Вы, вероятно, встречали в материалах, связанных с программированием, что-то похожее на O(n) или O(log n). Если вы знаете, что это, то дальше можете не читать. В противном случае вы, наверное, просто пропускали эти буквы мимо, так как либо не понимали, о чём речь, либо вас это просто не интересовало. Во всяком случае, так я и делал.
Знать об этом, однако, очень полезно как в концептуальном, так и в практическом плане. Каждый раз, когда мы пишем алгоритм, у него есть какая-то сложность. Что нужно о ней знать?
Предположим, вы суммируете элементы одномерного массива размером N. Вы берёте первое значение маccива и складываете со вторым. Это одна операция. Затем вы к полученной сумме добавляете третье значение. Это вторая операция. Затем ещё одно значение – ещё одна операция, и т.д. Итого вы сделали N операций сложения (точнее, N-1, но это неважно, и дальше мы увидим, почему).
Обращаю внимание: это чисто логические операции. Не машинные. Одна логическая операция может состоять из любого количества машинных.
Теперь вы суммируете значения матрицы размером N*N. Вы беретё первое значение... в общем всё то же самое, только теперь надо выполнить N*N операций.
Оба этих алгоритма отлично работают при, допустим, N = 5. При суммировании массива длиной 5 вы делаете 5 операций, при суммировании матрицы 5*5 вы делаете 25 операций.
25 это в 5 раз больше, чем 5, но и то и другое для компьютера – легко. Но что, если N = 1000? Теперь для массива нужно выполнить 1000 операций, а для матрицы МИЛЛИОН операций. И разница становится уже не 5, а 1000 раз. А если N = 1000000? Разница составит уже миллион раз. Если суммирование массива выполняется одну секунду, то суммирование матрицы будет выполняться миллион секунд (11 суток). То есть в какой-то момент операций для матрицы потребуется так много, что применять этот алгоритм станет уже нельзя.
Зависимость количества операций от N и называется вычислительной сложностью алгоритма. То есть это сложность не в плане того, насколько интеллектуально и сложно устроен алгоритм. Это просто и грубо количество операций, нужных для его выполнения.
И это количество операций надо уметь оценивать. Причина очевидна: вы должны знать, на каких N ваш алгоритм будет работать удовлетворительно, а на каких нет. И значит, в каких задачах алгоритм применять можно, а в каких нет.
В оценке нас интересует не само количество операций, а то, как оно будет расти, если мы начнём увеличивать N. Скажем, при сложении значений одномерного массива мы, задав любое N, получаем столько же операций. Такая зависимость записывается как O(N).
O – это от слова Order, то есть порядок. O(N) значит, что для выполнения выбранного нами алгоритма с параметром N потребуется порядка N операций.
Теперь можно оценить сложение значений матрицы, и мы получим порядок O(N*N), или O(N²). Это значит, что при увеличении N количество операций будет увеличиваться в квадрате.
Именно поэтому точное значение N неважно. Выше речь шла об N-1, но -1 там никакой роли играть не будет. Важен лишь сам порядок. Это не формула, это оценка.
Также неважны для оценки любые коэффициенты и константы, которые теряют свою значимость при стремлении N в бесконечность.
Поэтому сложность алгоритмов называют асимптотической. Асимптота это прямая линия, к которой стремится график функции при удалении в бесконечность.
Допустим, при каждом сложении в матрице вы совершаете не одну операцию, а три. И кроме того, перед тем как начать складывать, вы тратите 1000 операций на подготовку. То есть оценка должна получиться O(N* 3 * N * 3 + 1000), или O(N² * 9 + 1000). Но оценка всё равно будет O(N²), потому что коэффициент 9 и константа 1000 не играют роли при N→∞. Квадрат растёт гораздо быстрее, чем умножение на 9, про константу и речи нет. Соответственно в оценку порядка входит только то, что влияет наиболее сильно, а именно квадрат.
Как известно, шутки с квадратами очень плохи. Если ваш алгоритм имеет оценку O(N²), то это практически приговор. Его нельзя будет масштабировать для достаточно больших N.
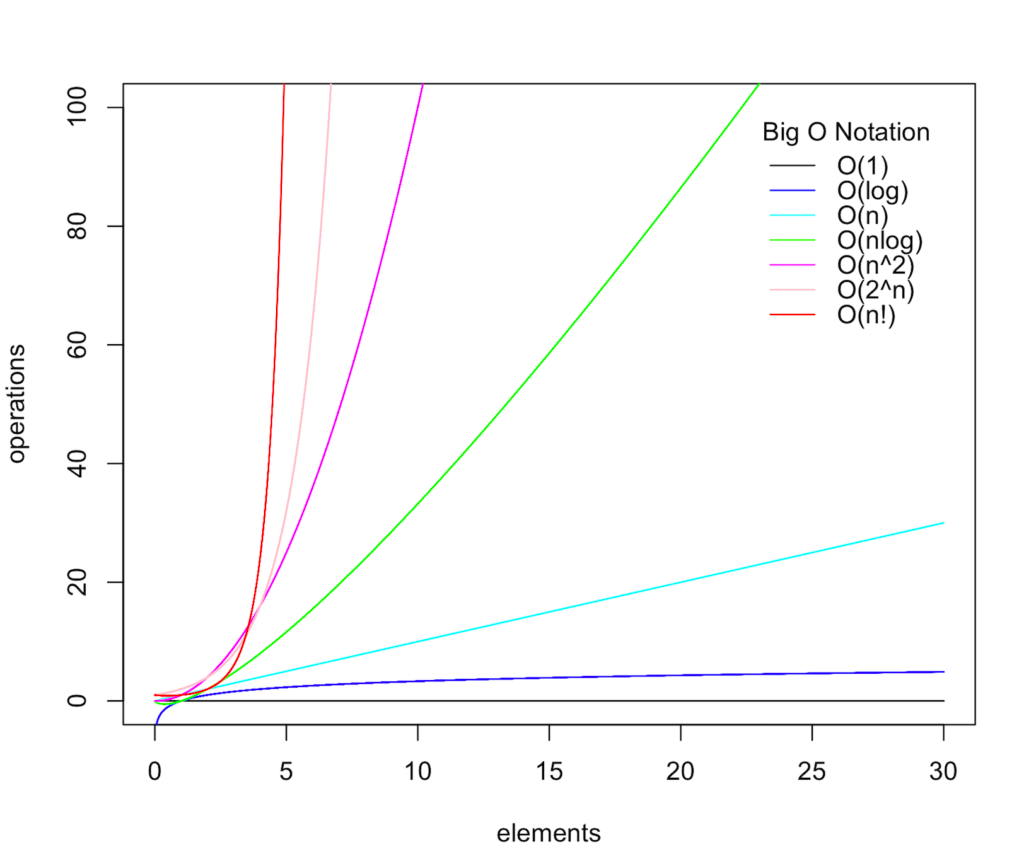
Но бывают варианты и хуже, например O(N³) или O(N!). Посмотрите на график и ужаснитесь. А самый желанный вариант это O(1). Да, это константная оценка – одна операция для любого N. Прекрасно, идеально. Что мы можем так оценить? Например, выбор из матрицы случайного элемента. Он будет работать всегда одинаково при любом размере матрицы.
Также поиск элемента в хеш-таблице имеет оценку в лучшем случае O(1). Худший случай это обычно O(N), но в среднем получается неплохо. В принципе многие алгоритмы имеют лучший и худший случай, которые зависят от того, как сформированы входные данные. И естественно, что для каждого случая может быть своя оценка. Выбирая какой-либо алгоритм, вы также оцениваете риски – как он поведёт себя на вашем конкретном наборе данных. Например, вы можете выбрать некий супер-быстрый алгоритм, но именно у вас он будет работать крайне медленно из-за того, что ваши данные являются для него худшим случаем. А вот какой-то более медленный алгоритм работал бы в худшем случае лучше.
O(N) также весьма неплохой вариант в большинстве случаев. Если же вы получили O(N²), O(N³), O(N!) или ещё хуже, то причина тут либо в том, что задача в принципе не решается никак иначе, либо же выбран неоптимальный алгоритм.
Читайте дальше: Методы сортировки и их вычислительная сложность