Работая с большими данными, мы хотим получить ответы на многие вопросы. Это сделать не так уж легко, как может показаться. Существует много подводных камней, на которые часто натыкается начинающий аналитик.
И первое, что приходит в голову — анализ эффективности в целом. Если все данные разные, как понять их эффективность? Тут мне вспоминается анекдот про среднюю температуру в больнице. Кто не слышал, анекдот состоит всего из одного предложения: «Средняя температура в больнице — 36,6». А прикол в том, что в больнице лежат пациенты с температурой. Просто если посчитать морг, то низкая температура мертвых скомпенсирует повышенную температуру больных. Отсюда и выстраивается ложное представление.
Что мы имеем? Получается, знать среднее значение недостаточно? Действительно, средняя температура 36,6 может быть как в выборке от 35 до 38, так и в выборке от 25 до 40. Человек воспринимает среднее значение как нечто такое, от чего нельзя сильно отклоняться. И если я вам скажу например, что у каждого моего друга в среднем по одной машине. Вы подумаете: «ну наверное, у всех по одной, может у кого-то две». Но никак не ожидаете услышать, что ни у кого нет машины, кроме владельца автопаркинга.
ВЫБОРОЧНОЕ СРЕДНЕЕ
Величину, когда мы складываем все данные и делим на их количество, называют выборочным средним или, как привыкли в школе, средним арифметическим. Нельзя сказать, что ее не используют на практике. Более того, в ней нет ничего плохого. Это настоящая средняя величина, по-другому вы ее не найдете.
Представим ситуацию. Нам дали задание: найти среднюю зарплату в России. Есть данные:
35к, 25к, 170к, 38к, 32к.
При подсчете получается, что средняя зарплата в России — 60 тысяч рублей. Где-то мы это уже слышали~! А вот как выглядит график:
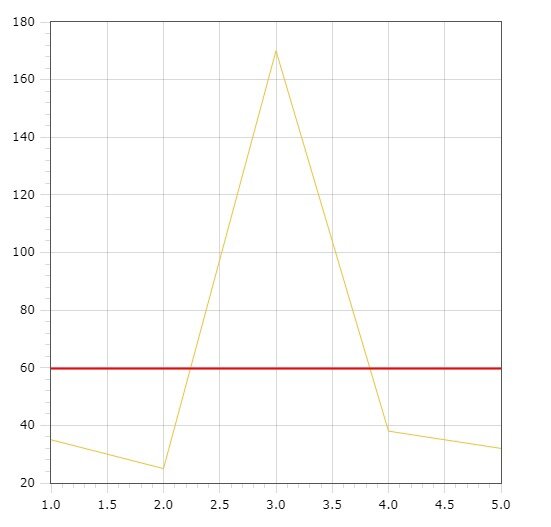
И как бы не поспоришь! Прекрасно видно, что красная линия делит выборку пополам. И даже идет в меньшую сторону снизу, так как там больше данных.
Проблема в том, что когда происходит резкий скачок (как мы видим по графику), то выборочное среднее соответственно растет, хотя ситуация актуальна лишь для одного значения, но никак не касается остальных.
Подобные явления встречаются и в природе, поэтому коррупция чиновников тут ни причем. Например, у меня на лабораторной работе по физике случилось так, что время, за которое шарик погружается в воду, стало вдруг равным семи. Хотя до этого измерял раз десять и было от трех до четырех секунд. В реальной модели никто не гарантирует, что распределение будет «ровным». Поэтому надо что-то придумать другое для поиска «нормального» среднего значения, а не какой-то специально завышенной красивой циферки.
ИЩЕМ НЕ ТО САМОЕ СРЕДНЕЕ
Самое интересное, что мы все сделали правильно. И по телику вас не обманывают. Согласно науке, формула верная и зарплата в 60 тысяч действительно средняя, если не считать, что данные взяты ошибочно. Да, колоссальная разница между минимальным и максимальным значением. Но среднее значение мы нашли правильно! Так же как и среднюю температуру в больнице.
А секрет в том, что мы ищем не то среднее, какое хотим увидеть. Представляя среднюю зарплату, вы подумали скорее о том, что, если получать меньше, будешь ниже среднего по доходам человека, а наоборот — выше. В нашем примере, если ориентир на 60к, противопоставляется один богач на четырех остальных. Это не совсем то, что мы хотим. Если четыре человека ниже порога, а лишь один выше, о каком среднем значении может идти речь? Средний порог должна преодолевать половина людей, иначе это уже не будет средним порогом.
МЕДИАНА
Квантиль половинного порядка (0.5) — это такое число, при котором 50% данных будут не превышать это значение. Соответственно остальные 50% будут выше порога. Его еще называют медианной.
Для того чтобы найти медиану, нужно отсортировать данные по возрастанию, поделить их количество на два, взять по этому индексу конкретное X(n/2). Оно и будет являться медианой. Если не делится на два, берутся два соседних X(n//2) и X(n//2 + 1), где целочисленное деление (//) означает, что при делении надо отбросить дробную часть. Между соседями находится среднее арифметическое, что и будет являться медианой.
Для нашего примера отсортируем и пронумеруем данные:
0) 25к, 1) 32к, 2) 35к, 3) 38к, 4) 170к
Четыре делится пополам (=2). Под номером два стоит x = 35к. Это будет медианой. И в итоге получаем, что средняя зарплата в России — 35 тысяч. Конечно, намного реально выглядит, чем 60к. Но для нашего маленького примера не сходится. Четыре варианта попадают под неравенство x≤35к, и только один богач не попадает. Это явно не дает нам 50/50. Но если взять побольше данных, то вероятнее так и будет. Оказывается, не всегда можно найти медиану. А для нашего примера вообще среднего значения не существует, потому что скачок резкий, а данных маловато…
ВЫВОД
Выборочное среднее будет наглядно отображать эффективность, но только при том случае, если разница между ними небольшая. Лучше, конечно, использовать медиану во избежании дальнейших конфузий.