Введение
В этой статье мы поговорим о третьем этапе обучения языковых моделей — обучении с подкреплением. После того как модель прошла предварительное обучение и тонкую настройку, она готова к следующему шагу: обучению с подкреплением. Этот метод позволяет модели учиться на обратной связи и улучшать свои ответы, делая их более соответствующими человеческим ожиданиям.

Цель обучения с подкреплением
Люди и языковые модели обрабатывают информацию по-разному. Для нас интуитивно понятно, как решать простые математические задачи, но для модели это всего лишь последовательность символов. С другой стороны, модель может давать экспертные ответы на сложные темы, просто потому что она видела много примеров во время обучения.
Эта разница в восприятии делает сложным для человеческих аннотаторов предоставить идеальный набор меток, которые бы постоянно направляли модель к лучшему ответу. Вместо этого модель исследует различные последовательности символов и получает обратную связь — сигналы вознаграждения — о том, какие ответы наиболее полезны. Со временем она учится лучше соответствовать человеческим намерениям.
Интуиция за обучением с подкреплением
Языковые модели стохастичны, то есть их ответы не фиксированы. Даже на один и тот же запрос ответ может варьироваться, поскольку он выбирается из распределения вероятностей. Мы можем использовать эту случайность, генерируя сотни и даже сотни тысяч возможных ответов параллельно. Представьте себе, что модель исследует разные пути — хорошие и плохие. Наша цель — побудить её чаще выбирать лучшие пути.
Для этого мы обучаем модель на последовательностях символов, которые приводят к лучшим результатам. В отличие от тонкой настройки, где эксперты предоставляют помеченные данные, обучение с подкреплением позволяет модели сама обнаружить, какие ответы работают лучше всего. После каждого шага обучения мы обновляем параметры модели. Со временем это делает модель более склонной давать качественные ответы на подобные запросы.
Но как определить, какие ответы лучше? И сколько обучения с подкреплением нужно? Эти вопросы не так просты, и найти правильный баланс не всегда легко.
Примеры успеха обучения с подкреплением
Один из ярких примеров силы обучения с подкреплением — это AlphaGo, разработанная DeepMind. AlphaGo стала первой ИИ-системой, победившей профессионального игрока в го и позже превзошедшей человеческий уровень игры.
Когда модель обучалась исключительно на примерах (тонкая настройка), она достигала человеческого уровня, но не могла его превысить. Однако обучение с подкреплением позволило AlphaGo играть против самой себя, совершенствовать стратегии и в конечном итоге превзойти человеческие возможности.
Основы обучения с подкреплением
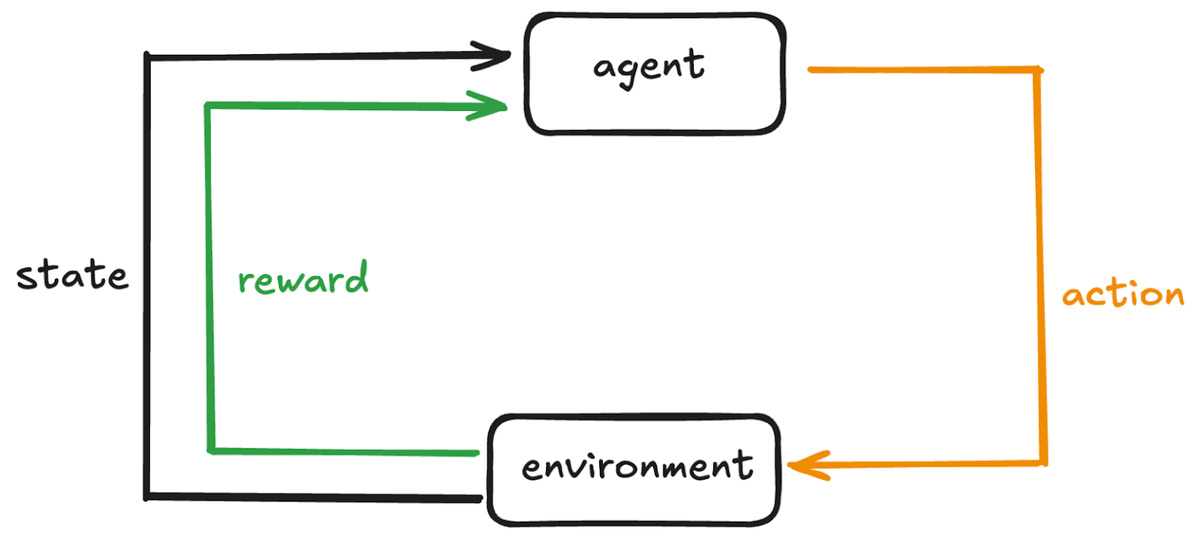
Давайте быстро рассмотрим ключевые компоненты типичной системы обучения с подкреплением:
- Агент — это ученик или принимающий решения. Он наблюдает за текущей ситуацией, выбирает действие и обновляет своё поведение на основе результата.
- Среда — это внешняя система, в которой работает агент.
- Состояние — это снимок среды на данный момент.
На каждом шаге агент совершает действие в среде, меняя её состояние. Агент также получает обратную связь — вознаграждение — которое указывает, насколько хорошо или плохо было его действие. Это вознаграждение представлено в числовой форме: положительное вознаграждение поощряет поведение, а отрицательное — отговаривает.
Используя обратную связь из разных состояний и действий, агент постепенно учится оптимальной стратегии, чтобы максимизировать общее вознаграждение со временем.
Политика и функция ценности
- Политика — это стратегия агента. Если агент следует хорошей политике, он может постоянно принимать хорошие решения, что приводит к более высоким вознаграждениям за многие шаги.
- Функция ценности — это оценка того, насколько хорошо быть в определённом состоянии, учитывая долгосрочное ожидаемое вознаграждение. Для языковых моделей вознаграждение может поступать от человеческой обратной связи или модели вознаграждения.
Архитектура Actor-Critic
Это популярная схема обучения с подкреплением, сочетающая два компонента:
- Актор — учит и обновляет политику, решая, какое действие совершить в каждом состоянии.
- Критик — оценивает функцию ценности, чтобы дать обратную связь актору о том, приводят ли его выбранные действия к хорошим результатам.
Как это работает:
- Актор выбирает действие на основе своей текущей политики.
- Критик оценивает результат (вознаграждение + следующее состояние) и обновляет свою оценку ценности.
- Обратная связь критика помогает актору усовершенствовать свою политику, чтобы будущие действия приводили к более высоким вознаграждениям.
Применение к языковым моделям
Состояние может быть текущим текстом (запросом или разговором), а действие — следующим символом, который нужно сгенерировать. Модель вознаграждения (например, человеческая обратная связь) сообщает модели, насколько хорошо или плохо сгенерированный текст.
Политика — это стратегия модели для выбора следующего символа, а функция ценности оценивает, насколько полезен текущий контекст текста для получения качественных ответов в долгосрочной перспективе.
Примеры успешных моделей
DeepSeek-R1
Чтобы подчеркнуть важность обучения с подкреплением, давайте рассмотрим DeepSeek-R1, модель рассуждений, достигшую высокого уровня производительности и остающуюся открытым исходным кодом. В статье представлены две модели:
- DeepSeek-R1-Zero — обучалась исключительно с помощью крупномасштабного обучения с подкреплением, минуя тонкую настройку.
- DeepSeek-R1 — развивает идеи, решая проблемы, с которыми столкнулась предыдущая модель.
1. Алгоритм обучения с подкреплением: Group Relative Policy Optimisation (GRPO)
Одним из ключевых алгоритмов является GRPO, вариант широко известного Proximal Policy Optimisation (PPO). GRPO был представлен в статье DeepSeekMath в феврале 2024 года.
PPO сталкивается с трудностями при решении задач рассуждений из-за:
- Зависимости от модели критика. PPO требует отдельной модели критика, что удваивает потребление памяти и вычислительных ресурсов.
- Сложности в обучении критика, особенно для тонких или субъективных задач.
- Высоких вычислительных затрат, поскольку пайплайны обучения с подкреплением требуют значительных ресурсов для оценки и оптимизации ответов.
- Абсолютных оценок вознаграждения. Если полагаться на абсолютные вознаграждения — то есть на единый стандарт для оценки, является ли решение «хорошим» или «плохим» — это может быть сложно уловить нюансы открытых и разнообразных задач в разных доменах рассуждений.
GRPO устраняет модель критика, используя относительную оценку — ответы сравниваются внутри группы, а не оцениваются по фиксированному стандарту.
Представьте себе студентов, решающих задачу. Вместо того, чтобы учитель оценивал каждого индивидуально, они сравнивают свои ответы, учась друг у друга. Со временем их результаты сходятся к более качественным.
2. Цепочка рассуждений (CoT)
Традиционное обучение языковых моделей включает предварительное обучение → тонкую настройку → обучение с подкреплением. Однако DeepSeek-R1-Zero пропустила тонкую настройку, позволив модели напрямую исследовать цепочку рассуждений.
Как и люди, разбирающиеся с трудным вопросом, цепочка рассуждений позволяет моделям разбивать проблемы на промежуточные шаги, повышая способности к сложным рассуждениям. Модель OpenAI o1 также использует этот подход, как указано в отчёте сентября 2024 года:
Производительность o1 улучшается с увеличением количества обучения с подкреплением (вычислительные ресурсы во время обучения) и времени рассуждений (вычислительные ресурсы во время тестирования).
DeepSeek-R1-Zero демонстрировала рефлексивные тенденции, автономно совершенствуя свои рассуждения. Без явной программирования она начала пересматривать прошлые шаги рассуждений, повышая точность. Это подчеркивает цепочку рассуждений как эмерджентное свойство обучения с подкреплением.
Модель также имела «момент прозрения» — интересный пример того, как обучение с подкреплением может привести к неожиданным и сложным результатам.
Обучение с подкреплением с человеческой обратной связью (RLHF)
Для задач с верифицируемыми выходами (например, математические задачи, фактические вопросы и ответы) ответы ИИ можно легко оценить. Но что насчёт таких областей, как суммирование или творческое письмо, где нет единственного «правильного» ответа?
Вот где на помощь приходит человеческая обратная связь — но наивные подходы к обучению с подкреплением не масштабируются.
Давайте рассмотрим наивный подход с некоторыми произвольными цифрами.
Это потребует миллиард оценок от людей! Это слишком дорого, медленно и не масштабируемо. Поэтому лучше обучить модель вознаграждения, чтобы она училась предпочтениям людей, что значительно уменьшает усилия людей.
Преимущества RLHF
- Может применяться к любой области, включая творческое письмо, поэзию, суммирование и другие открытые задачи.
- Оценка выходов гораздо проще для человеческих аннотаторов, чем генерация творческих выходов самостоятельно.
Недостатки RLHF
- Модель вознаграждения является приближением — она может не идеально отражать человеческие предпочтения.
- Обучение с подкреплением хорошо «обманывает» модель вознаграждения — если запустить его слишком долго, модель может эксплуатировать лазейки, генерируя бессмысленные выходы, которые также получают высокие баллы.
Для эмпирических, верифицируемых областей (например, математика, программирование) обучение с подкреплением может работать бесконечно и открывать новые стратегии. RLHF, с другой стороны, больше похоже на шаг тонкой настройки, чтобы выровнять модель с человеческими предпочтениями.
Вывод
Обучение с подкреплением — это мощный инструмент, позволяющий языковым моделям учиться на обратной связи и совершенствовать свои ответы. Это не новая тенденция — она уже показала свою силу в таких проектах, как AlphaGo. С помощью алгоритмов, таких как GRPO и подходов, как цепочка рассуждений, модели могут достигать высокого уровня производительности и даже превосходить человеческие возможности. Обучение с подкреплением с человеческой обратной связью позволяет применять эти модели в творческих и открытых задачах, делая их более соответствующими человеческим ожиданиям.
Подписывайся на наш канал https://t.me/aistars1, там рассказываем про разные нейросети намного чаще!