Предыдущая часть:
Когда пользователь вводит слово, нужно проверить, есть ли оно в базе, чтобы он не вводил всякую белиберду.
Базы слов русского языка в интернете найти можно, но везде есть какие-то косяки или неудобства. Ну да ладно, какую-то базу я получил, обработал её, и пятибуквенных существительных там оказалось порядка четырёх тысяч.
Совершенно очевидное решение это взять введённое слово и последовательно сравнить со всеми в базе. И это не будет стоить практически ничего, это можно смело сделать и забыть.
Но о чём тогда тут писать? Я возьмусь за более продвинутый вариант, который должен работать быстрее, хотя разницу на таком количестве слов мы увидим только лишь в массированных тестах.
Дерево
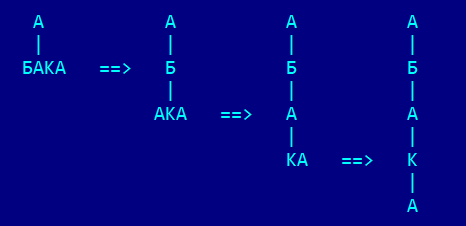
Можно построить такое дерево: берём первую букву первого слова и делаем её корневым узлом. Все оставшиеся буквы слова принадлежат этому узлу, но в свою очередь из них тоже можно построить дерево, и продолжать так до тех пор, пока оставшихся букв не останется.
Например, слово АБАКА транслируется в дерево:
Теперь добавим в уже существующее дерево слово АББАТ.
Первая буква А уже есть в дереве, поэтому мы спускаемся от неё на уровень ниже и добавляем ББАТ. Вторая буква Б тоже есть в дереве, поэтому от неё спускаемся ниже и добавляем БАТ. Так как там есть только ветка 'А', то достраиваем к её родителю ещё одну ветку 'Б' и от неё достраиваем 'AT':

Такое дерево мы получим после добавления слов АБВЕР, АБЗАЦ, АБОРТ, АБРЕК, АБРИС, АБХАЗ, АБЦУГ:
В узле второго уровня 'Б' дерево расходится на 8 веток, а в узле третьего уровня 'Р' ещё на две.
Как происходит поиск по такому дереву: берём первую букву слова и ищем узел верхнего уровня с этой буквой. Найдя узел, берём вторую букву слова и ищем её среди потомков найденного узла. И так далее, пока не найдём все буквы.
Итого, у нас 32 буквы (без 'Ё'), это 32 возможных корневых узла, каждый из которых может содержать по 32 дочерние ветки, и таких уровней вложенности 5. Сам поиск может осуществляться перебором, то есть по 32 операции сравнения на каждом уровне, тогда предельное количество операций будет 32*5 = 160. Если сравнить с обычным поиском, где перебор может занять несколько тысяч попыток, это значительная разница.
Хранение данных
Основная проблема в реализации данного дерева на C это хранение данных. Ведь узлы дерева могут содержать разное количество веток, а разное количество веток будет занимать разное количество памяти.
Можно было бы для каждого узла зафиксировать память под 32 ветки. Но тогда общее количество узлов будет 32^5 = 32 мега...штуки. И большая часть из них не будет использоваться.
Здесь нужна коллекция с динамически изменяемым размером, чтобы мы могли хранить только те элементы, которые используются.
Но в C мы не можем просто взять и применить какой-нибудь хэшмап или список. Ну, вообще конечно можем, взяв стороннюю библиотеку, но здесь суть в том, чтобы сделать самостоятельно, как в анекдоте про танкистов и фею.
Я буду использовать в качестве коллекции связный список. Тогда в одном узле дерева можно хранить ровно один элемент связного списка, размер которого известен. Если же надо добавить ещё элементов, то пожалуйста – это же связный список, надо просто связать один элемент и ещё один. А сами элементы будут храниться где-то в одном общем на всех хранилище.
Сначала я опишу структуру узла дерева:
Это будет элемент списка, у которого есть код символа code, ссылка на соседний элемент next_index и ссылка на дочерний элемент sub_index. Связный список получается как бы двумерный. Можно перерисовать предыдущую диаграмму с использованием таких элементов:
Здесь горизонтальными чёрточками показаны ссылки на соседей (next_index), а вертикальными – ссылки на потомков (sub_index). И видно, что местами эти чёрточки никуда не ведут, то есть ссылок нет.
Под ссылкой я имею в виду не указатель и не ссылку из C++, а просто информацию, по которой можно найти элемент. В данном случае это будет его индекс в общем масссиве.
Теперь можно просто выделить объём памяти под оценочно-максимальное количество элементов. И когда требуется добавить новый элемент, брать его из этого объёма. Где конкретно он там будет лежать, неважно, так как все элементы в дереве связаны ссылками.
Менеджер узлов дерева
Сделаем для удобства несколько функций для работы с узлами дерева.
Во-первых, структура менеджера:
Тут просто счётчик элементов cnt и указатель mem на общую память, выделенную через malloc(). Я также завёл две константы: DICT_NODE_CNT это оценка максимального количества узлов дерева, нужная для выделения памяти, а DICT_NIL это значение для несуществующих ссылок. Дело в том, что я буду оперировать не указателями на элементы, а их индексами. Для указателей можно было бы возвращать NULL в случае ошибки, но для индекса нельзя вернуть 0, потому что индекс 0 вполне себе существует. Поэтому константа DICT_NIL будет возвращать несуществующий индекс, равный максимальному количеству узлов. Собственно NIL значит Not In List, то есть индекс не в списке.
Функция для проверки, что дерево пустое:
Ничего сложного, просто делаем удобно.
Функция, инициализирующая структуру элемента списка:
Тоже для удобства. Ссылки первично инициализируются несуществующими значениями.
Функция, получающая элемент списка по индексу:
В случае, если элемент не найден, возвращается пустой элемент с кодом 0.
Функция, обновляющая элемент списка по индексу:
Функция, выделяющая память под новый элемент и возвращающая его индекс:
Здесь просто увеличивается счётчик, он же текущий индекс в хранилище элементов.
Теперь можно перейти к функции добавления слова в дерево, но сначала рассмотрим функцию поиска, так как она работает аналогично, но попроще.
Первым делом: если дерево пустое, сразу возвращаемся.
Затем начинаем искать с индекса 0. Это всегда первый добавленный элемент, и всё остальное добавлено после него.
Получаем узел по индексу и получаем первую букву слова. Есть два варианта:
- Код узла совпадает с буквой слова. Тогда мы сдвигаемся на следующую букву слова (i++) и переходим на нижележащий узел через sub_index.
- Код узла не совпадает с буквой слова. Тогда мы с переходим на соседний узел через next_index.
При попытке перехода на sub_index или next_index, если эти ссылки не существуют, значит мы перебрали все варианты и дальше искать нечего.
Если i в процессе сравнялось с LETTER_CNT, значит и перебор букв слова мы тоже завершили, и значит, оно найдено.
Добавление работает так же, только ещё заполняет дерево:
Когда мы достигаем узла, который никуда не ведёт, а буквы в слове ещё остались, то эти буквы мы добавляем либо как соседа текущего узла, либо как его потомка.
Функция для добавления оставшихся букв:
Она добавляет узел для первой оставшейся буквы и запоминает его индекс. Затем потомками к этому узлу добавляет остальные буквы. И возвращает индекс первого узла, то есть можно сказать индекс всего добавленного поддерева. Этот индекс затем используется, чтобы прицепить это поддерево к предыдущему узлу.
Тут опущены некоторые проверки на корректность, чтобы не зашумлять код. Например, после каждого dict_node_allocate() надо проверять, не вернулась ли ошибка, и т.п.
Cчитывание файла я сделал, запрос слов сделал, можно вводить слова и проверять, существуют ли они. Полный листинг здесь:
Это пока не сама игра, а отдельная программа. А вот здесь список слов:
Проверка работы:
Далее надо будет доработать определение наличия буквы в слове (уже третий раз откладывается) и свести все доработки вместе.
Читайте дальше: