Разберем возможности получения важных описательных характеристик таблицы в библиотеке Pandas, а затем соберем их вместе и напишем функцию для многократного использования. Она поможет сэкономить колоссальное время в будущем при изучении новых таблиц с данными, а также позволит своевременно выявлять в них малозаметные ошибки.
Для демонстрации работы будем использовать игрушечную таблицу (код для генерации представлен в конце статьи), содержащую информацию о поломках машин, а именно - тип машины, флаг наличия дефекта, дату поломки, дату поставки (начала эксплуатации), разницы между этими датами (в месяцах):

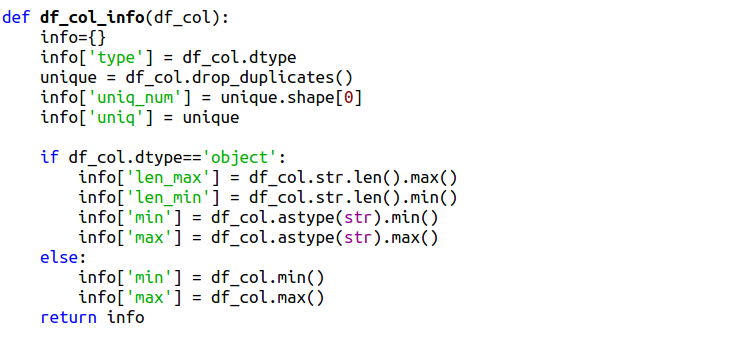
Перечислим, какие общие сведения о колонках нас могут интересовать:
- тип данных;
- количество уникальны значений;
- список уникальных значений;
- максимальное и минимальное значение;
- максимальная и минимальная длина поля.
Тип данных можно получить с помощью свойства столбца dtype, уникальные значения посредством вызова метода drop_duplicates, их число - вызвав свойство shape. Остальные сведения извлекаются в зависимости от типа. В object хранятся данные смешанного типа и строки, а с остальными грубо будем работать как с числами и датами. В результате, для диагностики столбца получим следующую функцию:
Рассмотрим ее работу на примере вывода значения столбца дата_поломки:
Обобщая применение df_col_info для каждой колонки датафрейма создадим еще пару функций:
Можно было обойтись и одной функцией, но в последующих статьях скелет обхода столбцов и применения к ним заданной функции нам еще пригодится.
Ниже представляю код для генерации нашего набора данных:



















