https://arxiv.org/pdf/1811.05696v3.pdf
TL;DR
Предложили еще один способ получения разнообразных ответов из генеративной диалоговой модели путем введения дополнительной переменной, изначально задающей тематику ожидаемого ответа и, соответственно, уменьшающей шанс получить респонз по типу "I don't know".
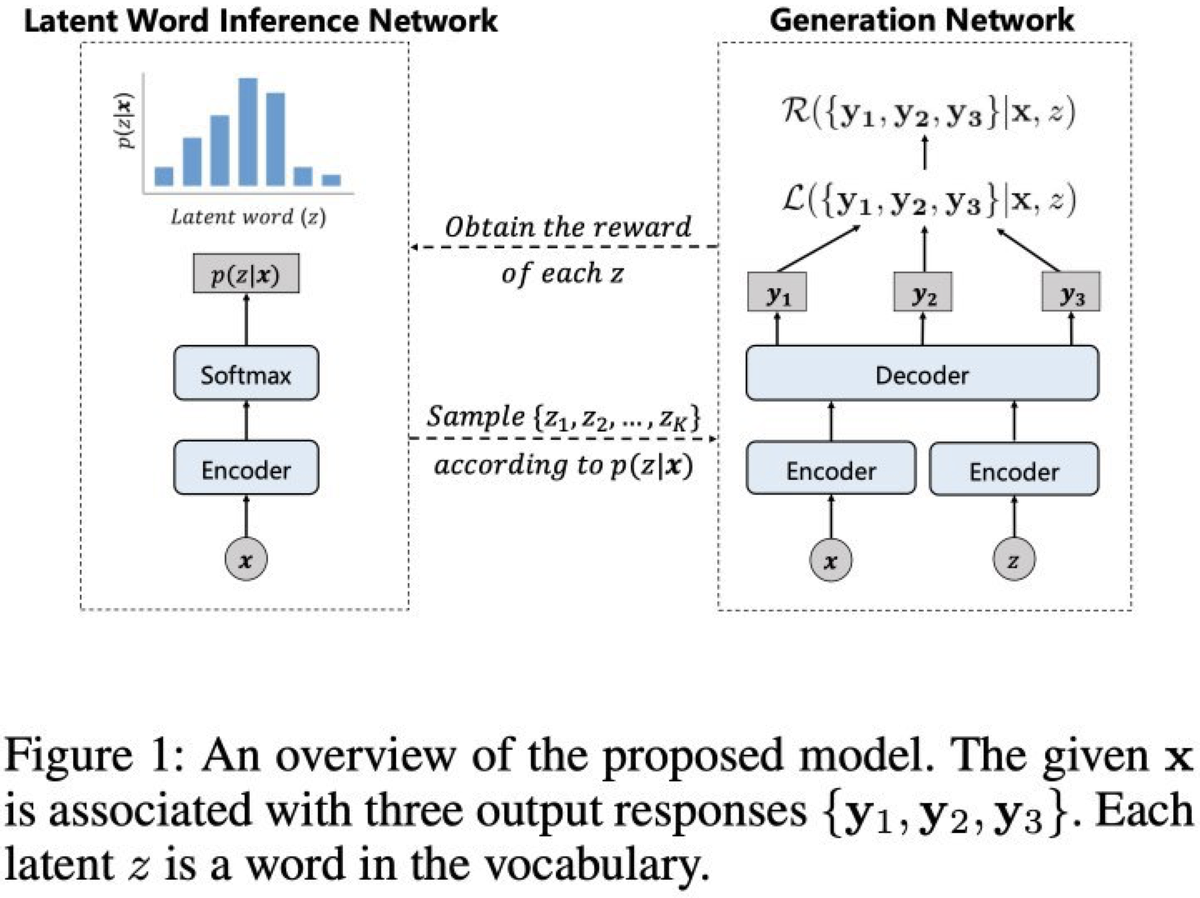
Суть подхода
Одной из проблем генеративных моделей является их склонность к генерации общих и "безопасных" ответов по типу "Yes", "No", "I don't know". Авторы статьи считают, что для борьбы с этой проблемой необходимо сделать две вещи:
1. Взять во внимание тот факт, что на один диалоговой контекст можно дать несколько концептуально разных ответов. Причем факт этот необходимо учитывать не только на инференсе, но и при обучении, т.е. соответствующим образом расчитывать лосс и градиенты.
2. Моделировать тематику ожидаемого ответа с помощью дополнительной случайной переменной (словом или словосочетанием), которая а) обусловлена контекстом б) обуславливает один или несколько возможных респонзов и, соответственно, является еще одним входом генеративной модели
Первый шаг заключается в формулировании задачи оптимизации и подготовке обучающих пар вида x -> {y}, где x - контекст, {y} - набор разнообразных респонзов, подходящих под данный контекст. В качестве источника таких данных авторы используют датасет Weibo и, естественно, Twitter. Лосс представлен как
L = agg_y loss(y, argmax_y* P(y*|x, z)), где y - один из ground truth респонзов {y}, y* – сгенерированный респонз, z – та самая дополнительная переменная с тематикой, agg – функция агрегации лоссов для текущей обучающей пары. Поскольку фиксированная z может обуславливать ноль или один (чаще всего), или несколько (редко) респонзов, то в качестве agg авторы пробуют как min(), так и avg().
Второй шаг заключается во встраивании "тематической" переменной в указанный выше лосс. Поскольку на этапе обучения переменная z не столько должна вычисляться из контекста, сколько "направлять" модель к генерации ожидаемых респонзов, просто так взять и заранее просчитать пары (x, z) без учета {y} не выйдет. Поэтому авторы формулируют задачу как E_p(z|x) (L({y}|x, z)), т.е. с помощью Reinforcement Learning минимизируют лосс L усредненный по всем "тематикам" z. Все выкладки можно посмотреть непосредственно в статье. Отмечу только, что z вычисляется нейросетью, которая обучается с учетом реворда от диалоговой модели, что несколько нетипично. В дополнение к этому, авторы капитально обмазались аттеншеном, чтобы диалоговая модель не дай бог не научилась игнорировать z и не возвращалась к любимым ответам в стиле "I don't know". Поэтому, если выражаться совсем идейно, суть подхода в том чтобы научиться вычислять такие z, при которых генеративная модель обязательно выдает один из ожидаемых на данный контекст респонзов.
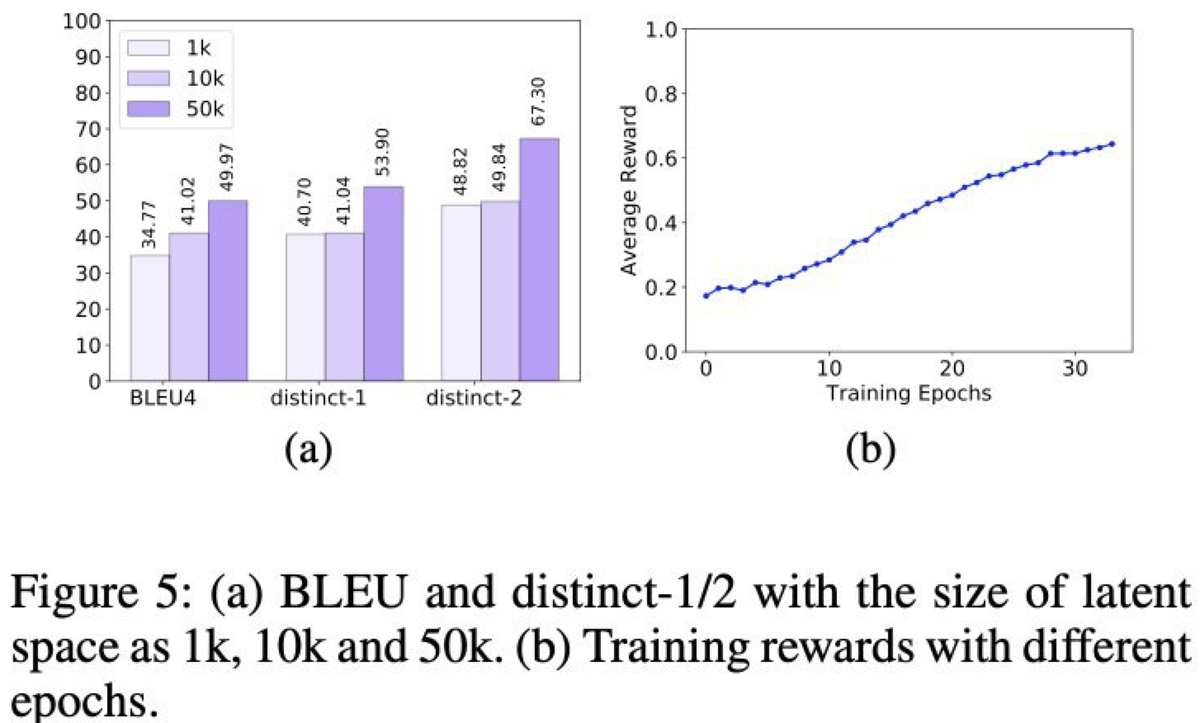
Результаты
Естественно, предложенный подход превосходит все предыдущие методы (beam search, CVAE, MMI и пр.) по таким метрикам как BLEU, distinct 1/2, а также по human-метрикам Quality (bad/normal/good) и Diversity (кол-во отличающихся друг от друга респонзов). Также авторы сравниваются с подходом без RL, при котором модели для вычисления респонзов и тематик обучаются независимо друг от друга.
К сожалению, в данной работе были использованы достаточно примитивные нейросетевые архитектуры, нет ablation study и само сравнение грязноватое, т.к. архитектура генератора в статье сложнее архитектуры генератора предыдущих подходов. Но в целом подход достаточно интересный и складный, есть работающий RL, есть возможность попробовать более сложные (актуальные) архитектуры, так что при наличии острой проблемы разнообразия респонзов вероятно стоит обратить внимание на данную статью.