Большие языковые модели (LLM), такие как GPT-3 и GPT-4, открыли новую эпоху в обработке естественного языка. Эти модели обучаются на огромных объемах текстовых данных и способны выполнять широкий спектр задач, связанных с языком: генерация текста, перевод, ответы на вопросы, создание программного кода и многое другое. Однако за их способностями скрываются сложные технические процессы и инновационные архитектуры. В этой статье мы рассмотрим основные технические аспекты, которые лежат в основе LLM, их архитектуру, процесс обучения и то, как они обрабатывают информацию.
Введение в архитектуру LLM
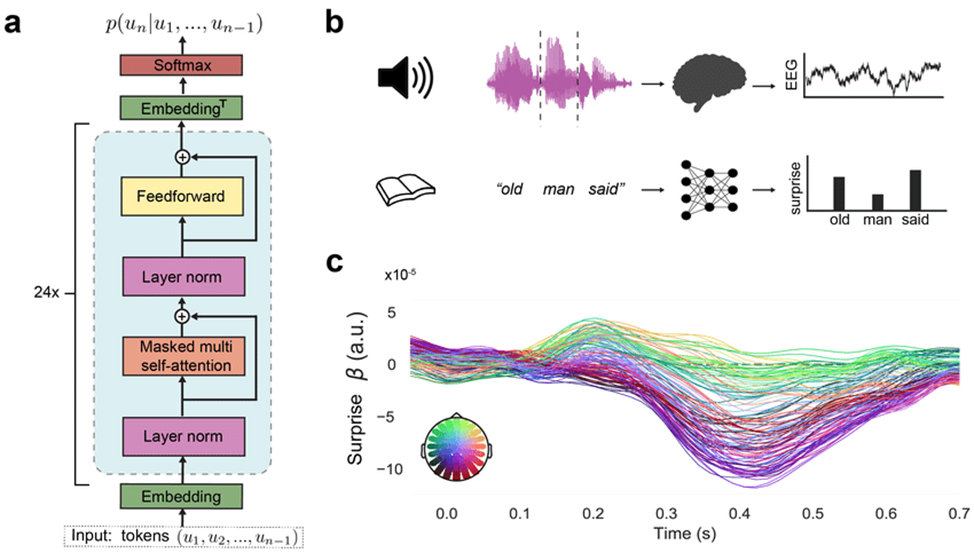
Основой большинства современных языковых моделей является архитектура трансформеров (Transformer). Эта архитектура была предложена в 2017 году в статье "Attention is All You Need" и с тех пор стала стандартом для создания моделей, которые работают с текстом. Трансформеры работают на основе механизма внимания (attention), который позволяет моделям эффективно анализировать длинные последовательности текста и учитывать контекст каждого слова.
Архитектура трансформеров состоит из двух ключевых компонентов:
- Энкодер (encoder): преобразует входной текст в скрытое представление.
- Декодер (decoder): генерирует выходной текст на основе скрытого представления.
Большие языковые модели, такие как GPT (Generative Pre-trained Transformer), используют только декодер, так как они генерируют текст на основе уже предобученной модели.
1. Архитектура трансформеров: основа LLM
Механизм внимания (Attention)
Ключевым элементом трансформеров является механизм внимания, который позволяет модели фокусироваться на разных частях входной последовательности при обработке каждого элемента. В отличие от предыдущих подходов, таких как рекуррентные нейронные сети (RNN), которые обрабатывали последовательности шаг за шагом, трансформеры могут обрабатывать все элементы последовательности одновременно.
Как это работает:
Когда модель обрабатывает предложение, механизм внимания помогает ей учитывать важные слова и связи между ними, чтобы лучше понять смысл текста. Например, если модель видит предложение "Маша пошла в магазин, чтобы купить молоко", механизм внимания помогает модели понять, что слово "купить" связано со словом "молоко", а не со словом "Маша".
Многоголовое внимание (Multi-Head Attention)
Еще одной важной особенностью трансформеров является многоголовое внимание. Это означает, что модель не ограничивается одним набором вниманий, а использует несколько параллельных механизмов, каждый из которых фокусируется на разных аспектах текста. Это позволяет модели анализировать различные зависимости между словами на разных уровнях абстракции.
Нормализация и обратная связь
Помимо механизма внимания, трансформеры используют другие важные компоненты, такие как нормализация слоев (layer normalization) и механизм обратной связи (residual connections). Нормализация помогает стабилизировать обучение модели и улучшить ее производительность, а обратная связь позволяет модели использовать информацию с предыдущих слоев, что улучшает обучение и генерацию текста.
2. Предобучение и обучение моделей LLM
Большие языковые модели проходят через два ключевых этапа: предобучение и тонкая настройка (fine-tuning).
Предобучение (Pre-training)
На этапе предобучения модель обучается на огромных объемах текстовых данных. Цель предобучения — научить модель предсказывать следующее слово в предложении, основываясь на предыдущем контексте. Это называется задачей автокодировщика (autoencoder task). Модель анализирует миллиарды фрагментов текста, чтобы понять, как слова связаны друг с другом, какие паттерны существуют в языке и как строятся предложения.
Данные для предобучения могут быть разнообразными: книги, статьи, веб-страницы, социальные сети и другие текстовые источники. Чем больше и разнообразнее данные, тем лучше модель обучается и тем больше задач она может решать.
Пример задачи предобучения:
Модель может получить предложение: "Кошка сидела на __" и должна предсказать слово "столе". На этом этапе модель учится понимать структуру предложений, логику языка и контексты.
Тонкая настройка (Fine-tuning)
После предобучения модель может быть адаптирована для решения конкретных задач. Это делается на этапе тонкой настройки, когда модель дообучается на специализированных данных для выполнения конкретной задачи. Например, модель может быть настроена для генерации текста в стиле новостей или для анализа юридических документов.
3. Обработка текста в LLM: от токенов к генерации
Чтобы работать с текстом, большие языковые модели должны преобразовать текст в числовую форму, так как нейронные сети могут обрабатывать только числа.
Токенизация
Первый шаг в обработке текста — это токенизация. Токенизация — это процесс разбиения текста на отдельные элементы, называемые токенами. Токены могут быть словами, частями слов или символами. Например, предложение "Мир — это место для всех" может быть токенизировано как ["Мир", "—", "это", "место", "для", "всех"].
Большие языковые модели работают с токенами, а не с целыми словами, так как это позволяет им лучше обрабатывать сложные языковые конструкции и редкие слова.
Представление токенов (Embeddings)
После токенизации каждому токену присваивается числовое представление — эмбеддинг. Эмбеддинги — это векторные представления, которые кодируют смысл каждого токена. Токены с похожими значениями будут иметь близкие эмбеддинги. Например, слова "кот" и "кошка" могут иметь схожие числовые представления, так как они связаны по смыслу.
Эмбеддинги обучаются на этапе предобучения, и чем больше данных модель видит, тем точнее она может кодировать смысл слов.
Генерация текста
После того как модель получает числовое представление токенов, она использует это представление для генерации текста. Основной принцип генерации заключается в том, что модель предсказывает следующее слово (или токен) на основе предыдущего контекста. Это повторяется до тех пор, пока не будет сгенерирован полный текст.
Модели, такие как GPT-3 и GPT-4, могут генерировать текст пошагово, анализируя каждый новый токен и учитывая предыдущие. Это позволяет им поддерживать логику и связность текста на протяжении всей сессии генерации.
4. Обучение LLM: вычислительные ресурсы и сложность
Обучение больших языковых моделей требует колоссальных вычислительных ресурсов. Современные LLM, такие как GPT-3 и GPT-4, содержат сотни миллиардов параметров. Для их обучения требуется использование мощных вычислительных систем, таких как кластеры графических процессоров (GPU) и тензорных процессоров (TPU), которые могут выполнять миллиарды операций в секунду.
Количество параметров
Параметры — это коэффициенты, которые модель использует для обработки и генерации текста. Чем больше параметров у модели, тем больше информации она может хранить и тем точнее ее ответы. GPT-3, например, содержит 175 миллиардов параметров, а GPT-4 — еще больше (точное количество не раскрывается).
Обучение на больших объемах данных
Для обучения таких моделей необходимы гигантские объемы данных. GPT-3 была обучена на более чем 500 гигабайтах текстовых данных. Это включает книги, статьи, веб-страницы и другие текстовые источники. Чем больше данных получает модель, тем точнее она может обрабатывать разнообразные языковые задачи.
Время и стоимость обучения
Обучение таких моделей занимает недели или даже месяцы и может стоить миллионы долларов. Это связано с необходимостью обработки огромных объемов данных и выполнения сложных вычислительных операций. Несмотря на высокую стоимость, результаты оправдывают затраты: модели, такие как GPT-3 и GPT-4, открывают новые горизонты в области автоматизации и генерации текста.
5. Преодоление вызовов: проблемы и ограничения
Несмотря на впечатляющие достижения, большие языковые модели сталкиваются с рядом вызовов:
- Энергопотребление и стоимость: Обучение LLM требует значительных вычислительных ресурсов и потребляет много энергии, что приводит к высоким затратам.
- Этические вопросы: Модели могут генерировать неправильный или вредоносный контент, что вызывает вопросы по поводу их безопасного использования.
- Контекстные ограничения: Модели могут терять контекст при обработке очень длинных текстов или диалогов.
- Зависимость от данных: Качество модели напрямую зависит от качества и разнообразия данных, на которых она обучена. Если данные содержат предвзятые или ошибочные информации, модель может воспроизводить эти ошибки.
Заключение
Большие языковые модели, такие как GPT-3 и GPT-4, представляют собой одно из самых значительных достижений в области искусственного интеллекта. Их архитектура, основанная на трансформерах и механизме внимания, позволяет им эффективно обрабатывать текст и генерировать осмысленные ответы. Обучение таких моделей требует огромных вычислительных ресурсов и времени, но результатом является мощный инструмент, который может решить широкий спектр задач, от написания текстов до программирования.
С развитием технологий и улучшением архитектур мы можем ожидать появления ещё более продвинутых языковых моделей, которые будут способны решать ещё более сложные задачи и открывать новые горизонты в различных сферах бизнеса и науки.
Хотите создать уникальный и успешный продукт? Доверьтесь профессионалам! Компания СМС предлагает комплексные услуги по разработке, включая дизайн, программирование, тестирование и поддержку. Наши опытные специалисты помогут вам реализовать любые идеи и превратить их в высококачественный продукт, который привлечет и удержит пользователей.
Закажите разработку у СМС и получите:
· Индивидуальный подход к каждому проекту
· Высокое качество и надежность решений
· Современные технологии и инновации
· Полное сопровождение от идеи до запуска
Не упустите возможность создать платформу, которая изменит мир общения! Свяжитесь с нами сегодня и начните путь к успеху вместе с СМС.
Тел. +7 (985) 982-70-55
E-mail sms_systems@inbox.ru



















