Предыдущая часть: Перевод руководства Google по промпт инжинирингу. Часть 3. Техники написания промптов: Системный, контекстный и ролевой промптинг
Следующая часть: Перевод руководства Google по промпт инжинирингу. Часть 5. Техники написания промптов: ReAct (Размышляй и действуй), Автоматический промпт инжиниринг
Перевод руководства Google по промпт инжинирингу (Prompt engineering). Оригинал доступен по ссылке. https://www.kaggle.com/whitepaper-prompt-engineering
Перевод сделан с применением AI.

Промптинг с шагом назад
«Промптинг с шагом назад» — это метод повышения производительности, при котором LLM сначала рассматривает общий промпт, связанный с конкретной задачей, а затем использует ответ на этот общий вопрос в качестве промпта для решения конкретной задачи. Эта «шаг назад» позволяет LLM активировать соответствующие фоновые знания и процессы мышления, прежде чем пытаться решить конкретную проблему.
Рассматривая более широкие и основополагающие принципы, LLM могут генерировать более точные и содержательные ответы. Промпт с шагом назад побуждает LLM критически мыслить и применять свои знания новыми и творческими способами. Такое изменение финального промпта при выполнении задания, позволяет LLM использовать больше знаний в параметрах LLM, чем при прямом запросе LLM.
Это может помочь уменьшить погрешности в ответах LLM, сосредоточив внимание на общих принципах, а не на конкретных деталях, промптинга с шагом назад.
Давайте рассмотрим эти примеры, чтобы понять, как промптинга с шагом назад может улучшить результаты. Давайте сначала рассмотрим обычный промпт (таблица 8), прежде чем сравнивать её с пошаговым промптингом (таблица 9):
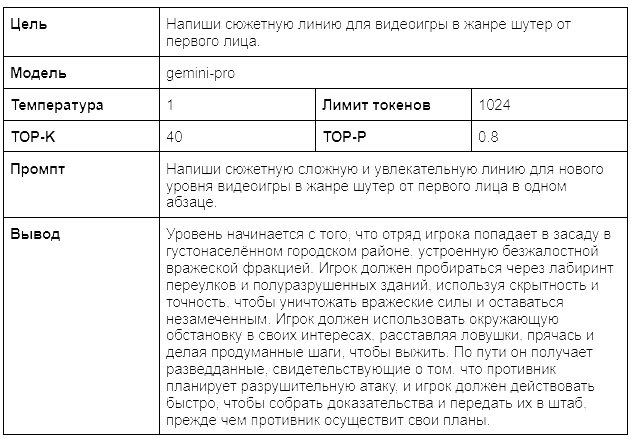
Если вы установите температуру на 1, то можете получить самые разные творческие тексты для сюжетной линии, но они будут довольно случайными и шаблонными. Поэтому давайте сделаем шаг назад:
Да, эти темы кажутся подходящими для видеоигры от первого лица. Давайте вернёмся к исходному запросу, но на этот раз включим ответ из предыдущего шага в качестве контекста и посмотрим, что получится.
Похоже на интересную видеоигру! Используя gромптинг с шагом назад, вы можете повысить точность своих промптов.
Цепочка рассуждений (CoT)
Цепочка рассуждений (CoT) — это метод, который улучшает способность LLM к логическому мышлению за счёт создания промежуточных этапов рассуждений. Это помогает LLM генерировать более точные ответы. Вы можете комбинировать его с few-shot промптами, чтобы получать более точные результаты при выполнении более сложных задач, требующих логического мышления перед ответом, поскольку это сложнее, чем цепочка рассуждений с zero-shot промптами.
У CoT много преимуществ. Во-первых, он не требует больших усилий, но при этом очень эффективно и хорошо работает с готовыми моделями LLM (так что не нужно их дорабатывать). Кроме того, с помощью промптов CoT вы можете интерпретировать ответы LLM и видеть, какие шаги были пройдены. Если возникнет ошибка, вы сможете её выявить. Цепочка рассуждений, по-видимому, повышает надёжность при переходе между разными версиями LLM. Это означает, что производительность вашего промпта должна быть более стабильной при использовании разных LLM, чем если бы ваш промпт не использовал цепочку рассуждений. Конечно, есть и недостатки, но они интуитивно понятны.
Ответ LLM включает в себя цепочку рассуждений, что означает большее количество выходных токенов, а значит, прогнозы стоят дороже и занимают больше времени.
Чтобы объяснить следующий пример в таблице 11, давайте сначала попробуем создать промпт, который не использует CoT, чтобы продемонстрировать недостатки большой языковой модели.
Это явно неправильный ответ. На самом деле, LLM часто испытывают трудности с математическими задачами и могут давать неверные ответы — даже на такое простое задание, как умножение двух чисел. Это связано с тем, что они обучаются на больших объёмах текста, а математика может требовать другого подхода. Давайте посмотрим, улучшит ли цепочка рассуждений результат.
Хорошо, теперь окончательный ответ правильный. Это потому, что мы чётко проинструктировали LLM объяснять каждый шаг, а не просто выдать ответ. Интересно, что модель прибавляет 17 лет. Я бы в уме взял разницу в возрасте между мной и моим партнёром и прибавил бы её. (20+(9-3)). Давайте поможем модели думать немного больше похоже на меня.
Таблица 12 — это пример цепочки рассуждений с zero-shot. Цепочка рассуждений может быть очень эффективной в сочетании с single-shot или few-shot промптингом, как показано в таблице 13:
Цепочка рассуждений может быть полезна в различных сценариях использования. Например, для генерации кода, когда запрос разбивается на несколько этапов и сопоставляется с конкретными строками кода. Или для создания синтетических данных, когда у вас есть какое-то начальное значение, например: «Продукт называется XYZ, напишите описание, которое поможет модели сделать предположения на основе названия продукта». Как правило, любая задача, которую можно решить с помощью обсуждения, хорошо подходит для цепочки рассуждений. Если вы можете объяснить шаги, необходимые для решения проблемы, попробуйте цепочку рассуждений.
Пожалуйста, посмотрите блокнот (https://github.com/GoogleCloudPlatform/generative-ai/blob/6008d86b1ef9dbb5fcac3a5767169de64cc9ae81/gemini/prompts/examples/chain_of_thought_react.ipynb), размещённому в репозитории GoogleCloudPlatform на Github, где более подробно рассматривается промптинг с цепочкой рассуждений.
В разделе «Лучшие практики» мы рассмотрим некоторые лучшие практики, характерные для промптинга с цепочкой рассуждений.
Самосогласованность
Несмотря на то, что большие языковые модели продемонстрировали впечатляющие успехи в различных задачах НЛП, их способность рассуждать часто рассматривается как ограничение, которое нельзя преодолеть, просто увеличив размер модели. Как мы узнали из предыдущего раздела, посвященного цепочке рассуждений, модели можно задать последовательность шагов, как если бы человек решал задачу. Однако CoT использует простую стратегию «жадного декодирования», что ограничивает ее эффективность. Самосогласованность сочетает в себе выборку и голосование большинством голосов для создания разнообразных путей рассуждений и выбора наиболее последовательного ответа. Это повышает точность и согласованность ответов, генерируемых LLM. Самосогласованность повышает псевдовероятность того, что ответ будет правильным, но, очевидно, требует больших затрат.
Это происходит в несколько этапов:
- Генерация различных путей рассуждений: LLM несколько раз получает одно и то же задание. Высокая температура побуждает модель генерировать различные пути рассуждений и точки зрения на проблему.
- Извлечение ответа из каждого сгенерированного ответа.
- Выбор наиболее часто встречаемого ответа.
Давайте рассмотрим пример системы классификации электронных писем, которая определяет, является ли письмо ВАЖНЫМ или НЕ ВАЖНЫМ. Zero-shot цепочка, не содержащая ошибок, будет отправлена LLM несколько раз, чтобы проверить, будут ли ответы отличаться после каждой отправки. Обратите внимание на дружелюбный тон, выбор слов и сарказм, использованные в письме. Всё это может ввести LLM в заблуждение.
Вы можете использовать приведённый выше промпт и попробовать понять, возвращает ли LLM последовательную классификацию. В зависимости от используемой вами модели и конфигурации температуры она может возвращать «ВАЖНО» или «НЕ ВАЖНО».
Сгенерировав множество цепочек мыслей и выбрав наиболее часто встречающийся ответ («ВАЖНО»), мы можем получить более последовательный и правильный ответ от LLM.
Этот пример показывает, как можно использовать самосогласованный промпт о для повышения точности ответа LLM, рассматривая несколько точек зрения и выбирая наиболее последовательный ответ.
Все части перевода руководства Google по промпт инжинирингу
Перевод руководства Google по промпт инжинирингу. Часть 1. Конфигурация вывода LLM
Перевод руководства Google по промпт инжинирингу. Часть 7. Лучшие практики для написания промптов, 1
Перевод руководства Google по промпт инжинирингу. Часть 8. Лучшие практики для написания промптов, 2
Перевод руководства Google по промпт инжинирингу. Часть 9. Лучшие практики для написания промптов, 3
Перевод руководства Google по промпт инжинирингу. Часть 10. Резюме и полезные ссылки