Пришла в голову идея написать игру на C в целях обучения. Довольно простая задача, что и надо для новичков. И возможна реализация на нескольких уровнях – от самого примитивного до продвинутого.
Правила игры
Загадано русское слово из 5 букв. Игрок вводит своё слово из 5 букв. Буквы в этом слове могут:
- Отсутствовать в загаданном слове
- Присутствовать в загаданном слове, но не на своём месте
- Присутствовать в загаданном слове на своём месте
Каждая буква обозначена соответствующим образом. Игрок, глядя на них, может сделать несколько повторных попыток, пока не отгадает слово или попытки не закончатся.
Начинаем
Сначала определимся с необходимыми константами. Они нужны, чтобы потом не переделывать 5 на 6 или 10, когда мы захотим изменить правила игры. Объявим константу LETTER_CNT, равную 5. И пока, наверное, всё.

Хранение слов
Далее нужно организовать хранилище слов. Лучше всего сделать это в файле, который программа будет читать. Прикинем объёмы. В русском языке около 200 тысяч слов, из них существительных существенно меньше, из них 5-буквенных существительных ещё меньше, и наконец, таких существительных, которые можно использовать в игре (не имя собственное, не географическое название и т.д.), ещё меньше.
Но даже 200 тысяч легко поместятся в памяти, так что тут можно не волноваться. Файл пока читать не будем, это тривиально, а для быстрого старта разместим в статической памяти массив из нескольких слов. Его будет достаточно для отладки.
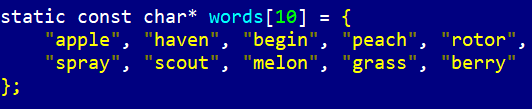
Стоп, почему слова не русские? Это обсудим позднее.
Напишем выбор случайного слова из массива:
Функция get_random_word() принимает два аргумента: указатель на массив слов words и количество слов word_cnt (так как язык C не может самостоятельно определить размер массива по указателю).
Случайный индекс rand_index находим простой пропорцией, умножая диапазон доступных индексов (word_cnt - 1) на отношение rand() / RAND_MAX. Результат округляется до целого автоматически.
Хоть массив words и объявлен статически и функция может иметь к нему доступ напрямую, мы тем не менее передаём в функцию указатель на массив, чтобы можно было впоследствии подменить его на любой другой.
Так как C опасный язык,
использование модификатора const для char* поможет нам оградить себя от случайной перезаписи содержимого указателей. Ведь мы не планируем изменять список слов.
Теперь можно написать простой тест в основной программе:
Функция srand() засевает генератор случайных чисел случайным стартовым значением. В данном случае используется значение текущего времени time(NULL). К сожалению, засев происходит некачественно, и поэтому дополнительно я использовал операцию XOR со значением идентификатора запущенного процесса getpid(). Тоже не особо хорошо, но пока сойдёт.
Проверка слова
Программа должна каким-то способом получить слово от игрока. Способов может быть куча. Важно то, что процесс получения слова не должен влиять на остальное.
Поэтому сделаем сразу функцию проверки, как будто слово уже есть. Но сначала надо понять, что должна возвращать эта функция. Каждая буква в пользовательском слове может находиться в одном из трёх статусов: её нет, или она есть не на своём месте, или она есть на своём месте.
Так что по идее функция должна вернуть совокупность статусов для всех 5 букв, иначе говоря массив.
Но функция не умеет возвращать массив фиксированной длины, поэтому сделаeм структуру, которую можно вернуть, и заодно определим константы перечисляемого типа для статусов букв:
В структуру WordStatus также добавим поле ok_cnt для подсчёта букв, стоящих на своих местах.
И напишем функцию проверки слова:
Будем получать по одной букве из загаданного и введённого слова и сравнивать их. Для этого я использую функцию get_letter(), которая ещё не написана. Если буквы совпадают, значит буква стоит на своём месте. Записываем соответствующий статус в результат и увеличиваем счётчик ok_cnt. Если буквы не совпадают, ищем букву в загаданном слове с помощью функции has_letter(), которая тоже ещё не написана. И наконец, если ничего не нашлось, записываем статус NO_LETTER.
Вот как выглядит функция has_letter():
Она просто перебирает буквы в слове, пока не встретит нужную. Сразу отмечу, что данная функция может работать некорректно, если в слове есть повторяющиеся буквы, но к этому вернёмся потом.
Для перебора букв она также использует функцию get_letter():
Она просто возвращает байт из строки по индексу. Тут пора вспомнить, зачем слова задавались на английском.
Дело в наличии разных кодировок символов на разных системах. Например, у меня сейчас в системе кодировка UTF-8. Если я введу строку с клавиатуры, я получу её в кодировке UTF-8. В то же время строки для хранилища слов я могу сохранить в другой кодировке – это в свою очередь зависит от настроек текстового редактора, в котором я редактирую программу.
Чтобы строки можно было сравнивать, нужно, чтобы все они были в одинаковой кодировке. Например, если я отредактировал и скомпилировал программу в кодировке Windows-1251, а ввёл слово в кодировке UTF-8, то нужно слово преобразовать из UTF-8 в Windows-1251, или наоборот.
Я редактирую программу в UTF-8, поэтому всё совпадает. Но тогда есть другой нюанс – символы в UTF-8 могут занимать от 1 до 4 байт. И нужно писать специальную функцию get_letter(), которая это учитывает. Текущая версия функции читает только один байт, а это возможно только с латинскими символами.
Итого, я пока с помощью английских слов ограничил кодировку так, чтобы она была однобайтной (т.е. совпадала с обычным ASCII-кодом), а с помощью функции get_letter() изолировал получение символа. В дальнейшем надо будет только переписать get_letter(), не трогая остальную программу. А пока на том, что есть, надо отработать проверку слова.
Собственно проверка уже сделана, и надо только организовать ввод слова. Памятуя о том, что слово может быть получено любым способом, изолируем ввод в функции get_word():
Как видите, я её не дописал, потому что надо кое-что обсудить. Функция должна вернуть введённое слово, но для этого ей нужен буфер, куда поместить это слово. Буфер мы передаём в качестве аргумента-указателя char* buffer. Это, можно сказать, типичное решение для чёткого, дерзкого и опасного C, но я хочу от него уйти, так как оно "академически" неправильно – функция модифицирует собственный аргумент, а не возвращает самостоятельный результат.
- Функция могла бы создать внутри себя массив и вернуть указатель на него, но так не сработает, потому что массив будет расположен на стеке и потеряется после возврата из функции.
- Функция могла бы выделить память через malloc() и вернуть указатель на неё. Это бы сработало, так как выделенная память была бы уже не на стеке, но тогда пришлось бы следить за её освобождением.
- Функция могла бы использовать глобальную переменную, что в данном случае допустимо, но тоже "академически" неправильно.
Поэтому я сделаю так, чтобы функция выделяла память на стеке, но возвращала её не через указатель, а через копирование. Иначе говоря, память будет просто скопирована из участка стека функции в участок стека основной программы.
Но так как функция не может вернуть массив фиксированной длины, опять воспользуемся помощью структуры:
Она содержит массив длиной LETTER_CNT + 1, чтобы хранить нужное количество букв и завершающий нулевой байт строки.
Теперь функция может возвращать результат не в виде указателя, а в виде копируемого значения:
Мы читаем строку с помощью fgets() из консольного потока stdin, ограничивая её по длине, чтобы не вызвать переполнение буфера. Таким образом, сколько бы символов ни ввёл пользователь, прочитаем мы максимум LETTER_CNT + нулевой байт.
К нашему неудобству, пользователь может ввести слово из более чем 5 букв, а мы прочитаем только 5. Тогда все символы, которые мы не прочитали, останутся в stdin и будут прочитаны в следующий раз, что нам совершенно не нужно. Поэтому после чтения слова stdin нужно очистить от оставшихся символов.
Понять, что они там остались, не очень просто. Например, пользователь ввёл слово из 5 букв или меньше. Мы их все прочитали, и больше не осталось. Тогда, если мы пойдём читать оставшиеся символы из stdin, а там пусто, функция fgets() зависнет в ожидании, когда они там появятся.
Решается это так: fgets() возвращает строку тогда, когда пользователь нажал Enter. Символ переноса строки также попадает в прочитанную строку. Поэтому, если строка содержит в конце символ '\n', все данные прочитаны. Если нет, надо читать оставшиеся.
Чтобы проверить строку на наличие символа '\n' в конце, надо узнать длину строки с помощью функции strlen() и отнять от неё 1, чтобы получить индекс последнего значащего символа строки.
Осталось вывести результат.
Отдельной функцией сделаем отображение статуса букв:
Для каждого значения статуса буквы назначим свой символ: 'x' это нет буквы, '-' это буква не на своём месте, '+' это буква на своём месте.
Напечатаем сначала введённое слово, а затем под ним выведем символы статуса букв.
Видим, что буквы a, p отсутствуют, а буквы l, e стоят не на своих местах. Наверное, это melon, но программа уже закончилась. Нужно организовать цикл из, например, 6 попыток:
И можно попробовать играть:
Я отгадал слово со второй попытки, но игра предлагает третью. Нужно добавить проверки на проигрыш и выигрыш. И обернём всю логику в ещё один внешний цикл, чтобы можно было играть повторно:
Это бесконечный цикл while(1), но выйти из него можно, нажав Ctrl+C.
Лог игры:
Тeкст программы:
Что дальше
Прототип работает. Дальше нужно:
- Переделать функции сравнения слов, чтобы они поддерживали кодировку UTF-8
- Увеличить количество слов и сделать для них внешнее хранилище
- Сделать проверку на существование слова. Сейчас пользователь может ввести что угодно. Программа от этого не сломается, но она должна предупредить пользователя, что такого слова не существует (в её словаре), и не засчитывать попытку.
- Функция has_letter() может работать некорректно для повторяющихся букв, её надо исправить.
Всё это сделаем в следующей части.
Читайте дальше: