Сколько анкет нужно для количественного анализа лояльности клиентов?

Когда компании рассчитывают бюджет на проведение исследований лояльности клиентов, они сталкиваются с важным вопросом – какое количество клиентов нужно опросить, чтобы получить достоверные данные? Вопрос стоит остро, так как большие выборки требуют серьезных инвестиций. Такие инвестиции могут позволить себе компании, которые, во-первых, крупные по своей структуре, во-вторых, имеют ориентацию на клиента и готовы вкладывать средства в изучение и формирование клиентского опыта.
Но какой все-таки объем выборки можно считать оптимальным? В рамках своих исследований компания Yes Group проводит масштабные количественные опросы в сфере клиентского сервиса и имеет обширные базы ответов. Возьмем для примера исследование лояльности клиентов российских банков, проведенное в 2020 году. Для Банка 1 было набрано 9 600 оценок клиентов по методике Индекс лояльности A+Loyalty. Попробуем выделить из данного массива несколько подвыборок случайным образом и определим, как будет вести себя Индекс лояльности.
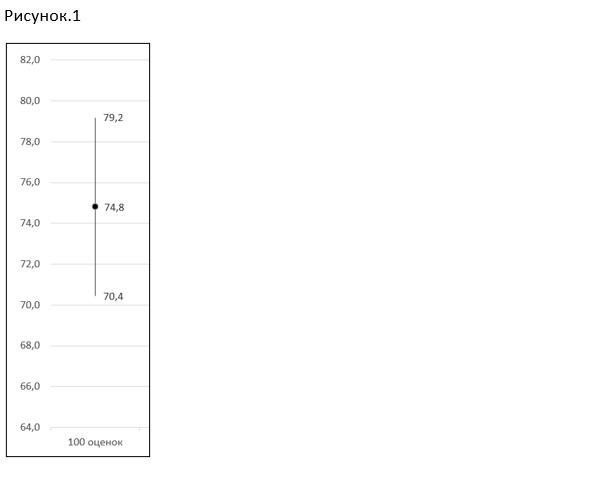
На первом этапе выделим из общего массива (9 600 клиентов) подвыборку в 100 оценок случайным образом. Получим Индекс лояльности, равный 74,8 и соответствующие доверительные интервалы (Рисунок.1). Доверительный интервал – своеобразный «коридор», в котором располагается истинное значение показателя Индекса. Величина (размах) интервала зависит от размера выборки и разброса ответов. Если оценки опрошенных клиентов примерно одинаковые, то интервал будет меньше, если оценки сильно отличаются друг от друга, то интервал будет широким.
В данном случае мы получили доверительный интервал равный +- 4,4 пункта Индекса. Если бы мы опросили абсолютно всех клиентов Банка 1, то по статистике мы получили бы значение Индекса в диапазоне от 70,4 до 79,2 пункта, такова точность измерения на выборке в 100 анкет. При этом если бы в опросе участвовало 100% клиентов банка, доверительный интервал был бы равен нулю.
Попробуем снизить доверительный интервал и повысить точность показателя, увеличив выборку. Из общего массива также случайным образом возьмем подгруппы 200, 400 и 800 оценок (Рисунок 2). В результаты по мере увеличения выборки, получаем сокращение доверительных интервалов с 4,4 (100 анкет) до 1,5 (800 анкет). В группах мы видим, что сам показатель Индекса меняется, но данное изменение статистически не значимо, так как доверительные интервалы показателей пересекаются.
Увеличение выборки до 800 анкет привело к повышению точности показателя почти в три раза. Стоит оговориться, что данное повышение не означает кратное увеличение стоимости исследования. При формировании цены присутствуют постоянные расходы (разработка инструментария, менеджмент проекта и проч.), которые не меняются в зависимости от объема выборки. Поэтому при большем количестве анкет средняя стоимость одного интервью будет ниже.
Пойдем далее и возьмем случайны образом выборки в 1600, 3200, 6400 и 9600 анкет (Рисунок 3). Дальнейшее увеличение выборки не приводит к сильному сокращению доверительного интервала. В группах 800 и 9600 анкет доверительные интервалы 1,5 и 0,4, сокращение больше, чем в 3 раза, но цена равна увеличению выборки в 12 раз. При этом видно, что после 3200 показатель Индекса не меняется и доверительный интервал сокращается все меньше. Соответственно, можно сделать вывод, что выборка в 800 анкет является оптимальной, а последующие увеличения не приводят к существенному повышению точности.
Как говорилось ранее, на размер доверительного интервала влияет разброс ответов клиентов. Данный разброс может быть высокий из-за того, что в выборку попадают разные группы респондентов, уровень лояльности которых отличается по каким-либо причинам. Это могут быть как социально-демографические характеристики (пол, возраст, доход и проч.), так и аспекты, связанные со взаимодействием клиента и компании (наличие определенных продуктов, срок взаимодействия, опыт использования различных каналов). Если целевая аудитория компании однородная, ее характеристики и потребности схожи, то размер выборки может быть небольшой. В случае же дифференцированной клиентской базы необходимо обеспечить минимальный уровень в 100 анкет по каждой группе клиентов, уровень лояльности которых может отличаться.
Экспертиза A+Loyalty
Перед формированием выборки необходим глубокий анализ клиентской базы с целью определения групп, представленность которых необходимо обеспечить. Важно знать среди каких групп клиентов уровень лояльности может быть выше других. Например, эксперты подразделения A+Loyalty компании YES Group знают, что уровень лояльности высокодоходного сегмента выше, чем у массового, женщины ставят более высокие оценки, чем мужчины, по федеральным округам уровень лояльности также отличается. Помимо социально-демографических характеристик, на лояльность также влияет наличие определенных продуктов в портфеле клиента, срок взаимодействия с компанией и прочее. Смещение или низкая представленность какой-либо группы в выборке относительно генеральной совокупности приведет к искажению результатов. У нас есть накопленные данные об уровне лояльности различных групп клиентов на финансовом рынке, в области телекоммуникаций, retail и на других рынках. На основании данного опыта мы сможем провести анализ клиентской базы и определить оптимальный объем выборки.
Необходимо оговориться, что данные рекомендации в большей степени применимы к исследованиям лояльности. Если взять, например, исследование по оценке проникновения рекламной кампании, то уровень знания и восприятия рекламы будет зависеть от других характеристик.