Ранее я написала про то, как рассчитывается consistency index (CI), и про его недостатки.
Теперь давайте разберемся, что такое retention index (RI). Для того, чтобы было удобно сравнивать, я буду приводить в пример все те же матрицу и кладограммы, что и в прошлом примере.
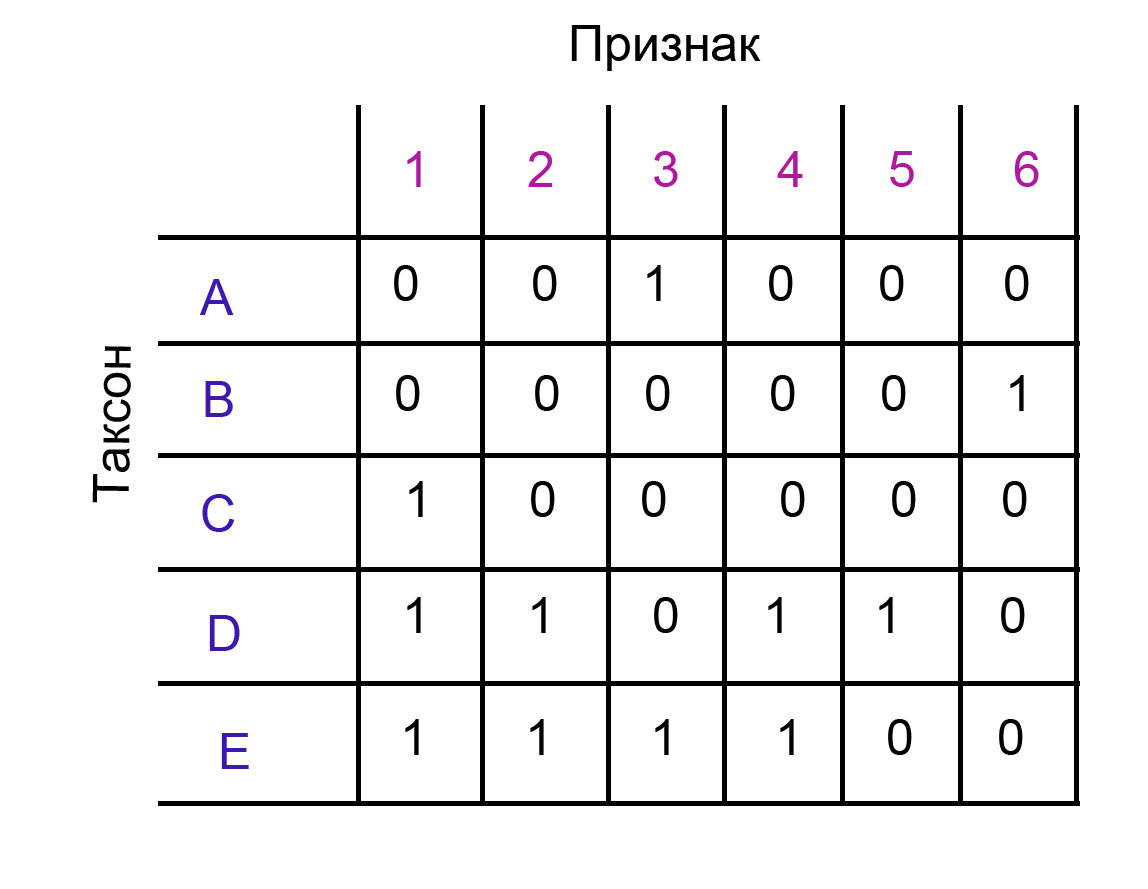
Коэффициент CI - по сути это отношение количества строгих апоморфий к количеству гомоплазий. А коэффициент RI учитывает не только минимальное возможное количество шагов, но также и максимальное возможное количество шагов.
То есть retention index для конкретного признака ri = (g-s)/(g-m). В этом случае m - минимальное количество шагов, s - реальное количество шагов. Это я объясняла в прошлом посте. Еще одно число, g, - это как раз максимальное количество шагов. Максимальное количество шагов для признака с двумя состояниями - это сколько раз появляется состояние признака, которым обладают меньшее количество таксонов. По сути это самое экономное количество шагов на самой неэкономной топологии для данного признака.
То есть, для признака 1, g = 2, потому что состояние 0 у него появляется 2 раза, а состояние 1 - три раза. Почему это максимальное количество шагов? Просто потому что следуя принципу парсимонии, мы должны расположить признаки на кладограмме экономно, и в таком случае состояние, которое появляется у большего количества таксонов, будет предковым, и максимальное количество появлений признака на кладограмме будет равняться количеству таксонов, у которых будет менее популярное состояние.
Если у нас состояний для признака больше двух, то подсчеты усложняются, но все равно нам нужно для каждого случая посчитать самое экономное количество шагов для самой неэкономной топологии для этого признака (оставим это компьютеру).
В нашем примере ri для признаков 1, 2, 4 будет (2-1)/(2-1) = 1. Для признака 3 ri = (2-2)/(2-1) = 0. Этот признак обладает меньшим ri, потому что он образует гомоплазию. Ну и для признаков 4 и 5 индивидуального ri по сути нет, потому что он будет (1-1)/(1-1), а 0 на 0 делить нельзя.
Поскольку нас интересует все же RI для всего дерева, давайте посчитаем его. Его формула RI = (G-S)/(G-M). Где G- максимальное количество шагов для всей матрицы, М - минимальное количество шагов для всей матрицы, и S - реальное количество шагов на конкретной филогении.
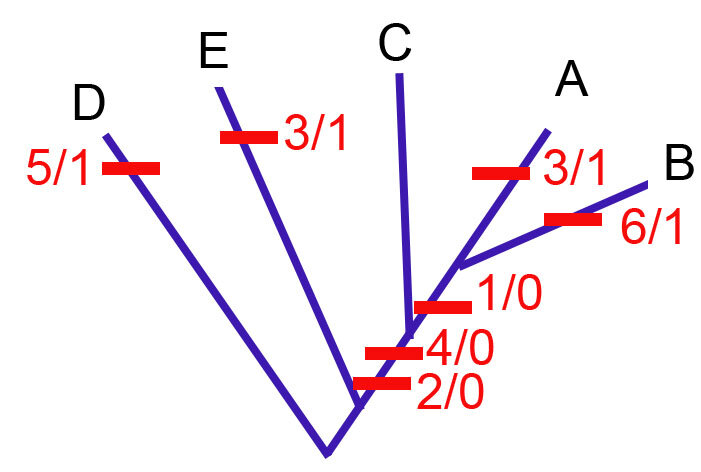
Для вышеприведенной филогении,
G = 2+2+2+2+1+1 = 10
M = 1+1+1+1+1+1 = 6
S = 7 (количество шагов на дереве).
RI = (10-7)/(10-6) = 3/4 = 0.75
Если мы уберем неинформативные признаки 5 и 6 из матрицы, то самое экономное дерево у нас получится таким же, значения искомых параметров будет следующим:
G = 2+2+2+2 = 8
M = 4.
S = 5 (длина дерева за вычетом появлений признаков 5 и 6).
RI = (8-5)/(8-4) = 3/4 = 0.75.
Таким образом, наличие неинформативных признаков для RI значения не имеет.
Ну и сравним с менее экономным деревом:
Матрица та же, но топология и длина дерева другие.
G = 10
M = 6
S = 9
RI = (10-9)/(10-6)= 1/4 = 0.25.
И если убрать неинформативные признаки 5 и 6, то
G = 8
M = 4
S = 7
RI = (8-7)/(8-4) = 1/4 = 0.25.
Получается, что также как и в случае CI, количество гомоплазий понижает значение коэффициента RI. Однако, в отличие от CI, на RI совсем не влияют неинформативные признаки, и это вызывает больше доверия к нему.
С другой же стороны, если вы сами делаете матрицу и сами не включаете туда неинформативные признаки, то для вас этот плюс будет не особенно существенным, и вы сможете использовать оба коэффициента для сравнения полученных деревьев.
CI отражает насколько мы близки к идеальному случаю, когда у нас любое состояние либо предковое и не появляется на кладограмме, либо появляется один раз (строгие апоморфии). Что в общем, логично и интуитивно понятно. Если у нас слишком много гомоплазий, то, возможно, нам надо как-то модицифировать нашу матрицу. Однако понятно, что идеал во многих случаях недостижим, да и стремимся мы не к нему, а в к самому экономному дереву. Насколько самое экономное дерево должно быть близко к идеалу - это вопрос философский и зависит слишком от многих факторов (ранга группы, количества морфологических признаков, самими признаками, нашими целями, качеством материала). При больших матрицах у нас все равно много гомоплазий, и поэтому вероятность того, что CI будет меньше 0.5, высока. Это не повод для большого беспокойства.
Таким образом, возможно, нам больше скажет не то, насколько далеко мы оказались от идеала , а где мы находимся между лучшим и худшим случаями. RI - это отношение расстояния реальной кладограммы до самой неэкономной кладограммы, к полному расстоянию между самым экономным и самым неэкономным случаями. Даже если случайно сгенерировать топологию, то у нас будет 50% шансов, что RI будет >0.5 (и на самом деле очень мало шансов попасть на худший случай). Учитывая, что все же мы расставляем состояния не случайным образом, а все же пытаемся отразить апоморфии и особенно обращаем внимание на строгие апоморфии, то велика вероятность, что мы будем ближе к лучшему случаю, чем к худшему. Даже при большом количестве гомоплазий RI будет больше 0.5. Если даже RI у вас меньше 0.5, то это означает, что явно что-то пошло не так, и стоит поразмыслить над тем, как вы кодируете признаки, и что они вас приближают к максимальному количеству шагов сильнее, чем к минимальному количеству.
На реальных матрицах CI будет обычно меньше, чем RI, просто потому что CI отражает отношение шагов идеальной кладограммы к реальной, и все равно гомоплазий будет много. Многие состояния будут появляться более одного раза, а некоторые состояния будут появляться на дереве более двух раз. RI же будет выше, потому что отражает, насколько мы ближе к лучшему случаю, чем к худшему. И даже при большом количестве гомоплазий, при условии, что мы пытаемся добавить больше апоморфий, мы будем ближе к лучшему варианту, чем к худшему.