В последнее время я много пишу об анализе данных с помощью Python. Хочу поделиться с вами, почему именно этот язык покорил мое сердце. Вот несколько причин, по которым Python стал для меня не просто инструментом, а настоящим союзником в работе с данными.
Python превращает сложные вычисления в детскую игру
Python позволяет мне выполнять статистические вычисления в разы быстрее, чем я когда-либо мог представить. Когда я только начинал изучать статистику в университете, приходилось вручную рассчитывать базовые показатели — среднее значение, медиану, стандартное отклонение. Объем данных делал эту работу мучительной даже с научным калькулятором. Постоянно терзали сомнения: а правильно ли я ввел все эти цифры? Тогда я переключился на графический калькулятор TI — в учебнике как раз показывали статистические функции для этой модели.
Думаю, мой графический калькулятор до сих пор пылится где-то в ящике стола. С Python он мне просто не нужен! Есть даже шутка, что Python можно использовать как обычный настольный калькулятор. Сам по себе интерпретатор невероятно прост для базовых вычислений. А переход на IPython — это уже совсем другой уровень комфорта: история команд, автодополнение и куча других удобств.
Хотя иногда мне все еще нравится поиграться со своим научным калькулятором Casio (я люблю тактильные кнопки!), Python просто не сравнить ни с чем. Я могу мгновенно сгенерировать список из случайных чисел и тут же получить всю описательную статистику. Могу работать со списками из сотни элементов, что вручную или даже на калькуляторе было бы просто кошмаром. Python делает все это элегантно и без усилий.
Богатство библиотек, которое поражает воображение
Одна из самых потрясающих особенностей Python — это невероятное количество библиотек. Python не просто поставляется с мощными встроенными библиотеками (подход "батарейки включены"), но и открывает доступ к целой вселенной специализированных инструментов для анализа данных.
Встроенные математические и статистические библиотеки отлично справляются с базовыми задачами, но настоящая магия начинается с дополнительных библиотек, которые я регулярно устанавливаю в своей среде Mamba.
Основа основ — это NumPy. Эта библиотека создана для работы с большими численными массивами, но она также включает множество функций для линейной алгебры и статистики. Именно статистические возможности станут главной темой этой статьи.
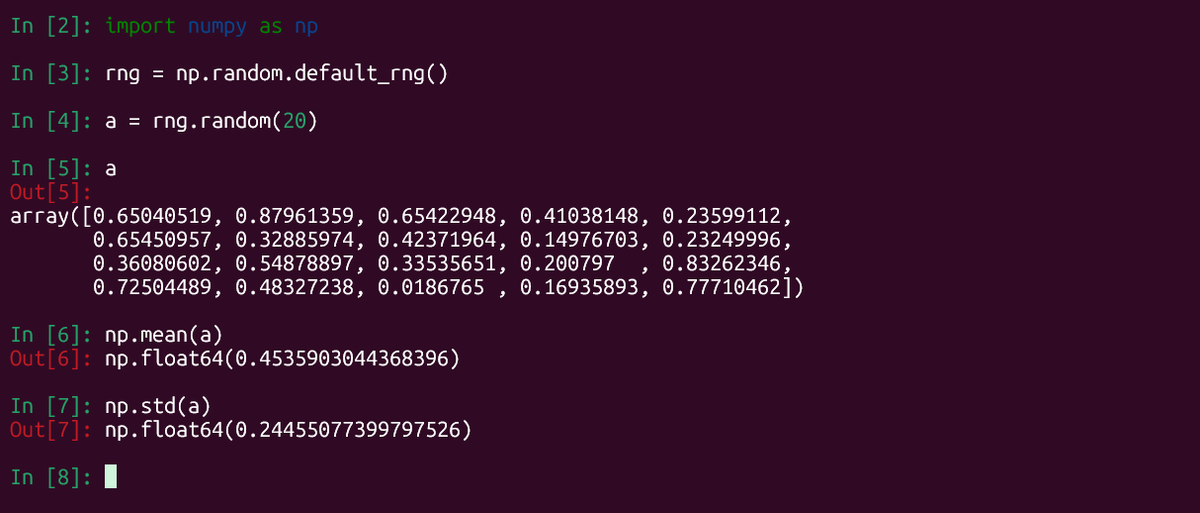
Давайте создадим список случайных чисел.
Сначала настроим генератор случайных чисел NumPy:
Теперь сгенерируем список из 20 случайных чисел:
Найдем среднее значение:
И вычислим стандартное отклонение:
Это лишь базовые операции. Настоящую привязанность к Python создают другие библиотеки.
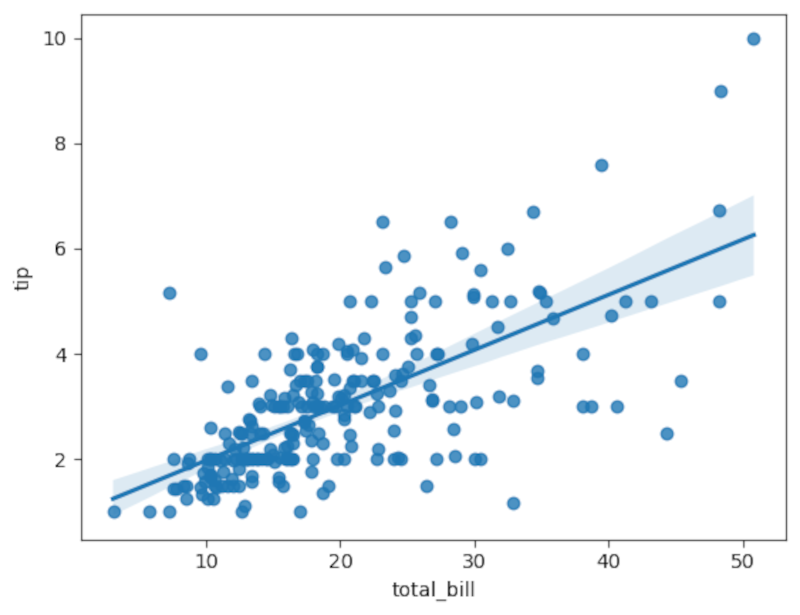
Визуализация — это мощнейший способ исследования данных. Seaborn, о котором я уже писал раньше, — один из моих любимых инструментов. Отличный пример — создание диаграмм рассеяния с линейной регрессией.
Воспользуемся классическим примером из Seaborn. Загрузим данные о счетах в ресторанах Нью-Йорка, включая размер чаевых и другие переменные вроде количества людей за столом и курящей/некурящей зоны.
Построим график зависимости размера чаевых от общего счета:
С Seaborn я также могу строить диаграммы размаха и гистограммы. Посмотрим на распределение общих счетов по дням недели:
Для более серьезного статистического анализа я использую Pingouin — библиотеку для проведения различных статистических тестов. Вернемся к нашим чаевым. Обратите внимание на коэффициент корреляции — он показывает, насколько хорошо прямая линия описывает наши данные. Квадрат этого коэффициента вы найдете в столбце "r2".
Иногда интересно посмотреть, как показатель меняется в разных категориях. Здесь на помощь приходит дисперсионный анализ (ANOVA).
Переключимся с ресторанных счетов на клювы пингвинов. Этот код исследует данные о трех видах пингвинов: Адели, Антарктический и Папуанский. Проверим, есть ли значимые различия в длине клюва между видами.
P-значение равно 0.0 — это означает, что различия статистически значимы!
Интуитивные названия, которые говорят сами за себя
R традиционно считался королем анализа данных среди языков программирования, но именно понятные названия методов в Python делают его моим безусловным фаворитом.
Я ничего не имею против R — это отличный язык для анализа данных, просто он не очень подходит лично мне. Например, вместо привычного знака равенства для присваивания вектору (аналогу массивов NumPy) используется символ "<-". Автодополнение по Tab в IPython делает ввод команд намного быстрее, чем постоянное перепечатывание, а механизм истории позволяет легко вернуться к ранее введенным командам.
Океан данных для экспериментов
Анализ данных интересовал меня давно, особенно после того, как я узнал, как активно Python и его библиотеки используются в этой области. У меня была некоторая база знаний Python, но хотелось погрузиться глубже. Но где найти данные для практики?
К счастью, с данными проблем нет вообще! Как я уже упоминал, многие библиотеки предоставляют доступ к открытым наборам данных — можно изучать возможности библиотек и проверять их результаты. Мы это уже видели в предыдущих примерах.
Другой подход — генерировать данные случайным образом. Это тоже отличный способ изучить, как работает библиотека. Единственный минус случайных данных в том, что они каждый раз разные.
Я также могу создавать собственные наборы данных. Именно это я делал для недавнего проекта по изучению времени автономной работы телефонов и планшетов.
Есть также множество готовых наборов данных на платформах вроде Kaggle, которые я могу скачать и исследовать с помощью описанных выше инструментов. Можно даже загружать данные с правительственных сайтов — там настоящие сокровищницы информации!
Мгновенная обратная связь — как живое общение с данными
Одна из моих любимых особенностей Python в анализе данных — это мгновенная обратная связь в интерактивном режиме. Мне не нужно ждать компиляции или писать целый скрипт, чтобы увидеть результат. Когда я выполняю вычисление в IPython, результат сразу появляется в терминале. Создаю график — он тут же открывается в отдельном окне.
Часто при работе с данными у меня возникают новые идеи для анализа, и я могу немедленно их проверить. В этом настоящая сила интерактивного программирования — живое исследование данных!
Jupyter-блокноты — мой цифровой лабораторный журнал
Несмотря на всю полезность IPython, многие операции исчезают после завершения сессии — закрыл окно, и все пропало. Графики можно сохранить, но вычисления, скорее всего, канут в лету. Можно настроить логирование, но нужно не забывать это делать. Если захочу вспомнить, как я что-то делал, придется копаться в истории команд.
Видимо, поэтому разработчики IPython создали интерфейс Jupyter-блокнотов. Jupyter позволяет создавать интерактивные блокноты — я обычно создаю их при исследовании нового набора данных, когда хочу зафиксировать результаты. Могу вернуться к блокноту в любой момент. И что особенно здорово — могу делиться Jupyter-блокнотами с коллегами, например, через свой GitHub.
Jupyter стал золотым стандартом в научных вычислениях и анализе данных не случайно. Он достаточно прост для исследователей любых направлений, чтобы документировать и делиться своими открытиями с коллегами.
Вот они, причины, по которым Python стал моим языком номер один, особенно для анализа данных. Это простой язык для старта, который рос и развивался вместе со мной, по мере того как я углублял свои знания и расширял возможности.
Если вам понравилась эта статья, подпишитесь, чтобы не пропустить еще много полезных статей!
Премиум подписка - это доступ к эксклюзивным материалам, чтение канала без рекламы, возможность предлагать темы для статей и даже заказывать индивидуальные обзоры/исследования по своим запросам!Подробнее о том, какие преимущества вы получите с премиум подпиской, можно узнать здесь
Также подписывайтесь на нас в:
- Telegram: https://t.me/gergenshin
- Youtube: https://www.youtube.com/@gergenshin
- Яндекс Дзен: https://dzen.ru/gergen
- Официальный сайт: https://www-genshin.ru



















