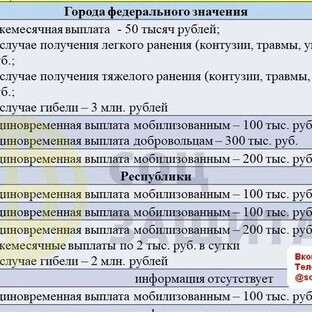
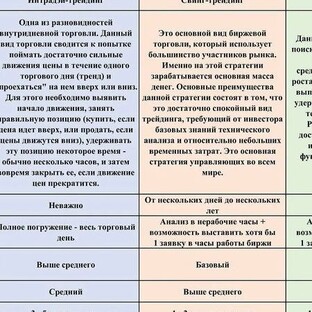
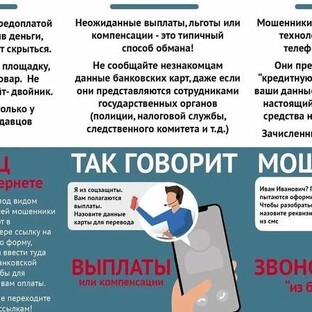
Как и многие быстро развивающиеся концепции, большие данные были определены и введены в действие по-разному, начиная от банальных заявлений о том, что большие данные состоят из наборов данных, слишком больших для использования в таблице Excel, для хранения на одной машине, и заканчивая большим количеством данных.
- Другими словами, большие данные обозначаются не просто объемом. Действительно, промышленность, правительство и научные круги уже давно создают массивные массивы данных, например, национальные переписи населения. Однако, учитывая затраты и возможности генерирования, обработки, анализа и хранения таких наборов данных, эти данные были получены строго контролируемым образом с использованием методов выборки, которые ограничивают их охват, временность и размер.
- Для удобства сбора данных переписи они подготавливаются раз в пять-десять лет, задавая всего 30-40 вопросов, и их результаты обычно довольно грубые. Кроме того, методы, используемые для их создания, весьма негибки. Хотя цель переписи - быть исчерпывающей и охватывать всех людей, проживающих в стране, большинство обследований и других форм сбора данных являются выборочными и должны быть репрезентативными для населения.

Напротив, Big Data характеризуется непрерывной генерацией, стремлением быть исчерпывающим и мелкозернистым по объему, гибким и масштабируемым в своем производстве. Примеры производства таких данных включают: цифровое видеонаблюдение; регистрацию розничных кошельков; цифровые устройства для записи и передачи истории их собственного использования (например, мобильные телефоны); регистрацию операций и взаимодействия в цифровых сетях; данные, регистрирующие навигацию через веб-сайт или приложение; измерения с помощью встроенных в объекты или среду датчиков; сканирование объектов считывания. Они создают массивные, динамичные потоки разнообразных, мелкозернистых, реляционных данных.
Хотя производство таких больших данных существует в некоторых областях, таких как дистанционное зондирование, прогнозирование погоды и финансовые рынки, в течение некоторого времени ряд технологических достижений, таких как повсеместное компулирование, широкое распространение Интернета и новые разработки баз данных и решения для их хранения, создали переломный момент для их регулярного создания и анализа, в том числе новые формы анализа данных, предназначенные для решения проблемы избытка данных.
- Традиционно методы анализа данных разрабатывались для извлечения информации из скудных, статических, чистых и плохо реляционных наборов данных, отобранных на научной основе и придерживающихся строгих предположений, а также для генерирования и анализа с учетом конкретного вопроса. Задача анализа огромных данных состоит в том, чтобы справиться с избытком, полнотой и разнообразием, своевременностью и динамичностью, запутанностью и неопределенностью, высокой реляционностью и тем фактом, что большая часть генерируемых данных не имеет конкретного вопроса или является побочным продуктом другой деятельности.
До недавнего времени такой вызов был слишком сложным и сложным для реализации, но стал возможным благодаря мощным вычислениям и новым аналитическим методам. Эти новые методы основаны на исследованиях, касающихся искусственного интеллекта и экспертных систем, целью которых является создание машинного обучения, которое может вычислительным и автоматическим образом определять закономерности, создавать модели прогнозирования и оптимизировать результаты.

Несомненно, что разработка наибольших данных и новой аналитики данных открывает возможности для переосмысления эпистемологии науки, социальных и гуманитарных наук, и такая переосмысление уже активно осуществляется в различных дисциплинах. Большие объемы данных и новая аналитика данных позволяют применять новые подходы к сбору и анализу данных, что дает возможность задавать новые вопросы и отвечать на них по-новому. Вместо того, чтобы пытаться извлечь информацию из наборов данных, ограниченных по объему, времени и размеру, Big Data решает проблему обработки и анализа огромных, динамичных и разнообразных наборов данных. Решение заключалось в разработке новых форм управления данными и аналитических методов, основанных на машинном обучении и новых режимах визуализации.
Что касается науки, то доступ к большим данным и новые методы исследований привели к тому, что некоторые из них провозгласили появление новой четвертой парадигмы, которая уходит корнями в наукоемкие исследования, ставящие под сомнение устоявшийся научно-дедуктивный подход. В настоящее время ясно, что Большие данные являются революционной инновацией, открывающей возможность нового подхода к науке, однако форма этого подхода не определена, поскольку существуют два возможных пути, которые имеют различную эпистемологию - эмпирические, в рамках которых данные могут говорить сами за себя без теории, и основанные на данных научные исследования, радикально изменяющие существующие научные методы путем смешения аспектов похищения, индукции и деструкции. Учитывая слабые стороны эмпирических аргументов, представляется вероятным, что подход, основанный на данных, в конечном итоге одержит победу и со временем, по мере распространения больших данных и совершенствования новой аналитики данных, станет мощным стимулом для внедрения устоявшегося научного метода, основанного на знаниях.
Для сопровождения таких преобразований необходимо проработать и обсудить философские основы науки, основанной на фактических данных, в том, что касается ее эпистемологических принципов, принципов и методологии, с тем, чтобы заложить прочную теоретическую основу для новой парадигмы.