Начнем сначала
Представьте: вы работаете аналитиком. Ваша компания начала сотрудничать с МФЦ, и вы получили задание: смоделировать, как скорость выполнения услуги влияет на оценку со стороны клиентов. Клиенты не особо охотно ставят оценку или не знают о такой возможности, но однажды вы всё-таки собираете данные 190 человек и готовы приступить к их анализу.
Правда, есть один фактор: данные собраны не из одного отделения МФЦ, а из 19 разных, раскиданных по всему городу. Или даже по нескольким. Это потенциальный источник дополнительной изменчивости ваших данных: возможно, есть какие-то важные различия среди клиентуры, или среди сотрудников МФЦ, или относительно общей культуры места. Это то, что вы просто не можете проигнорировать и не включить в модель.
Однако при попытке включить этот фактор в модель, начинаются проблемы. Во-первых, вместо одной общей линии у вас теперь 19 разных, и оценить общий тренд по ним непросто. Во-вторых, мы теряем возможность генерализации результатов на другие отделения — мы настроили наши модели именно на эти 19 отделений, а ведь их намного больше. Наконец, в каждой подвыборке в среднем будет 10 человек, что уничтожит нашу статистическую значимость, если модель вообще захочет считаться.
Так ваша жизнь скатывается в разнообразную и удивительную. Всё портит статистический фактор, который вы не можете игнорировать. Особенный, которого вы не можете не пригласить на праздник. Что же с этим делать?
Meet the LMM
Встречайте, группу методов под именем «линейные модели со смешанными эффектами» (LMM, linear mixed-effects models). Иногда их можно встретить под другими именами — многоуровневые или иерархические модели. Однако, суть та же — они созданы для ситуаций, когда:
- Наши данные можно разделить на подгруппы
- Эти подгруппы уже закодированы в виде переменной
- Мы хотим генерализовать наши данные на те подгруппы, которые родственны имеющимся, но не присутствуют в датасете
- Нам интересна вариабельность, связанная с этими подгруппами
- Наблюдения внутри групп скоррелированы (похожи друг на друга)
Последнее является центральной идеей, встроенной в LMM: мы применяем их тогда, когда есть основания полагать схожесть наблюдений внутри групп. Одно из наиболее частых применений LMM – лонгитюдные исследования, когда мы повторно измеряем какие-то объекты на протяжении длительного времени. В конце концов, данные одного и того же объекта наверняка похожи друг на друга. Так что LMM часто используются как замена дисперсионному анализу с повторными измерениями.
Обо всём по порядку.
Почему «смешанные эффекты»?
К эффектам относятся все коэффициенты линейной регрессии (свободный член/интерсепт и углы наклона). Однако, согласно теории LMM, не все эффекты рождаются равными. Их можно разделить на две категории – фиксированные и случайные.
Фиксированные эффекты являются общими для всей выборки, вне зависимости от подгруппы. С высокой вероятностью это и есть изначальный запрос вашего исследования. Возвращаясь к примеру во введении, это «как скорость выполнения услуги влияет на оценку со стороны клиентов», выраженное соответствующими коэффициентами регрессионной прямой.
Случайные эффекты отражают дополнительную изменчивость в наших данных. Они показывают, как фиксированные эффекты изменяются на уровне отдельных подгрупп и насколько сильно. В нашем случае это, например, «как меняется взаимодействие между скоростью и оценкой в зависимости от отделения МФЦ».
Таким образом, через смесь фиксированных и случайных эффектов мы получаем модель, которая оценивает общий тренд в наших данных с поправкой на случайную вариабельность, а также позволяет делать индивидуализированные предсказания для отдельных подгрупп. При этом не происходит потери статистической мощности, как в случае построения отдельных регрессионных прямых.
Основные допущения
Главное нововведение: LMM предполагают нормальность распределения случайных эффектов. В остальном — это почти тот же набор, что и с классической линейной регрессией:
- Линейность взаимосвязи независимой и зависимой переменных (НП и ЗП)
- Нормальность распределения остатков
- Гомоскедастичность остатков (схожая дисперсия на всех уровнях НП)
- Отсутствие мультиколлинеарности, т.е. слишком сильной корреляции между независимыми переменными
В классической линейной регрессии есть также допущение о независимости наблюдений. Именно его снимают LMM — они как раз построены на идее, что наблюдения могут быть зависимы друг от друга посредством их принадлежности к подгруппам.
Как это сделать в Python?
Начнём с импорта нужных пакетов:
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
Pandas традиционно нужен нам для импорта данных и манипуляций с ними. numpy играет чисто вспомогательную роль. В центре внимания — statsmodels, в котором мы и будем строить наши модели. Его мы импортируем его дважды из-за двух разных API: некоторые функции доступны в одном и недоступны в другом. С этим нужно просто жить.
Перейдём к нашему набору данных. Скачать его можно отсюда, описание данных тут.
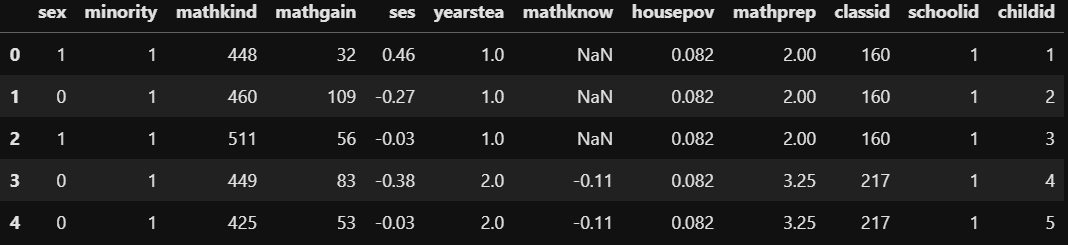
В данном исследовании рассматривались ученики начальных школ в США. Они проходили тест на знание математики в детском саду, а затем выполняли его же в первом классе школы. Прирост (или убывание) баллов относительно результата в детском саду указан в переменной mathgain и является ЗП нашего исследования. Помимо этого, есть ряд других показателей в качестве НП, но мы на данный момент возьмём только три из них:
- баллы по математике в детском саду (mathkind)
- индекс социально-экономического статуса ученика (ses)
- количество контента по математике в первом классе (mathprep)
Классика
Сначала построим классическую линейную регрессию без учёта каких-либо подгрупп:
model_lm = smf.ols('mathgain ~ mathkind + ses + mathprep', data = classes).fit()
model_lm.summary()
Разберём по частям каждый кусочек кода:
- smf.ols() — функция, которая строит нашу линейную модель.
- Первый аргумент — формула модели. Она реализуется через пакет Patsy и имитирует схожий синтаксис на языке R. Основной формат формулы выражается как
- «ЗП ~ НП1 + НП2 + … + НПn», более подробно можно посмотреть в описании пакета.
- Второй аргумент — data , обозначающий набор данных. Он у нас называется classes.
- После спецификации модели используем метод .fit(), чтобы построить модель.
- На получившейся модели применяется .summary() для получения нужной информации.
После метода .summary() появляется следующая таблица (уменьшенная нами для экономии места):
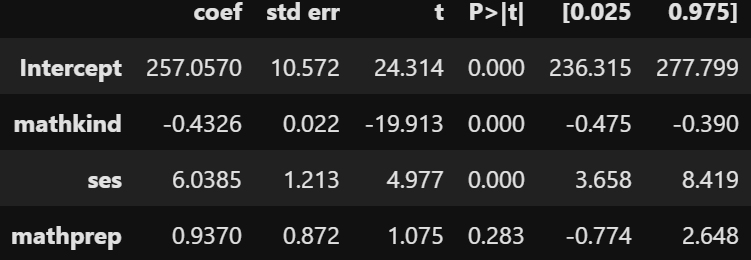
По вертикали находятся НП, а на первом месте стоит свободный член уравнения (Intercept).
По горизонтали:
- coef — значение каждого коэффициента
- std err — стандартная ошибка
- t — t-статистика каждого коэффициента
- P>|t| — p-значение (должно быть меньше 0.05)
- 0.025 — нижняя граница доверительного интервала
- 0.975 — верхняя граница доверительного интервала
О чём нам говорят эти данные? Во-первых, количество контента не влияет значимо на прирост баллов. Во-вторых, у нас отрицательная взаимосвязь с изначальным количеством баллов (чем выше баллы в детском саду, тем ниже их прирост). В-третьих, у нас положительная взаимосвязь с социально-экономическим статусом (чем он выше, тем выше и прирост баллов).
В принципе, уже выглядит неплохо, да? Однако не забывайте, что это данные из нескольких разных школ! Вполне возможно, что ученики из одной школы больше похожи друг на друга, чем из разных, и мы не можем игнорировать потенциальную вариабельность в наших данных. Тем более что наша линейная модель уже что-то подозревает:
На этом моменте мы, наконец, переходим к LMM. Можно построить три основных типа модели:
Случайный свободный член (random intercept)
Мы можем предположить, что характер взаимосвязи во всех школах одинаков, но средние значения прироста меняются от школы к школе. Для этого мы строим модель, где со свободным членом связан случайный варьирующийся эффект. Визуально это выглядит примерно так:
Эту модель мы строим с помощью кода:
model_rintercept = smf.mixedlm('mathgain ~ mathkind + ses + mathprep',
data = classes, groups = classes['schoolid']).fit(method='cg')
model_rintercept.summary()
Что изменилось по сравнению с прошлым кодом:
- Новая функция - smf.mixedlm().
- Аргумент groups, в который мы передаем массив с обозначениями наших подгрупп. В данном случае это переменная schoolid.
- В методе .fit() появился аргумент method. Дело в том, что LMM могут быть достаточно капризны и не сходиться на правильном решении (с выдачей сообщения с предупреждением). Зачастую это проблема алгоритма оптимизатора, и в случаях несходимости начинается игра «угадай, какой оптимизатор не даст предупреждения». Полный список можно увидеть вот тут, но в большинстве случаев работают варианты сg и lbfgs.
Посмотрим, что у нас получилось:
В этот раз немного изменились значения коэффициентов, а также появился дополнительный Group Var. Он отражает дисперсию наших свободных членов по школам. Мы можем перевести дисперсию в стандартное отклонение, взяв квадратный корень:
np.sqrt(model_rintercept.cov_re)
Результат равен примерно 10.17 — то есть между школами разброс свободных членов составляет 10 баллов. Учитывая, что стандартное отклонение прироста по всей выборке составляет 34.6 баллов, это не много, но всё равно потенциально интересно.
Случайные свободный член и угол наклона (random intercept and slope)
Следующее предположение: что, если и характер/сила взаимосвязи меняется в зависимости от школы? В таком случае одним случайным свободным членом не обойтись – нужно добавить случайный эффект и для угла наклона по какой-либо НП! Тогда у нас выйдет модель, которая визуально выглядит как-то так:
Проверим, как меняется эффект социально-экономического статуса в зависимости от школы:
model_rslope = smf.mixedlm('mathgain ~ mathkind + ses + mathprep',
data = classes, groups = classes['schoolid'],
re_formula = '~ses').fit(method='lbfgs')
model_rslope.summary()
Здесь у нас добавляется новый аргумент re_formula, где в формате односторонней формулы (без ЗП) указываем те переменные, по которым будет варьироваться угол наклона (в данном случае переменная ses). Посмотрим на результат:
Эффект социально-экономического статуса уменьшился, а также добавились переменные ses Var, дисперсия углов наклона, и Group x ses Cov, выражающая степень взаимосвязи (ковариацию) между случайным свободным членом и случайным углом наклона. Переводим это в корреляцию по формуле:
В результате получается корреляция в 0.69 – сильная положительная корреляция! Можно сказать, что в тех школах, где в среднем выше прирост, также сильнее положительный эффект социально-экономического статуса.
Случайный угол наклона (random slope)
Как правило, на практике нужны только два вышеуказанных типа моделей. Однако мы можем решить, что случайный свободный член нам не очень и нужен, и оставить только случайный угол наклона. Визуально модель можно представить так:
Для этого в аргументе re_formula перед переменными нужно поставить 0 – это удалит случайный свободный член:
model_zintercept = smf.mixedlm('mathgain ~ mathkind + ses + mathprep',
data = classes, groups = classes['schoolid'],
re_formula = '~ 0 + ses').fit(method='cg')
model_zintercept.summary()
Смотрим на результат:
Как видите, Group Var пропала, зато ses Var увеличилась почти вдвое!
Какая модель лучше?
Сравнение происходит при помощи информационных критериев – как правило, это критерии Акаике и Шварца/байесовский. Они исполняют роль индексов относительного качества модели: сами по себе смысла не несут, но отражают в себе превосходство одной модели над другой. Выбирать надо ту модель, у которой значение критерия меньше.
Однако если вы попробуете извлечь из наших LMM эти метрики, то не получите ничего. Жизнь жестока и несправедлива. Почему так?
Причина кроется в методе, с помощью которого подбираются параметры нашей модели. В обычных линейных моделях используется та или иная версия метода максимального правдоподобия (Maximum Likelihood, ML), но LMM хитрее - в них по умолчанию используется метод ограниченного максимального правдоподобия (Restricted Maximum Likelihood, REML). Он справляется гораздо лучше и даёт более адекватную модель, но берёт страшную плату – информационные критерии при этом методе перестают работать.
Решается проблема просто – нужно построить наши модели заново, но уже классическим методом ML. Для этого в .fit() нужно указать аргумент reml = False:
model_rintercept_2 = smf.mixedlm('mathgain ~ mathkind + ses + mathprep',
data = classes, groups = classes['schoolid']).fit(method='cg',
reml = False)
model_rslope_2 = smf.mixedlm('mathgain ~ mathkind + ses + mathprep',
data = classes, groups = classes['schoolid'],
re_formula = '~ses').fit(method='cg', reml = False)
model_zintercept_2 = smf.mixedlm('mathgain ~ mathkind + ses + mathprep',
data = classes, groups = classes['schoolid'],
re_formula = '~ 0 + ses').fit(method='cg', reml = False)
Теперь можно взглянуть на значения информационных критериев!
Как видите, последняя модель (только со случайным углом наклона) справляется хуже всего – видимо, свободный член является более важным коэффициентом в данном случае. Это видно и при сравнении первых двух моделей – у них очень похожие значения AIC, но более сложная модель чуточку хуже.
Таким образом, из всех наших моделей модель случайного свободного члена – самая адекватная.
Неужели это всё?
Вовсе нет! На этом моменте я завершаю первую часть своего нетехнического введения в LMM, чтобы вы могли осознать произошедшее и с новыми силами взяться за изучение этой интересной темы.
А пока подписывайтесь на Дзен Karpov.Courses и следите за обновлениями!