Для планирования работ по оперативному мониторингу важно понимать как объем влияет на размер команды. Иными словами, должен быть готов обоснованный ответ на вопрос: "Как должна измениться команда, при увеличении объема на N каких-то единиц". Этой статьей я открою серию, где поделюсь различными методиками подсчета, на основе которых каждый затем сможет составить для себя наиболее подходящую, или разработает несколько, работающих хорошо в определенных сценариях. В статье я приведу расчет ответа на вопрос: "Какой объем мониторинга может обработать текущая команда".
Что касается единиц объема, то в MDR с этим очень просто: мониторятся 2 системы - эндпоинт (EPP, endpoint protection platform) и комбайн KATA, но единицей объема является конечная точка, так как нередкий сценарий - использование EPP без KATA, а если KATA есть, то расследование ее срабатываний все равно проводится по телеметрии от конечных точек. При более широком перечне источников событий рассчитать трудоемкость работы с ними несложно, имея статистику хотя бы за пару месяцев (зависит от частоты срабатываний соответствующей системы обнаружения, но в большинстве случаев статистики за год должно хватить): как часто возникают алерты, какова средняя продолжительность работы над алертом (если разные типы алертов имеют разную трудоемкость обработки, то надо иметь данные об ожидаемой частоте возникновения каждого типа алертов), какова их конверсия в инциденты и как много времени уходит на оформление и работу над инцидентом. Кроме предложенного варианта подсчета трудоемкостей для каждого типа источников алертов, можно рассмотреть вариант приведения всех источников к какому-то одному, например, мониторинг Web-шлюза равен по трудоемкости мониторингу N конечных точек (например, это N - как раз количество эндпоинтов, фильтруемых на шлюзе), ну или трудоемкостью анализа алертов от Web-шлюза можно пренебречь, так как они будут расследоваться все равно по телеметрии от конечных точек, и эти срабатывания - всего лишь дополнительный взгляд на попытки компрометации конечных точек, и поэтому обработку детектов от Web-шлюза не имеет смысла рассматривать отдельно, - собственно, такой же логики мы придерживаемся в случае c KATA. Также следует отметить, что в эпоху XDR, все алерты приходят с единого центра корреляции в виде аггрегированном виде, когда алерты от разных источников про одно и тоже уже собраны в единый мета-алерт, что позволяет вообще не привязываться к конкретным сенсорам.
Итак, разобрались с объемом мониторинга, для целей этой статьи будем мерить его в конечных точках. В этом случае работа по оперативному мониторингу выглядит примерно так: N конечных точек генерят события телеметрии, которые в облаке автоматически обрабатываются, в результате создаются алерты, которые затем расследуются. Часть алертов конвертируются в инциденты, инциденты оформляются, публикуются заказчикам вместе с планом реагирования: что можно отреагировать техническими средствами - реагируется, а что за рамками технических возможностей - описывается в виде рекомендаций (guided response). Актуальная воронка от событий с эндпоинта до инцидентов заказчикам публикуется нами в аналитических отчетах MDR. Для целей нашего расчета нам потребуются следующие значения (привожу наши данные за февраль 2025, их следует рассматривать в качестве пример, у каждого они - свои, да и у нас они постоянно меняются):
- Ожидаемое количество алертов с конечной точки - 0,0320 (это очень среднее значение, но для целей расчета оно вполне подходит, оно тем точнее, чем больше общий объем мониторинга, а это как раз наш случай)
- Среднее количество инцидентов из алертов - 0,0896 (в шаблоне используется слово "конверсия", однако, это не конверсия, так как это значение учитывает и конверсию, и среднее количество алертов, релевантных инциденту (нередко более одного алерта относятся к одному инциденту). Фактически, это просто отношение числа инцидентов, опубликованных заказчикам, к числу алертов, обработанных командой аналитиков SOC)
Значения выше позволят нам предсказывать количество алертов от эндпонитов в объеме мониторинга, и число инцидентов из количества алертов. Чтобы превратить эти числа в трудоемкость, надо иметь статистические данные по времени обработки алерта и инцидента. Для целей этой статьи пусть они будут следующие:
- Время обработки алерта - 5 мин = 0,08 ч
- Время работы над инцдентом - 40 мин = 0,67 ч
С учетом приведенных значений, совокупная трудоемкость мониторинга может быть представлена следующим образом:
(1) W = Na * 0,08 + Ni * 0,67 (ч), где Na - количество алертов, Ni - количество инцидентов
С учетом статистически среднего количества инцидентов из алертов, Ni можно выразить через Na и подставить в (1):
(2) W = Na * 0,08 + Na * 0,0896 * 0,67 = Na * (0,08 + 0,0896 * 0,67)
А с учетом статистики алертов с конечной точки, мы имеем возможность получить выражение объема работы через количество эндпоинтов, т.е. через объем мониторинга:
(3) W = 0,0320 * Npc * (0,08 + 0,0896 * 0,67) , откуда следует выражение для объема мониторинга (количества эндпоинтов):
(4) Npc = W / (0,08 + 0,0896 * 0,67) / 0,0320
С другой стороны, W должна равняться количеству рабочих часов команды, что несложно подсчитать из графиков организации работы.
Про организацию сменных графиков есть замечательный доклад моего коллеги Альберта, который я настоятельно рекомендую посмотреть. Для целей этой статьи я просто приведу внешний вид кусочка сменного графика.
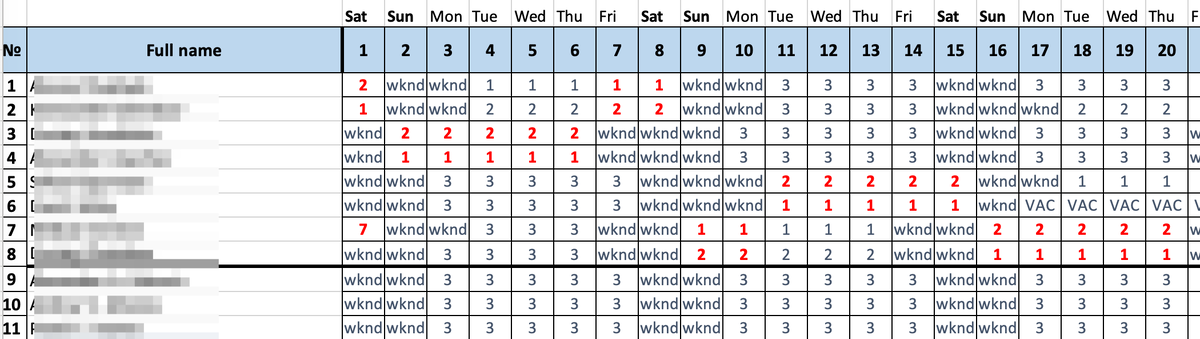
на графике строки - аналитики, столбцы - дни, а в ячейке - номер смены, в которой работает конкретный аналитик (цветовое выделение отображает наши внутренние роли, типа "первый дежурный", "второй дежурный", понимание которых не важно для целей этой статьи, чтобы не усложнять).
Помимо такого графика у нас есть еще график работ второй линии, которая в нашем случае виртуальная. На этом графике указано в какие даты какой аналитик выполняет какие задачи второй линии, структура графика виртуальной второй линии такая же, как у сменного графика, что позволяет их удобно парсить одиним и тем же программным кодом.
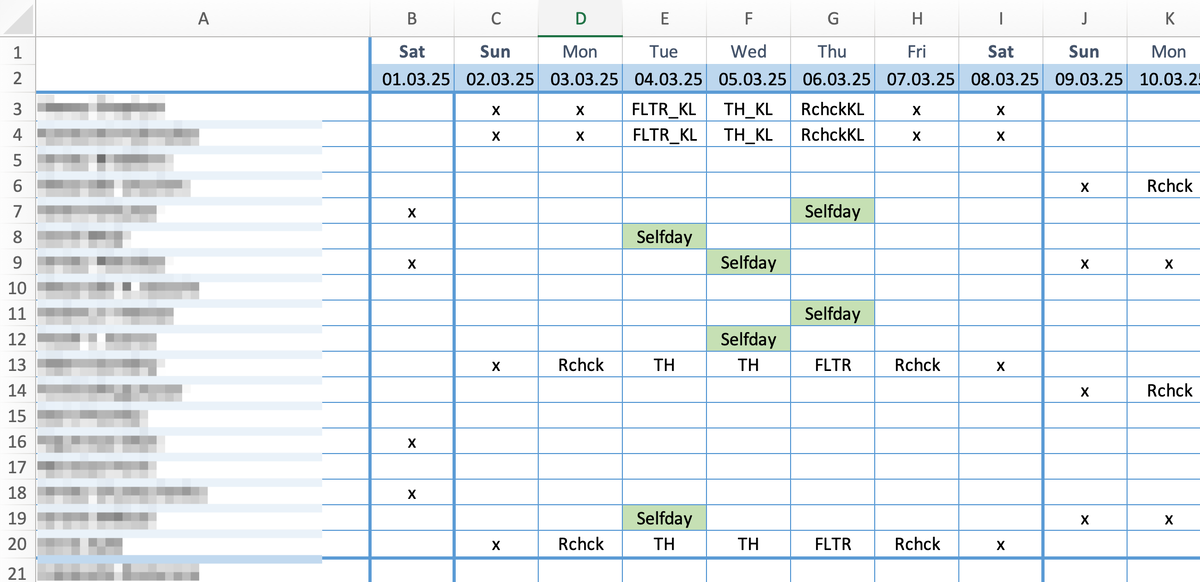
Понятно, что не все время аналитики тратят на операционную работу (обработку алертов), связанную непосредственно с объемом, а то какую долю времени затрачивает на операционку каждая смена зависит от линии SOC. Соответствие того, какую долю рабочих часов затрачивает каждая линия SOC на операционную работу можно определить примерно следующей таблицей.
На картинке представлены линии SOC - "первая" (L1), "вторая" (L2), и "полуторная" (L1.5), и их соответствие сменам в графике (опять же, количество линий сугубо индивидуально, да и у нас их не три, как здесь, а четыре). Например, в L1 работают аналитики, у которых в соответствующий день стоят 1-я, 2-я или 7-я смены. 8,00 часов - это продолжительность смены. Возможные вопросы вызывают "операционная доступность" и "общая доступность", указанные в процентах. Общая доступность - доля рабочего времени, которую аналитик тратит непосредственно на эффективную работу. Пример: 75%, означает, что из смены в 8 часов аналитик непосредственно на работу тратит 6 часов (общедоступное рабочее время). Операционная доступность - доля общедоступного рабочего времени, которое аналитик тратит на обработку алертов, т.е. на работу, связанную непосредственно с объемом. Пример: 90% означает, что из смены 8 часов аналитик эффективно работает 6 часов, из них непосредственно на обработку алертов он тратит 5.4 часа, т.е. 5 часов 24 мин.
Из последней таблицы видно, что вторая и полуторная линии пересекаются по сменам. В этом случае используется следующая логика: если для аналитика указана работа в Графике работ виртуальной второй линии, то этот аналитик считается работающим во второй линии. Если же записи в Графике работ второй линии не находится, то аналитик работает в режиме полуторной линии.
Поняв, в какой линии работает каждый аналитик, по графикам, с учетом общей и оперативной доступности, можно понять сколько времени есть на обработку алертов по каждому аналитику и по всей команде вообще. Имея суммарное время всей команды W, по формуле (4) можно получить объем, выраженный в количестве компьютеров, алерты и инциденты с которых можно обработать заданной командой аналитиков, работающей в указанных сменных графиках.
Описанный расчет очень прост и единственным слабым местом являются коэффициенты пересчета инцидентов в алерты ("конверсия"), а алетов в конечные точки (среднее количество алертов с эндпоинта), а также, средние времена обработки алертов и инцидентов. Однако, при наличии статистики за внушительный период времени и достаточно зрелые процессы обработки алертов и инцидентов, данные коэффициенты можно рассчитать достаточно точно, и они не будут значительно варьироваться в зависимости от конкретного аналитика. Скажу более, эти параметры стоит учитывать, так как они косвенно характеризуют различные аспекты работы SOC:
- количество алертов с эндоинта косвенно характеризует качество детектирующей логики, конверсию алертов в инциденты. Мы следим за этим параметром во времени и стремимся его уменьшать.
- отношение числа инцидентов к числу алертов, или "грязная конверия" - также характеризует качество используемых правил обнаружения.
- время на обработку алерта\инцидента - характеризуют степень автоматизации работы аналитика и тоже являются предметом минимизации во времени.
Перечисленные параметры изменяются со временем, однако, в случае зрелых внутренних процессов, это изменение достаточно гладко, без резких скачков. Если для расчета использовать свежие коэффициенты, то прогноз будет вполне правдоподобным, а этого достаточно для прогнозирования на несколько месяцев вперед.
В нашей практике я использую Jupyter notebook, который парсит наши графики смен и работ второй линии, и выдает максимальное количество энпоинтов, которые мы сможем потянуть, работая в таком режиме смен. Если расчетный объем не покрывает фактический, то это повод переделать смены, например, сократив работы второй линии, или сократив Self-дни, или вообще реорганизовав сменную работу.
Если не хочется разбираться с Jupyter/Python-ом, можно прикинуть расчет и в Excel примерно следующего вида.
Вкладка констант содержит коэффициенты пересчета количества алертов и инцидентов в единицы объема, времена обработки алертов и инцидентов (Mean time to process, MTTP), соответствие линий сменам.
На вкладке расчета на зеленом фоне указаны входные данные, которые надо подсчитать на основе имеющихся графиков смен и второй линии, а на красном фоне результирующий объем: количество рабочих часов (Work), ожидаемое количество алертов (Alerts) и инцидентов (Incidents), и ожидаемое количество эндпонитов (Endpoints) в объеме мониторинга.
Эту несложную эксельку выкладываю.