000 110 [10000]
В результате получился код:
10010000 11010000
Который в 16-ричном виде равен 0x90D0, что совпадает с UTF-8 кодировкой буквы 'А'.
При обратном преобразовании надо взять младшие 6 бит из старшего байта и спозиционировать в младшие 6 бит числа-приёмника:
10 [010000] 11010000 -> 0000000000 [010000]
И надо взять младшие 5 бит из младшего байта и спозиционировать их слева от младших 6 бит числа:
10010000 110 [10000] -> 00000 [10000] 010000
Итого получаем 0000010000010000 или наш исходный Unicode-код 1040.
В функции from_utf8() этим и занимается строка
wc = ((wc >> 8) & 63) | ((wc & 31) << 6);
Для кодов длиной 3 и 4 байта процесс будет аналогичен, только манипуляций будет больше. К счастью, это пока не нужно.
Читайте дальше: