Сегодня конкуренцию в бизнесе выигрывают те, кто способен лучше, быстрее, точнее оценивать риски, проверять гипотезы и запускать новые продукты на основе данных. Ретейл с его сотнями тысяч клиентов, точек продаж и товаров — настоящий фронт внедрения технологий, основанных на данных, и топливная розница здесь не исключение.
Что нужно для использования больших данных?
Технологии обработки данных появились не вчера. Но прежде чем прийти к сложным системам, позволяющим работать с большими данными, компании должны пройти поэтапный процесс технологического взросления. Первые шаги относятся к автоматизации отчетности и созданию единой версии правды для принятия решений на основе данных. Затем — объединение данных из большого числа источников для построения гибкой бизнес-аналитики на основе специализированных продуктов Business Intelligence (BI). Когда данных становится очень много, они разной структуры и должны обрабатываться с различной скоростью для разных задач, наступает этап внедрения технологий больших данных (Big Data).
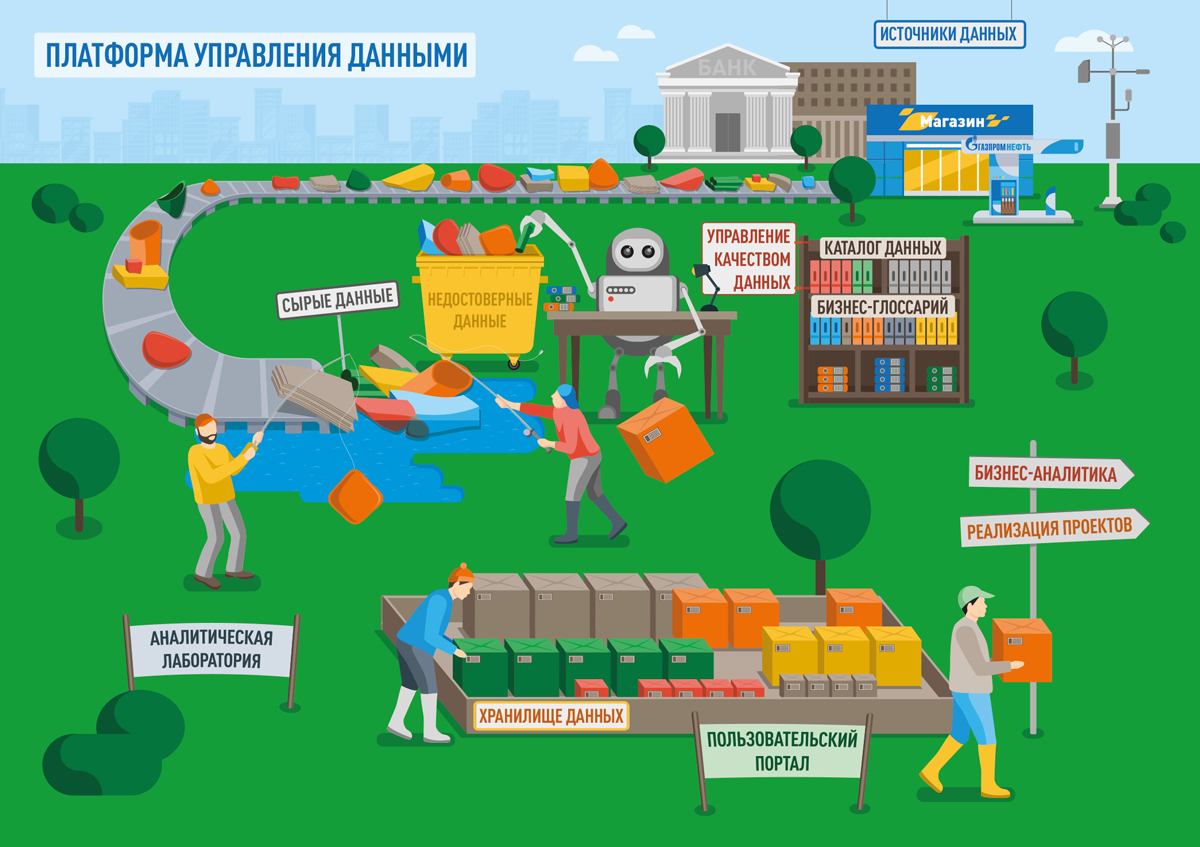
Озеро данных (Data Lake) — базовый элемент архитектуры Big Data, система, в которой собираются большие объемы сырых данных из множества источников. Данные поступают и хранятся в озере, для того чтобы их можно было использовать в будущем ad hoc, то есть по требованию. Важное отличие озера — то, что оно может масштабироваться до экстремальных объемов данных при низких издержках, а также может обеспечивать мгновенный доступ к любым данным для всех пользователей. Извлеченные из озера ценные структурированные данные размещаются и преобразуются алгоритмами в аналитических хранилищах (Data Warehouse), роль которых — быть надежным доверенным источником и поставщиком данных для самых различных пользователей и систем. Создание озер и хранилищ требует больших ресурсов, но создает среду для надежной обработки больших массивов данных и работы более сложных алгоритмов.
Рядом со складами — озерами и хранилищами — размещается цифровая лаборатория исследования данных (Data Science) — специально организованный набор инструментов построения цифровых моделей, продвинутого анализа и быстрой проверки гипотез. В этих условиях аналитика расцветает, массивы данных превращаются в модели и прототипы, обретают неслучайные взаимосвязи и дарят новые идеи бизнесу. Модели и прототипы, которым бизнес доверяет, преобразуются в управленческие решения, экономические прогнозы, коммерческие предложения. Если компания системно и целенаправленно развивает аналитику, со временем используемые Data Science модели усложняются и становятся способны давать умные рекомендации и в отдельных ситуациях принимать решения вместо человека. Этот этап называется внедрением искусственного интеллекта (ИИ). Сегодня искусственный интеллект — ключевой драйвер роста многих отраслей бизнеса.
Благодаря внедрению искусственного интеллекта к 2030 году мировая экономика может вырасти на 15,7 трлн долларов США, следует из глобального исследования PriceWaterhouseCoopers в области искусственного интеллекта. Проведенный анализ более чем 300 примеров применения ИИ показал, что наибольшая готовность к внедрению технологии сегодня в ретейле и технологических отраслях. В то же время сферы, пока еще редко использующие возможности искусственного разума, могут сделать значительный рывок, прибегнув к его услугам.
Внедрение ИИ невозможно без эффективного управления данными (Data Governance), ведь использование искусственного интеллекта означает полное доверие человека алгоритмам и все больший отказ от их контроля. Компания должна научиться каталогизировать доступные ей данные, контролировать их происхождение, измерять и улучшать качество, закреплять процессы изменения и реагирования на различные неожиданности, делать данные доступными и одинаково понимаемыми для всех сотрудников.
Внедрение инструментов Data Governance требует больших сроков, высокой организационной и технологической зрелости, поэтому откладывается многими компаниями. Но без фокуса на Data Governance озера данных превращаются в болота, и их становится невозможно использовать из-за отсутствия доверия к данным и их понимания. По мировой статистике, около 90% проектов внедрения озер данных и исследования данных терпят неудачу из-за недостатка управления данными.
Как устроена аналитическая платформа?
В дирекции региональных продаж, занимающейся топливной розницей «Газпром нефти», более 7 лет развивались и применялись решения, связанные с автоматизацией отчетности и гибкой бизнес-аналитикой (BI). В 2017 году накопленные массивы данных потребовали создания решений для обработки Big Data и продвинутой аналитики. Понимая, чего потребуют следующие этапы эволюции аналитики, в компании решились на одновременное внедрение платформы, включающей компоненты Big Data, Data Science и набора инструментов Data Governance. На реализацию проекта, названного «Умное озеро данных», ушло 2 года. Сообщество IT-директоров России Global CIO признало его лучшим проектом 2019 года в номинации «Аналитические решения и Big Data», отметив при этом, что пока аналитическая платформа ДРП — единственная в России в своем классе.
Платформа включает компоненты обработки, хранения и анализа данных: озеро данных, хранилище данных, лабораторию продвинутой аналитики. Они работают в тесной интеграции с компонентами управления данными: корпоративным каталогом данных, системой управления качеством данных, бизнес-глоссарием, порталом навигации по данным на всех этапах обработки.
Каталог данных умеет автоматически извлекать информацию из озера и хранилища данных, BI-системы ДРП, а также процедур обработки данных в этих системах. Благодаря этому он содержит техническую карту всех имеющихся данных, а также потоков их происхождения (Data Lineage). Внутренние эксперты обогащают объекты в каталоге описаниями и различными характеристиками, благодаря чему встроенные в каталог поисковые механизмы позволяют очень гибко находить нужные данные и оценивать влияния между системами и моделями данных. Кроме этого, каталог имеет множество специализированных функций, основанных на алгоритмах ИИ. Кейсы российских банков подтверждают: при внедрении каталога данных работа аналитиков и архитекторов ускоряется на 40%. А исследования международной компании Gartner говорят, что при наличии корпоративного каталога данных окупаемость инвестиций в данные и аналитику ускоряется в три раза. Наполнение каталога — долгий процесс с большим количеством участников — по мировой практике занимает несколько лет. Сейчас в каталоге паспортизованы около 1000 объектов данных, и это только начало большого пути.
Система управления качеством данных позволяет создавать правила проверки качества для данных в озере и хранилище, сразу проверять выполнение этих правил и накапливать статистику по нарушениям. Например, цена за литр бензина на АЗС в России сегодня не может выходить за пределы от 40 до 70 рублей. Если выходит — значит, данные неверны, и об этом нужно сразу сигнализировать. Вместе с пользователями вырабатываются тысячи правил, при которых данные становятся качественными, то есть пользующимися максимальным доверием. Система позволяет управлять единым реестром всех правил по качеству данных, видеть в нем противоречия и пробелы, устанавливать метрики и отслеживать комплексную статистику. Мировая практика говорит о том, что внедрение подобной системы позволяет организации в течение 3 лет улучшить качество данных на 60%, что существенно снижает операционные затраты и риски.
Бизнес-глоссарий, пользовательский портал — максимально понятные каждому сотруднику инструменты для поиска бизнес-данных. Как и в случае с каталогом данных, наполнение бизнес-глоссария займет продолжительное время, но все инструменты уже запущены в эксплуатацию. Если все сотрудники будут пользоваться единым словарем и каталогом, это создаст единый язык и единую культуру работы с данными, а значит реализация проектов будет проходить значительно быстрее.
Представление о платформе, как об источнике достоверных данных очень важно. Это именно то свойство, благодаря которому использование подобных решений позволяет снизить затраты на реализацию проектов, связанных с аналитикой. Дополнительная ценность такого источника состоит в том, что он самонаполняемый. Каждая реализованная задача добавляет новые данные в систему, причем эти данные верны по определению, понятны и удобны в использовании.
Кроме того, платформа включает готовые аналитические «песочницы» — специально выделенную среду для безопасного исполнения математических алгоритмов. Они нужны для построения прототипов и проверки гипотез на основе данных. Теперь песочницы становятся доступны специалистам в течение одного дня, тогда как ранее их организация занимала 2–3 месяца.
Благодаря платформе ускорится и сам процесс запуска новых продуктов и решений. Наличие большого числа готовых, открытых и хорошо описанных данных, собранных в одном месте и отформатированных, позволяет гарантировать короткое время их предоставления и уже к концу 2020 года сократить срок их поставки до 2 дней.
Как розница использует данные на практике?
Первыми кейсами комплексной платформы стали обработка операций сети АЗС «Газпромнефть» и обратной связи от покупателей, расчет сегментов для клиентской аналитики. Для построения аналитических решений в озеро данных интегрированы данные внешних источников: Санкт-Петербургской товарно-сырьевой биржи, метеорологических источников, метрик и отзывов сервисов Яндекса, Google и App Store, сайтов ЦБ России и СНГ, а также открытая информация соцсетей и мобильных приложений, различные сведения партнеров и данные о конкурентах.
Какую пользу получает бизнес от платформенных решений с элементами искусственного интеллекта? Большие структурированные и верифицированные данные помогают разрабатывать максимально персонализированные предложения для клиентов. К примеру, сеть АЗС «Газпромнефть» запускает акцию: клиент получает скидку на каждый заправленный литр топлива G-Drive 100. Среди тех, кто воспользовался скидкой, часть клиентов давно не заправлялась на АЗС «Газпромнефть», и скидка стала эффективным стимулом вернуться. Другие заправляются обычным девяносто пятым, и благодаря акции не упустили шанса получить более премиальное топливо. Третья группа клиентов регулярно заправляется G-Drive 100, они не принесут компании дополнительной прибыли, ведь и так бы заправились, но теперь сделали это со скидкой.
Умное озеро данных позволяет детально анализировать потребительские предпочтения и делать выводы на основе огромного числа данных: регулярность заправки, время и день недели, погодные условия, изменение цен на топливо и курса валют, действия конкурентов. При помощи анализа потребительских предпочтений каждого клиента компания получает инструмент для составления максимально кастомизированного предложения, снижая эффект стрельбы из пушки по воробьям и повышая результативность маркетинговых кампаний. Предложение заправиться сотым бензином со скидкой в виде пуш-уведомлений в смартфоне получат только первые две категории клиентов, тогда как для третьей группы будет сделано другое, более релевантное предложение.
Более того, для запуска каждой следующей маркетинговой акции будет нужно все меньше времени, ведь в озеро уже будут загружены необходимые исходные данные, в том числе, поступающие автоматически на постоянной основе. Умный алгоритм способен не только на их базе сгенерировать математически идеальное предложение клиенту, но даже предсказать необходимость разработки этого предложения. Например, диагностировав снижение прокачки на определенной АЗС или предсказывая грядущее изменение спроса на основе повторяющихся событий в течение последних нескольких лет.
Заинтересовала статья? Или вам интересны другие темы? Оставляйте свои комментарии - нам важно знать ваше мнение.
Ранее мы уже писали об использовании цифровых технологий в нефтяной отрасли и о том, что такое цифровая АЗС.
Оригинал статьи и другие материалы читайте на сайте журнала: www.gazprom-neft.ru/press-center/sibneft-online/ или просто www.sibneft.ru