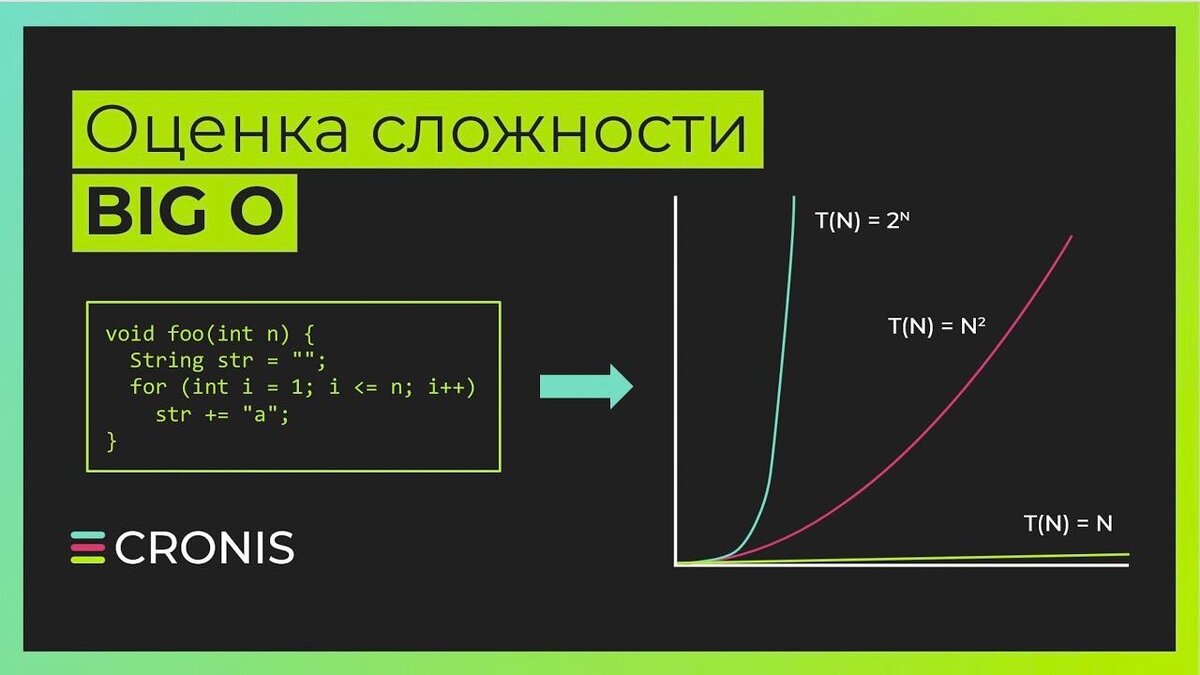
Один из частых вопросов особенно в собеседованиях на Junior и Middle программистов является вопрос про сложность алгоритмов. Да и тебе наверняка встречались записи О(1), O(n) или O(log n) и так далее. Это как раз и есть сложность алгоритмов. Ее оценивают либо по используемой память, но чаще всего - по времени выполнения, это и есть та самая “n”. При этом точное время выполнения, как ты понимаешь, мало кого интересует, так как оно зависит от языка программирования, железа, на котором запущена программа, фазы луны или любого другого небесного тела. Поэтому мы и оперируем переменными величинами в виде n и нам надо понимать, на сколько сложен будет этот алгоритм, ведь если сложность в каждой части кода будет, например, квадратичная O(n2), то хорошо такой код работать не будет нигде. И по хорошему его надо выкинуть, а программиста, который так наплевательски относится к ресурсам компьютера - уволить и найти нового, желательно обладающего хоть каким-то разумом.
Давай сразу пример приведу, а вместе с ним - и первую из наиболее распространенных сложностей - O(n), она же линейная сложность. Эта сложность зависит напрямую от входных данных. Самый простой пример здесь - это поиск какого-то значения в списке элементов. У нас есть список языков программирования, доступных для изучения и надо найти, под каким номером идет Java
languages = ['Perl', 'C++', 'Python', 'Java', 'Ruby', 'COBOL']
Для этого компьютеру надо посмотреть, чему равен каждый из элементов списка, пока он не найдет желаемый текст. Здесь нет каких-то мудреных схем, условий и так далее, просто пройти элементы с 1 по X пока не найдешь нужный, вот это O(n). Есть так же его частный случай - O(1) - это когда сложность не зависит от входных данных. То есть если мы знаем, что Java - это элемент под номером 3 (кстати, напиши в комментах, почему номер 3, хотя, Java на 4 месте), то мы можем получить его значение просто так languages[3], это и будет O(1).
В следующих постах расскажу про остальные самые популярные сложности и приведу примеры, а чтобы их не пропустить - надо подписаться!
Итак, следующая по страшенству, нет, я не перепутал буквы, и занимаемой памяти - квадратичная сложность O(n^2) (привыкай, “домиком” часто показывается возведение в степень). Если мы в одном цикле переберем просто все элементы массива, то сложность будет линейная, а если внутри этого цикла сделаем еще один, то сложность будет квадратичная, так как на каждый элемент, перебираемого в первом цикле массива будет еще несколько элементов во втором цикле. Так например делают для сортировки списков по какому-то алгоритму: возрастанию, убыванию или еще по какому критерию. Так вот, здесь сложность уже квадратичная.
for (let i = 0; i < 10; i++){
for (let j = 0; j < 20; j++){
...
}
}
Признаюсь: забыл упомянуть про логарифмическую сложность. Она стоит буквально рядом с O(1), то есть сильно код не нагружает. А вот то, что действительно нагружает код - это O(2^n) и O(n!).
В случае с экспонециальной функцией 2^n, количество вычислений должно удваиваться с добавлением каждого нового элемента данных. Такое поведение характерно, например, для рекурсий, когда функция вызывает сама себя. И по хорошему, таких решений надо бы избегать, по тому что они сильно нагружают компьютер.
Ну и что касается факториальной функции, то при небольшом количестве входных данных, время выполнения алгоритма растет космически. Вот представь, у тебя какой-то список из, например, клиентов компании и есть какая-то функция, которая их обрабатывает. Так вот, при каждом следующем клиенте, надо обработать снова всех предыдущих и после этого приступить к текущему. Например, мы ищем какой-то признак на счете у клиента и такой клиент может быть только один, а критерии поиска у нас нечеткие. Таким образом мы в текущей итерации можем найти одного такого клиента, а в следующих могут попасться еще больше подходящие под наши критерии. Ну это так, на ходу сочиненный пример из головы. На самом деле, на практике алгоритмы такой сложности встречаются крайне редко и скорее всего для обсчета какой-нибудь хитровывернутой математики, но понимать, как водится, надо.
За сим я закончу серию про сложности алгоритмов. Дальше уже изучай самостоятельно. Посмотри побольше примеров.
А так - как всегда: подписывайся и зови друзей!