Самая распространённая структура, с которой мы работаем в программировании, это одномерные массивы. Их можно представить как последовательность ячеек в памяти, и при этом у каждой ячейки будет своё смещение от начала массива.
Обычно это записывается так:
foo[x]
Что означает: элемент со смещением x относительно начала массива foo.
Очень часто встречаются и двумерные массивы. Их мы легко представляем в виде матриц, где доступ к ячейке осуществляется через индексы (x, y).
Возможные варианты записи в языках программирования:
foo[x, y]
или
foo[x][y]
Но память компьютера одномерна. Она не может хранить двумерные структуры, также не существует двумерных адресов, поэтому хранение такого массива становится не столь тривиальным.
Наконец, есть трёхмерные массивы, которые мы опять же можем легко представить в виде куба с индексами ячеек (x, y, z):
foo[x][y][z]
Тут, как нетрудно догадаться, всё становится ещё сложнее. Можно делать и 4-мерные, и более-мерные массивы, что уже и представить трудно, но тем не менее это реализуется довольно просто.
Давайте посмотрим, как.
Я привожу примеры на языке C, но так как память для всех языков устроена одинаково, то и реализации везде будут похожими.
Мы будем использовать сайт Compiler Explorer, чтобы смотреть, что получается в памяти при работе с различными массивами.
Начнём с простого. Вот объявление массива из 10 элементов:

В первый элемент массива (со смещением 0) я записал значение 0, а в последний (со смещением 9) значение 9. Вот что получилось в памяти:
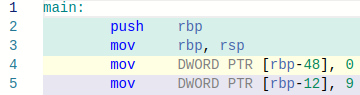
Первые две инструкции с регистром rbp организуют фрейм функции на стеке. Это служебная информация, которая к делу не относится, но в итоге регистр rbp служит базовым адресом, относительно которого будет всё считаться.
Далее мы видим, что в [rbp-48] записывается 0. Таким образом, адрес rbp-48 это начало массива. А в [rbp-12] записывается 9. Это конец массива. Значит, массив расположен от адреса rbp-48 до адреса rbp-12. Какова его длина?
48 - 12 = 36 байт. Почему столько, если мы делали массив на 10 элементов?
Потому что массив типа int, а каждый элемент типа int занимает 4 байта. Итого 36 / 4 = 9 элементов. Но почему тогда 9, а не 10? Потому что адрес последнего элемента это rbp-12, но сам элемент занимает 4 байта, то есть массив на самом деле продолжается до rbp-8. Итого массив занимает 40 байт, или 10 элементов по 4 байта.
Теперь используем для доступа к массиву индекс не в виде константы, а в виде переменной:
Тип size_t это специальный целый тип максимального размера (в данном случае 64 бита), который используется для доступа к памяти. Можно использовать простой int, но тогда в машинном коде получатся дополнительные преобразования, чего я хочу избежать ради чистоты.
Получаем следующий код:
Переменная x тоже должна где-то храниться, поэтому под неё выделяется адрес rbp-8. Туда помещается значение 5. Далее значение 5 из x помещается в регистр rax, и вычисляется адрес доступа к 5-му элементу:
- rbp-48 это адрес начала массива
- rax*4 это смещение 5-го элемента относительно начала
Таким образом, rbp-48+rax*4 это адрес 5-го элемента. Обратите внимание, что всё это вычисляется одной машинной инструкцией, но на разных архитектурах процессоров могут быть разные решения.
- Когда мы использовали константы, ничего не вычислялось, потому что компилятор сразу посчитал нужные смещения.
Подведём итог для одномерных массивов. Адресация для них наглядна и проста в силу одномерности. Смещение x автоматически умножается на размер элемента массива.
Двумерные массивы
Само понятие "мерности" существует исключительно в нашей голове. Память это последовательность байт, и ничего более. Поэтому нужно просто придумать способ, как разместить в памяти двумерный массив (матрицу).
Для начала, сколько вообще нужно памяти? Если матрица имеет размер 10*10, то всего в ней хранится 100 элементов. Значит, нужно выделить в памяти 100 элементов, что будет эквивалентно обычному одномерному массиву длиной 100.
Вопрос лишь в том, как распорядиться адресами внутри одномерного массива так, чтобы они соответствовали адресам двумерного.
Это можно решить, записывая строки матрицы подряд. То есть первые 10 элементов это первая строка матрицы. Следующие 10 элементов это вторая строка матрицы. И т.д.
Так как каждая строка матрицы это одномерный массив, то всю матрицу можно представить как "массив массивов".
Это будет одномерный массив, где каждый элемент – одномерный массив. Так как элементы в массиве расположены друг за другом, то массивы внутри массива также будут расположены друг за другом.
Тогда такая запись:
foo[x][y] = 5;
Будет означать: в одномерном массиве массивов найти элемент-массив с индексом x, а в этом элементе-массиве найти элемент с индексом y.
Посмотрим, что на самом деле происходит в коде:
Результат:
Сразу посмотрим на последнюю строчку. Она не изменилась: к адресу начала массива rbp-224 добавляется смещение rax*4. Адрес, конечно, поменялся, так как теперь массив состоит из 49 элементов и занимает 196 байт, плюс 16 байт выделено под переменные x, y.
Но как именно вычислено значение смещения в rax? Выглядит запутанно. Строчки с 7 по 12 я перепишу более человечно:
rdx = x
rax = rdx
rax *= 8 (операция сдвига влево 3 раза)
rax -= rdx
rdx = y
rax += rdx
Упростим:
rax = x * 8
rax -= x
rax += y
Итого:
rax = x * 7 + y
Такая, казалось бы, простая операция в машинных кодах выглядит странно из-за оптимизаций компилятора. Но по факту мы получаем смещение строки путём умножения x на длину строки (7). Мы же говорили, что строки матрицы расположены в памяти одна за другой? Так вот строка c индексом 3 будет иметь смещение относительно начала массива, равное 3 * 7. И к этому смещению добавляется уже смещение внутри самой строки (y).
Таким образом, любой двумерный индекс матрицы (x, y) транслируется в одномерный как:
offset = x * w + y;
Где w – длина строки матрицы.
Обратите также внимание на использование индексов x, y. В наглядном представлении матрицы x идёт по горизонтали, а y по вертикали, в соответствии с математическими осями координат.
И индекс типа foo[x][y] предполагает то же самое, но на деле там всё наоборот. Первый индекс это по сути индекс строки, то есть x идёт по строкам, то есть по вертикали. А второй это индекс элемента в строке, то есть y идёт по столбцам, то есть по горизонтали.
Чтобы сохранить соответствие с наглядным представлением, индексы будет правильнее записывать как foo[y][x] и соответственно менять формулу вычисления смещения. Тут главное понимать, что за что отвечает, потому что вы можете представить матрицу в памяти в принципе в любой ориентации, если будете вычислять смещения вручную.
Трёхмерные и более массивы
Думаю, тут уже нет проблем с представлением. Если двумерная матрица это массив массивов, то трёхмерная матрица это массив двумерных матриц.
То есть фактически: это одномерный массив, каждый элемент которого это матрица. Матрицы хранятся подряд друг за другом. Чтобы найти смещение матрицы с индексом z, нужно размер матрицы умножить на z, потом внутри этой матрицы мы можем найти смещение строки, и т.д.
Посмотрим пример:
И результат:
Последняя строчка опять-таки не меняется, кроме адреса rbp-288. Перевод на человеческий язык вычисления смещений (строчки с 8 по 14):
rax = x
rdx = rax * 4
rax = y
rax += rdx
rdx = rax * 4
rax = z
rax += rdx
Упростим:
rax = (x * 4 + y) * 4 + z
Или так:
rax = x * 16 + y * 4 + z
Как видим, размер матрицы 4*4 это 16. Такие матрицы упакованы в массив длиной 4 элемента. Соответственно, по индексу x получаем смещение матрицы (x * 16), далее внутри матрицы получаем смещение строки (y * 4) и наконец в строке получаем смещение z.
Опять обращу внимание, что это соответствует записи foo[x][y][z], но для привычного визуального представления следует писать foo[z][y][x]. Так координата z будет отвечать за "глубину" куба, y за высоту, а x за ширину.
Альтернативное вычисление смещения
Исходя из всего вышеописанного, вы можете вообще забыть о многомерных массивах и заменить их одномерными с ручным вычислением смещения.
Например, вместо массива foo[10][10] вы можете использовать foo[100]. А вместо индексов x, y вычислять сразу нужное смещение y * 10 + x. В этом случае вы можете назначать оси координат x, y именно так, как вам хочется, а не как предусмотрено в языке. Этот подход можно назвать универсальным для всех языков:
Что получилось:
По сути всё то же самое, но вычисления теперь немножко тяжелее из-за применения отдельной переменной w. Используется операция imul регистра с памятью. Это не критично. Но посмотрим, какие преимущества можно поиметь в этом случае. Вот обычный код с двумерным массивом:
Здесь в циклах по x и по y происходит заполнение ячеек массива с индексами (x, y). На каждом шаге цикла нужно из этих индексов вычислить смещение:
Теперь сделаем аналогичный код с одномерным массивом:
Он также в цикле проходит по ячейкам массива, но так как массив одномерный, мы просто увеличиваем смещение на каждом шаге цикла, не вычисляя его каждый раз:
Такой код значительно короче и наверняка быстрее (с современными компиляторами не угадаешь :)
Кроме того, мы можем убрать циклы по x и по y и сделать один цикл сразу по смещению:
Массивы указателей
Часто массивы приходится создавать динамически, когда их размер заранее неизвестен. Если мы определили, что в массиве w столбцов и h строк, то можно выделить память в размере w * h * sizeof(int) и далее работать по прежней одномерной схеме.
Однако если нам требуется именно подобие двумерного массива с двумя индексами, можно поступить так:
- Под каждую строчку массива выделяем память из w элементов
- В массиве размером h сохраняем указатели на эти строчки
Получается массив из h элементов, где каждый элемент это указатель на массив из w элементов:
Доступ к такому массиву тоже выглядит как foo[x][y]. Но на деле в памяти он уже не расположен одним куском. Там расположены только 4 указателя, а вот каждый указатель может указывать уже куда угодно.
Для foo[1][2] мы находим указатель со смещением 1, затем относительно этого указателя находим смещение 2, и таким образом получаем нужный адрес.
Указатель можно достать из массива и манипулировать им отдельно как одномерным массивом:
Заметим, что к общему размеру массива 4*4 добавляется ещё 4 указателя, каждый размером 8 байт. Такой массив занимает больше памяти, но им легче манипулировать. Например, если нужно поменять местами две строки массива, то достаточно поменять просто два указателя, а не копировать строки с места на место.



















