В статьях, где приводятся кладограммы, полученные с помощью парсимонии, вы часто будете видеть, что авторы в результатах приводят длину дерева, а также значения коэффициентов CI и RI. Зачем это надо?
Эти значения показывают, насколько признаки хорошо ложатся на полученную топологию. Если у нас много независимых случаев появления какого-то состояния (гомоплазии), то длина дерева будет расти, а коэффициенты снижаться (про длину дерева я объясняла здесь). Если же у нас много строгих апоморфий и много состояний появляются всего один раз, то у нас длина дерева уменьшается, а коэффициенты растут, что отражает хорошее качество полученной филогении.
Важно понимать, что эти значения можно сравнивать только в ходе одного анализа. Сравнивать их с результатами другого анализа, где использовались другие таксоны и другие признаки, не имеет никакого смысла. То есть длина дерева и коэффициенты CI и RI нужны для нас, чтобы мы могли оценить наши окончательные результаты по отношению к промежуточным.
Нет никакого критерия, какими длина дерева, CI и RI должны быть, чтобы дерево могло считаться достаточно хорошим, поскольку это все относительные вещи. Хотя, конечно, если оба коэффициента очень малы (менее 50%), то это может насторожить также и рецензентов.
Давайте рассмотрим коэффициент CI на примере вот этих матрицы и кладограммы (они уже использовались для объяснения темы по ручному построению деревьев Часть 1 и Часть 2).
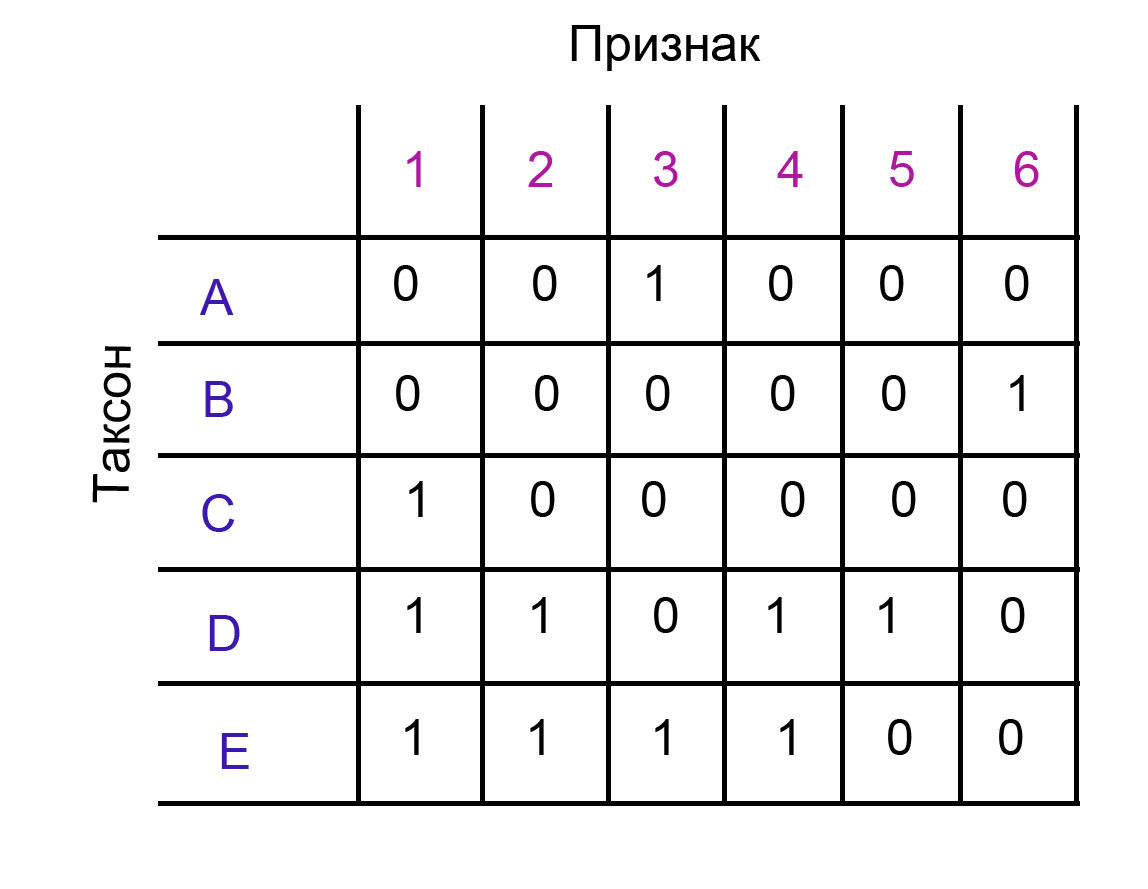
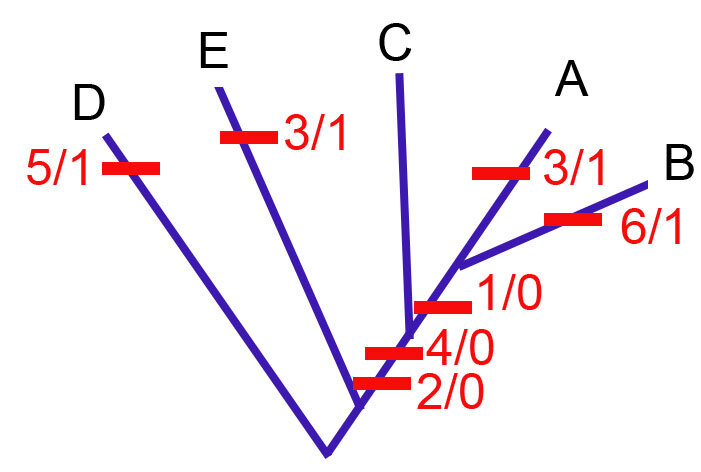
Для того, чтобы посчитать коэффициент ci для одного признака, нам нужно понять, какое у него минимальное число шагов, и количество шагов на конкретной филогении.
Минимальное количество шагов (m) - это просто минимальное количество переходов между состояниями. Если у признака всего два состояния 0 и 1, то минимальное количество шагов - 1. Если у него три состояния, 0, 1 и 2, то минимальное количество шагов - 2, и так далее.
Количество шагов на филогении (s)- это то, сколько раз признак на ней появляется.
К примеру, на филогении выше у всех признаков m = 1. У всех признаков s = 1, кроме признака 3, у которого s = 2, потому что он дважды появляется на филогении (таксоны A и E).
Для всех признаков, кроме признака 3, ci = m/s = 1. Для признака 3 ci = m/s = 1/2 = 0.5.
CI для всей кладограммы равняется M/S, где M = сумма минимальных шагов для всех признаков, а S = сумма шагов для всех признаков на филогении (по сути его длина). В данном случае у нас M = 6, потому что у нас 6 признаков и у каждого по два состояния. S = 7, потому что пять признаков появляется на филогении по одному разу, и один признак - дважды.
В этом случае CI = 6/7 = 0.85.
Давайте посчитаем CI для другого дерева, которое построено по той же матрице, но не самое экономное.
Тут также минимальное количество шагов равняется 6, потому что у нас точно такая же матрица с таким же количеством состояний. Однако S (количество шагов на дереве) равняется 9, потому что признаки 2, 3 и 4 на нем встречаются дважды.
Таким образом, CI = 6/9 = 0.67.
По сути CI показывает, насколько реальное дерево, которое у нас получилось, отличается от "идеала", а идеал - это когда одно состояние признака предковое, а все остальные встречаются один раз.
Второе дерево по этой оценке хуже, чем первое, потому что оно дальше от идеала.
В книге Kitching (1998) перечисляются три недостатка коэффициента CI.
1) Один недостаток касается неинформативных признаков и, на мой взгляд, он самый серьезный. Неинформативные признаки - это признаки, у которых только одно состояние встречается более одного раза Например, а нашей матрице 5 таксонов. Если у какого-то признака состояние 0 встречается у 4 из них, а состояние 1 - у одного, то такой признак считается неинформативным. Про то, почему такие признаки не несут ничего для филогении я объясняла в статьях про кодирование признаков (Часть 1 и Часть 2). У них всегда минимальное количество шагов будет равняться количеству шагов на реальном дереве. Чем больше процент таких признаков в матрице, тем выше CI. Таким образом, если к нашей матрице добавим пять таких признаков, то для второго дерева CI = (6+5)/(9+5) = 11/14 = 0.78. То есть это заметно выше, чем было изначально (0.67), но дерево не становится от этого лучше, потому что все эти признаки - аутапоморфии для одного единственного таксона. Это действительно серьезный аргумент против CI, потому что получается, что его значение может расти, но дерево при этом не становится более экономным.
2) Второй недостаток коэффициента CI - то, что он никогда не достигает 0. Что логично, потому что минимальное количество шагов никогда не будет 0. Однако я не понимаю, почему это недостаток, поскольку нам важно не само число, а сравнение значений у разных деревьев.
3) Третий недостаток, перечисленный в Kitching (1998) - самый странный. Он пишет, что с повышением количества таксонов CI будет понижаться, независимо от того, будет ли меняться что-то на дереве. Я не очень понимаю этот аргумент. На мой взгляд, если таксон не идентичен ни с каким другим таксоном по своим информативным состояниям, то вполне логично, что CI скорее всего понизится, потому что у нас будет больше гомоплазий. Если же он идентичен какому-то таксону, то CI никак не изменится. Однако, может, я чего-то не понимаю до конца.
Так или иначе, чтобы все же не полагаться только на CI, для оценки филогений еще используют retention index (RI), о котором я напишу в следующий раз.
Kitching, I. J., Forey, P., Humphries, C., & Williams, D. (1998). Cladistics: the theory and practice of parsimony analysis (No. 11). Oxford University Press, USA.