
Вот вроде бы XXI век разменял третий десяток, космические корабли бороздят межпланетное пространство, повсюду цифровизация, нейросети и социальные рейтинги, а информационной системы, в которой можно было бы смотреть статистику ЕГЭ, не существует. Москва вообще ничего не показывает, - то ли потому, что плохо, то ли потому, что слишком хорошо по сравнению с остальной страной. Некоторые регионы публикуют отчеты по стандартной форме. В принципе, достаточно подробные, но как же неудобно с ними работать! Единственный регион, в котором продемонстрировали, как должно быть, - Костромская область. Очень боюсь, что им запретят это делать, чтобы не дискредитировали всех остальных.
(Даже Росстат, мягко говоря, не поражает воображение разными визуализациями, и выкладывает архаичные таблички в Excel. Но у Росстата хотя бы цифры в открытом доступе есть. А с ЕГЭ - сплошное блаженное неведение.)
Можно ли посмотреть распределение баллов за каждый год в виде таблицы: первичный балл - процент участников? В методических рекомендациях по профильной математике за 2022 г. (Ященко, Высоцкий, Семенов) приведена такая диаграмма.
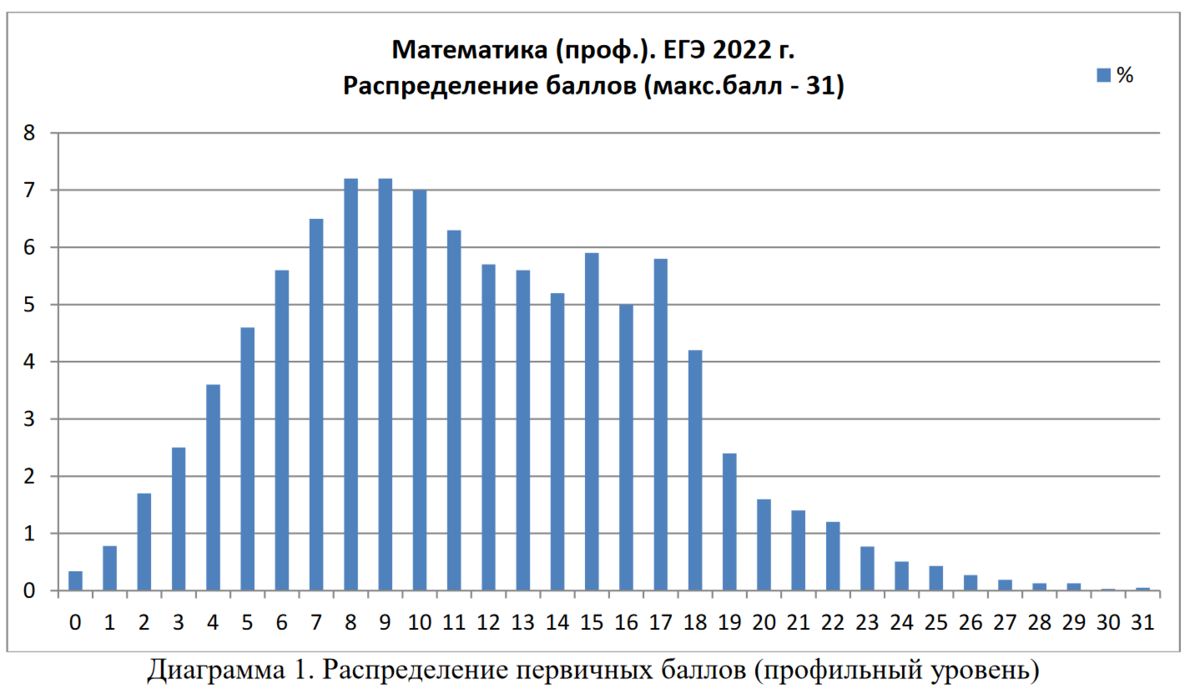
Попытаемся добыть таблицу, по которой она построена. Эта задача сильно упрощается благодаря тому, что графика векторная (что легко увидеть, изменяя масштаб). Извлекать векторную графику из pdf файлов умеет, например, бесплатная программа Inkscape. В ней лучше открыть только страницу с изображением.
Выделяем область с прямоугольниками, копируем в отдельный документ, сохраняем в формате svg. Открыв файл в Блокноте, увидим следующее:
За отрисовку прямоугольников отвечает свойство тега path, которое работает примерно так же, как это делалось еще во времена графопостроителей юрского периода (и делается в PostScript по сей день). Это последовательность команд: переместиться в точку с заданными координатами (m), нарисовать вертикальную или горизонтальную линию (h,v), замкнуть контур (z). Команд на самом деле больше, можно использовать сплайны, но нас, слава богу, это сейчас не интересует.
Казалось бы, дело в шляпе. Достаточно вытащить из строки числа, которые идут после команды v, и мы узнаем длины вертикальных сторон.
Это можно сделать рабоче-крестьянским методом, посимвольно читая строку. Но знакомство с основами веб-программирования и применениями языка питон (пайтон и т.п.) подсказывает, что данная задача решается в народном хозяйстве при помощи регулярных выражений (см., например, статью на Хабре).
Но если столбцы проиндексированы от 0 до 31, то их должно быть 32? В чем дело? Оказывается, какая-то... программа для надежности вставила в середине несколько команд, в которых указаны абсолютные координаты (заглавные буквы V,H), а не относительные (строчные буквы v,h).
Да, не повезло. Но это же не заставит нас шевелить мозгами сверх меры и моделировать все перемещения графического курсора? Конечно, нет. Находим библиотеку питона, которая читает строку path и выдает координаты точек. Она называется svg.path.
Координаты точек на рисунке здесь комплексные, разработчику так больше понравилось. В самом деле, почему бы и нет, если в питоне это встроенный тип? Вполне удобно.
Нас интересуют команды с номерами 3, 8, 13 и т.д., которые рисуют вертикальные линии.
Осталось поделить на сумму и умножить на 100, чтобы получились проценты.
Округляя до 3 знаков, получим такой массив (процент участников, первичный балл от 0 до 31):
[0.340, 0.782, 1.703, 2.506, 3.607, 4.605, 5.608, 6.509, 7.214, 7.214, 7.013, 6.308,
5.711, 5.608, 5.207, 5.912, 5.006, 5.809, 4.209, 2.403, 1.600, 1.405, 1.204, 0.772, 0.509, 0.432, 0.273, 0.190, 0.129, 0.129, 0.031, 0.051]
Сравним суммы по диапазонам с таблицей:
По нашим данным должно быть 13.542, 26.545, 24.641, 32.755, 2.516. Наибольшее расхождение - в группе от 14 до 22 первичных баллов (0.25%). В принципе, приемлемая точность.
Чтобы окончательно убедиться, возьмем чрезвычайно любопытную таблицу, в которой приведены доли участников, набравших определенный балл за каждое задание (очень жаль, что нельзя сравнить с данными за предыдущие годы).
Интересно, сколько участников получится, если взять цифры из верхней строки и просуммировать? 26860+134369+120011+19943 = 301183, чуть меньше, чем по данным Рособрнадзора (называли 302 тыс.). Но это, конечно, пустяки...
Здесь доля двоек 26860/301183 = 0.08918, а извлечение данных из диаграммы дало 8.937%. Достаточно точно, и по остальным группам расхождение не более 0.1%. Заодно мы проверили, что в ФИПИ строили столбчатую диаграмму по тем же данным, по которым посчитаны таблицы (возможно, с небольшими погрешностями). А то всякое бывает, знаете ли.
Вот такой ерундой приходится заниматься, чтобы узнать цифры, которые изначально должны быть достоянием общественности. Как и данные для сравнения уровня по регионам, которые вам, дорогие друзья, стараются показывать очень избирательно и по отдельности. Но когда-нибудь мы до них доберемся.
Как говорится, кто ищет - тот доищется.
(В конце оставлю блокнот Colab на тот случай, если кому-то покажутся полезными использованные приемы.)