Поговорим немного о text-image датасетах, которые содержат картинки и текстовые описания к ним. Зачем они нам нужны? Например, для обучения таких моделей как DALL-E (генерит картинку по текстовому описанию), либо CLIP (умеет вычислять похожесть текста и фотографий за счет проецирования текстовых строк и картинок в одно и то же многомерное пространство). Тот же Google Image Search вполне может использовать что-то вроде CLIP для ранжирования картинок исходя из текстового запроса пользователя.
Чтобы натренировать text-to-image модель вроде CLIP, разумеется, нужен дохерильон размеченных данных. Например, OpenAI тренировали CLIP на 400M пар текст-фото, но датасет свой так никому и не показали. Хорошо, что хоть веса моделей выложили на гитхабе. В похожем стиле была натренирована модель DALL-E, выбрали подмножество из 250M пар текст-фото и также никому не показали датасет. Есть подозрение, что боятся копирайта.
Недавно нашумевшая ru-DALL-E (о ней я писал тут) от Сбера был тренировалась на более 120M пар, что приближается к 250M от OpenAI. Сбер использовал всевозможные публичные датасеты. Сначала взяли Сonceptual Captions, YFCC100m, данные русской Википедии, ImageNet. Затем добавили датасеты OpenImages, LAION-400m, WIT, Web2M, HowTo и щепотку кроулинга интернета, как я понимаю. Все это отфильтровали, чтобы уменьшить шум в данных, а все английские описания были решительно переведены на русский язык. Но, к сожалению, датасет тоже не выложили. Зато опубликовали свою натренированную модельку, в отличие от OpenAI
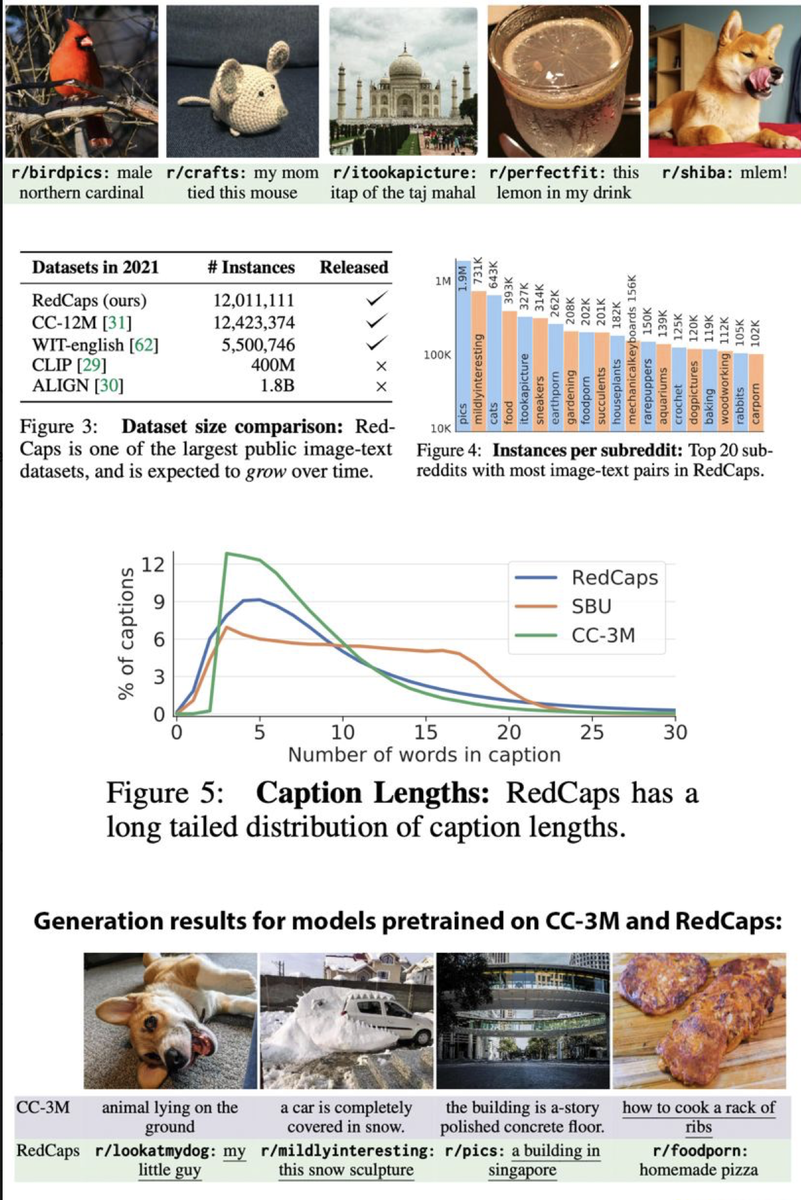
Ещё расскажу о новом датасете RedCaps от Justin Johnson (это имя нужно знать, он крутой молодой профессор) и его студетов из университета Мичигана. Парни попытались найти в интернете новый источник бесплатных аннотаций вида "текст-картинка", который содержал бы меньше мусора по сравнению со скачиванием всего интернета в лоб. Решено было выкачать посты с картинками с Reddit-a, и в качестве аннотаций использовать подпись к картинке и название сабреддита. Названия сабреддитов обычно говорящие и уже сами по себе несут много информации, например, "r/cats", "r/higing", "r/foodporn". После выбора подмножетсва из 350 сабреддитов и небольшой фильтрации вышло 12M пар фото-текст, которые покрывают 13 лет истории Reddit.
На примере этого датасета можно проследить, какакие меры принимаются для уменьшения риска получить повестку в суд после публикации такого огромного количества данных пользователей форума. Все фото с людьми были задетекчены с помощью RetinaNet и нарочито выброшены, а сам датасет опубликовали в виде списка ссылок с анонимизированными текстовыми описаниями (картинки на сайте не хранят). Кроме того, на сайте с датасетом есть форма, где несогласные могут запросить удалить любую ссылку.
В итоге, получился довольно качественный датасет, который превосходит существующие публичные датасеты (кроме LAION-400m, с которым забыли сравниться) для обучения модели генерировать описания по картинке. В качестве ксперимента, обучили Image Captioning модель на разныз датасетах и протестировали на задаче переноса выученной репрезентации на новые датасеты в Zero-Shot сценарии, а также с помощью обучений логистической регрессии поверх фичей (linear probing). Но, конечно обученная учеными из Мичигана модель существенно уступает CLIP по ряду причин: CLIP имеет слегка другую архитектуру (он не генерит текст, а учит эмбеддинги), он толще и жирнее, и тренировали его в 40 раз больше итераций на гигантском датасете, который превосходит в размере RedCaps в 35 раз.
Посмотреть на примеры из RedCaps можно на сайте https://redcaps.xyz/.
#machinelearning #artificialintelligence #ai #datascience #python #programming #technology #deeplearning