О себе
Я достаточно опытный программист. Сейчас Big Data Solution Architect. Последние пять лет специализируюсь только на Big Data решениях, а последние 10 лет на высоконагруженных и распределенных системах.

Об этом журнале
Не буду скрывать, что уже не раз пытался подступиться к теме Data Science. Первый раз пробовал (и достаточно успешно) года 4 назад - как результат детектор аномалий в одном из проектов. Далее было затишье и несколько попыток "каждый раз как в первый раз". Этот журнал - попытка дисциплинированно подойти к вопросу и осветить этот путь для других. Плюс стоит понимать, что я постоянно сталкиваюсь с Data Science областью в профессиональной среде, либо на проектах, либо в кулуарах пересекаясь с ML инженерами или Data Scientist'ами. Описанный здесь материал не ограничевается пересказом пройденных мной материалов, хотя в большей степени основывается на них.
Статьи будут выходить по понедельникам и четвергам. Так что подписывайтесь на мой журнал и делитесь им со своими друзьями. Стоит ли говорить как это мотивирует автора на дальнейшие подвидиги.
О Data Science и почему это мне интересно
Data Science - это следующий уровень возможностей в обработке данных.
1) Подавляющее большинство разработчиков работают с данными на уровне CRUD операций в базе данных - сохранить данные(Cread), прочитать данные(Read), обновить(Update) и удалить(Delete).
2) Следующий уровень в обработке данных - это простейший, а иногда не очень статистический анализ и аггрегация (выбрать максимальное значение в сгруппированных по какому-то признаку данных). До какого-то момента весь back-end, BI и Big Data миры ограничивались именно этим уровнем.
3) Относительно недавно (скажем лет 5 как) большие данные дали новый толчок применению Data Science подходов обработки на практике. Большие объемы данных позволили достичь большей точности у Data Science моделей. А Data Science модели позволили выжать из данных максимум - заметить ошибку в вашей бухгалтерии там где никто ее не ждет, предсказать появление проблем в логистике доставки продуктов, предложить как оптимизировать ваши издержки - и все это автоматически 24/7.
Не стоит конечно переоценивать эту область, но и недооценивать не стоит - практически все крупные и не очень компании используют Data Science, начиная с небольшого супермаркета в вашем доме, заканчивая нефтенными компаниями и банками. Я думаю стало понятно, почему меня эта область так сильно заинтересовала, что я даже завел блог. Я предвижу только рост популярности и зон ответственности Data Science области. Я хочу понимать, что и как там происходит, чтобы просто оставаться актуальным на передовой IT в ближайшем будущем.
Роли в Data Science команде
Уже сейчас сформировалась небольшая иерархия ролей приближенных к анализу данных. Необязательно быть Доктором наук в математике, чтобы преуспеть.
В рядовой компании, которая имеет хранилище данных есть data-инженеры и BI-инженеры. Грань между ними весьма условна, но если утрировать, то data-инженеры занимаются построением платформы данных, интеграцией разных систем с хранилищем и автоматизацией обработки данных внутри хранилища. Bi-инженеры имеют большее представление о бизнесе и используя данные хранилища строят отчеты с необходимой для бизнеса информацией (как правило используя SQL интерфейс к данным, которые подготовила команда data-инженеров).
Параллельно с этими ребятами трудится Data Science команда, которая используя те же данные, но как правило не только SQL интерфейс, а более эффективный и низкоуровневый доступ к данным, создает модели и новые датасеты, которые опять же data-инженеры и BI-инженеры будут использовать для своих задач. Data Science команда как правило состоит из Machine Learning инженеров и Data Scientist'ов, где первые пробуют уже реализованные в каких-нибудь Data Science framework'ах модели, настраивают их, оптимизируют и получают результат либо формируют понимание, что готовых решений не достаточно. Data Scientist'ы - это уже тяжелая артилерия, которые скорее про науку, чем про инженерию. Именно они берут дело в свои руки, если задачу нельзя решить на уровне Machine Learning инженера.
Процесс разработки в Data Science
В общем смысле Data Science не ограничивается построением модели. Методология разработки формализована и имеет наименование CRISP-DM (cross-industry process for data mining).
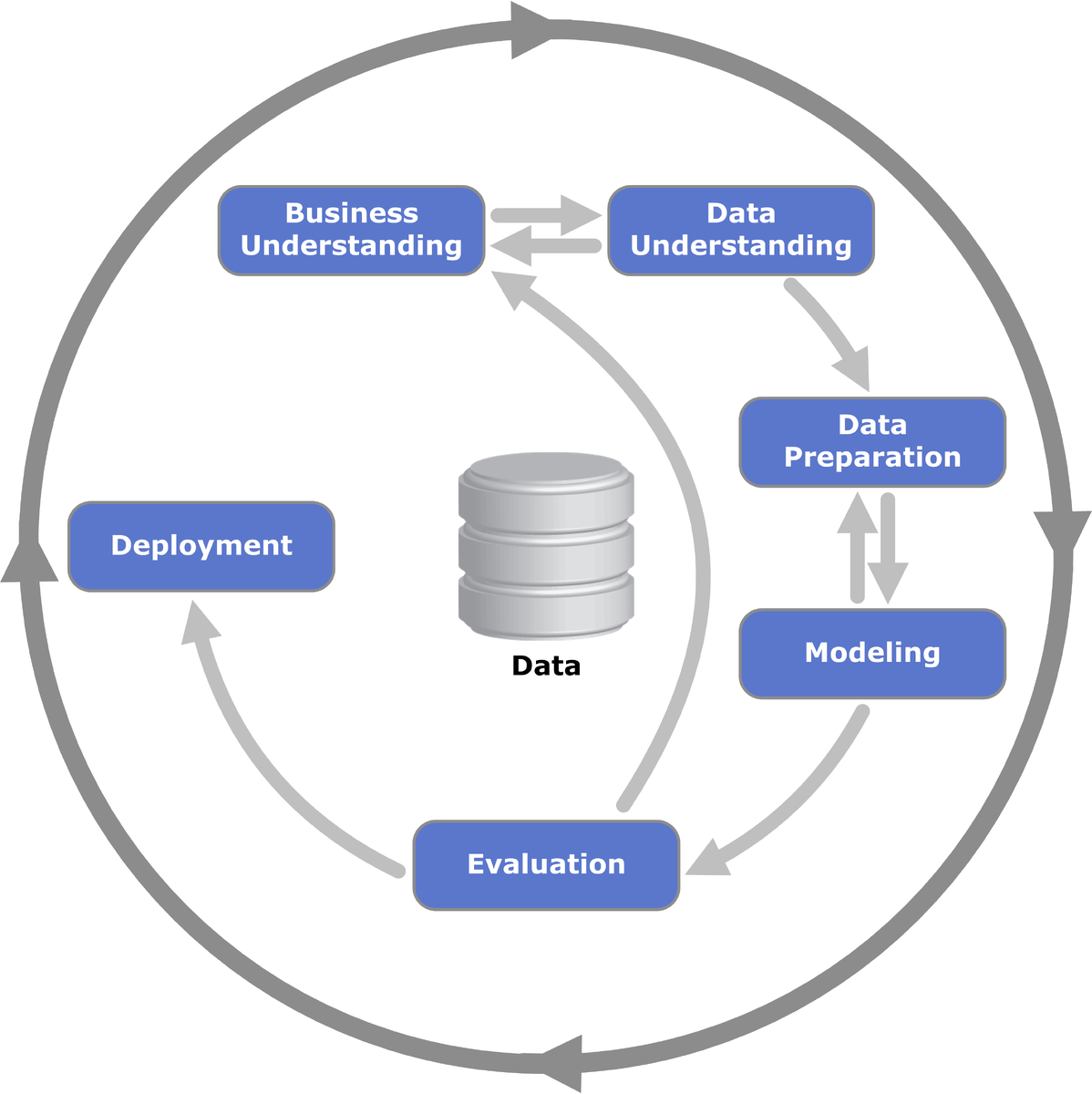
1) Обычно процесс начинается с анализа данных, с так называемого exploratory data analysis (знакомство с бизнес спецификой, закомство с данными, определение логически зависимых данных, потенциальных фич для разных моделей).
2) Следующий этап - подготовка данных (убирание дупликатов, мусора, преобразование типов данных, заполнение пропусков, убирание явных outlier'ов и т.д.).
3) Далее начинается, собственно, само моделирование (feature engineering, выбор модели, ее обучение, проверка, оптимизация).
4) Вывод в production может выглядеть очень по-разному, например, модель может деплоится в виде REST сервиса внутри Docker-контейнера, который запускается на каком-нибудь AWS SageMaker или Kubernetes кластере.
5) Модель в production'е обязательно должна мониториться, а результаты анализироваться, так как следующая модель как и любое ПО так или иначе устаревает и в следующий раз было бы неплохо формировать backlog основанный на конкретных цифрах.
Прежде чем начать
Прежде чем уйти с головой во всякие там регрессии и кластеризации, потратим немного времени, чтобы привыкнуть к технологическому стеку и освежить в памяти базовые математические понятия.
Из опыта скажу, что достаточно распространены следующие технологии:
1) Табличный процессор. Выборки или промежуточные результаты достаточно часто распространяются в виде Microsoft Excel таблицы. В особых случаях модель реализуется целиком в Microsoft Excel на костылях и подпорках.
2) Matlab, Octave и любой другой математический процессор. Людям с научным бэкграундом проще ряд вещей написать прямо в виде математических формул. Какие-то очень низкоуровневые вещи в Data Science наверное проще начать разрабатывать именно здесь.
3) Язык R и его экосистема. R изначально разрабатывался для статистического анализа, далее сильно расширен под Data Science направлении. Невероятное количество библиотек, есть ряд узкоспециализированных, написанных только под R.
4) Python и его экосистема. Python имеет простой синтаксис, динамическую типизацию и неплохую для интерпретируемого языка производительность. Большая часть Data Science мира построена вокруг этого языка. Фактически стандарт де-факто с кучей библиотек и поддержкой технологическими гигантами.
5) Scala и по большей части Spark ML. Spark ML - это Machine Learning библиотека построенная поверх Apache Spark, соответственно реализованные там ML модели априори горизонтально масштабируемы и более того последние версии Apache Spark умеют работать поверх GPU.
Зачастую на одном и том же проекте используется сразу несколько инструментов под разные задачи, а не забивается всё одним молотком.
А математика?
Что касается математики, то с одной стороны можно многое из Data Science использовать без какого либо понимания в математике вообще. Многое уже реализовано в виде framework'ов и библиотек, так что запустить какую-то модель с подобранными параметрами без знания математики вполне возможно. Другое дело, что это вероятно будет неэффективно, а на каком-то уровнее вообще невозможно, так как вариативность практически бесконечная. Но на начальном этапе, отсутствие математики будет скорее походить на незнание hash-алгоритмов и того как работает структура Hash Table с точки зрения программиста, который ее использует.
Я предпочту не ограничивать себя насильно и на математические концепции глаза закрывать не стану. Так что совсем базовые вещи вспомнить также придется.