Система управления базами данных
В «старозаветные» времена, когда доминирующим способом хранения и обслуживания данных выступали системы, основанные на файлах (электронные картотеки), разработчики этих систем были вынуждены создавать программный пакет полностью от «А» до «Я». Программистам приходилось определять структуры, выдумывать методы хранения и доступа к записям. С появлением более совершенных моделей данных для управления данными стали разрабатывать специальное программное обеспечение, получившее название системы управления базами данных (СУБД).
Вне зависимости от того, на основе какого подхода спроектирована современная БД, ее существование немыслимо без системы управления базами данных. Прямо или косвенно СУБД используется администраторами, разработчиками БД, программистами и обычными пользователями. Для этого СУБД предоставляет определенный набор инструментов, упрощающих проектирование, администрирование БД и обеспечивающих доступ к данным.
Так что такое СУБД? Предлагаю нашу работу начать с разъяснения этого термина. В некоторых источниках предлагается под СУБД понимать «совокупность программных и языковых средств, обеспечивающих управление базами данных». Давайте позволим себе небольшую вольность и немного расширим понятие.
Система управления базами данных (Database Management System, DBMS) – это комплекс программных средств, с помощью которого можно создавать и поддерживать базу данных, а также осуществлять к ней контролируемый доступ пользователей.
Введение в определение СУБД понятия «контролируемый доступ» очень важно, т. к. акцентирует внимание на то, что на СУБД возлагаются обязанности не просто по управлению базами данных, но и по:
- предотвращению несанкционированного доступа к данным:
- контролю за многопользовательским (параллельным) доступом;
- поддержке целостности данных;
- восстановлению данных.
Существует множество показателей, по которым можно классифицировать СУБД, но основной отличительный признак – модель реализации данных. Нам уже известно, что существуют сетевая, иерархическая, реляционная, объектно-ориентированная и другие модели. Различают персональные и многопользовательские СУБД. Персональные системы предназначены для создания небольших БД, устанавливаемых на одном компьютере, поэтому их часто называют настольными. В противовес персональным, многопользовательские системы предназначены для обслуживания БД, находящихся в совместном владении несколькими пользователями. Есть и другие классификационные признаки, например, по способам разработки приложений БД (ручное кодирование и автоматическая генерация форм), по возможностям определения данных, особенностям обработки транзакций, используемой ОС, по экономическим параметрам.
Функционал СУБД
В самом общем случае работу СУБД можно описать следующим образом.
1. Пользователь запрашивает у системы разрешение на доступ к данным.
2. СУБД анализирует запрос и проверяет права пользователя на осуществление запрашиваемой операции.
3. СУБД выполняет требуемые действия с данными и при необходимости возвращает результат пользователю.
На первый взгляд все просто, но давайте заглянем в функциональные обязанности СУБД глубже.
Ключевой функционал СУБД был сформулирован Коддом еще в начале 1980-х годов1. На первом этапе насчитывалось 8 функций, позднее Кодд и другие исследователи неоднократно расширяли и уточняли этот перечень. Так что теперь можно говорить о нескольких десятках функций, служб и сервисов, которыми обязана обладать современная СУБД.
К основополагающим функциям СУБД мы будем относить:
1. Доступность данных. Предоставление пользователю возможности вставлять, редактировать, удалять и извлекать данные из БД. При осуществлении любой из операций пользователь не должен вникать в особенности физической реализации системы, т. е. все операции должны быть прозрачны.
2. Метаописание данных. СУБД должна предоставлять системный каталог, в котором содержится: описание хранимых в БД данных; описание связей между данными; ограничения целостности данных; регистрационные данные пользователей и другая служебная информация. Благодаря метаданным БД становится доступной внешним приложениям, упрощается понимание смысла данных, усиливаются меры безопасности, может выполняться аудит информации.
3. Управление параллельностью. Реализация механизма одновременного многопользовательского (параллельного) доступа к обрабатываемым данным с гарантией корректного обновления этих данных. Умение предоставить нескольким пользователям совместный доступ к разделяемым ресурсам – это едва ли не самая сложная задача, решаемая СУБД. СУБД должна суметь избежать конфликта совместного доступа двух или большего числа пользователей к одним и тем же строкам таблицы, или, по крайней мере, исключить какие-либо нежелательные последствия при возникновении конфликта.
4. Обработка данных в рамках транзакции. СУБД гарантирует, что БД будет всегда находиться в непротиворечивом состоянии вне зависимости от любых сбоев при проведении операций обновления данных. Для этого операции с данными (в первую очередь вставки, редактирования и удаления) объединяются в единый блок, называемый транзакцией. Все операторы транзакции должны быть выполнены корректно и полностью, только в этом случае в БД будут зафиксированы изменения. В противном случае осуществляется автоматический откат транзакции, т. е. состояние БД будет восстановлено на момент времени, предшествующий вызову транзакции. В дальнейшем в курсе БД мы рассмотрим много примеров транзакций, а пока ограничимся одним, наиболее близким каждому из нас. Представьте себе, что вы снимаете какую-то сумму наличных денег в одном из банкоматов вашего города. Вы уже ввели свой код доступа, указали требуемую сумму, эта сумма денег списана с вашего электронного счета и «бежит» по проводам из банка к вам в руки. И вдруг из-за сбоя питания, или отказа коммуникационного оборудования, или по какой-то другой технической причине команда на выдачу денег в банкомат не дошла. Что в результате? Вы потеряли свои деньги? К счастью, нет. Программное обеспечение банковских платежных систем увидит, что одна из операций транзакции завершена некорректно. Поэтому все изменения, сделанные указанной транзакцией, подлежат отмене – списанные электронные деньги вновь вернутся к вам на банковский счет. Вам остается повторить операцию получения наличных в другом банкомате.
5. Обеспечение целостности данных. Все содержащиеся в БД данные должны быть корректны и непротиворечивы. Это означает, что данные в таблицах могут модифицироваться только в соответствии с утвержденными правилами. В самом общем случае можно говорить о существовании трех правил поддержания целостности данных: целостность доменов, целостность отношений, целостность связей между отношениями. Кроме того, разработчик имеет возможность описывать свои собственные бизнес-правила, которые мы станем называть корпоративными ограничениями.
6. Восстановление данных. В случае непредвиденных ошибок и сбоев, приведших к повреждению или разрушению данных, СУБД должна обладать возможностью восстанавливать пострадавшие данные. В первую очередь эта функция реализуется с помощью процедур резервного копирования.
7. Обмен данными. СУБД обязана поддерживать современные сетевые технологии и предоставлять доступ к БД удаленным персональным компьютерам.
8. Контроль за доступом к данным. Доступ к данным могут осуществлять только зарегистрированные в СУБД пользователи в соответствии с назначенными администратором СУБД им правами.
Еще раз отметим, что список обязанностей СУБД на этом далеко не заканчивается. Современные системы предоставляют нам средства мониторинга, сервисы статистического анализа, утилиты экспорта/импорта данных, развитые средства проектирования БД и прикладного программного обеспечения, инструменты реорганизации файлов данных и индексных данных, службы аудита и многое другое. Однако все дополнительные сервисы и службы выполняют вспомогательную роль, а основы жизнедеятельности СУБД определяются перечисленными выше функциями.
Компоненты СУБД
СУБД – это сложный вид программного обеспечения, над созданием которого работают большие коллективы высококвалифицированных программистов. На современном рынке программного обеспечения конкурирует около трех десятков коммерческих СУБД. Из малых систем, рассчитанных на одного пользователя, сегодня наибольшей популярностью пользуются Microsoft Access и SQLite. В перечень получивших широкое признание многопользовательских реляционных СУБД входят: Oracle, SQL Server компании Microsoft, InterBase, Firebird, MySQL, PostgreSQL, Informix и т. д. Несмотря на то что все перечисленные программные продукты предназначены для решения практически одних и тех же задач, входящие в перечисленные СУБД программные компоненты и взаимосвязи между ними далеко не идентичны. Поэтому любая попытка обобщить все известные технические решения построения СУБД и на основе этого обобщения построить структурную схему типичной СУБД, пусть даже высокой степени абстракции, несколько наивна. Тем не менее мы попытаемся это сделать.
Для того чтобы СУБД оказалась в состоянии предоставлять минимальный набор из рассмотренных выше восьми сервисов, она должна состоять из набора компонент, представленных на рисунке.
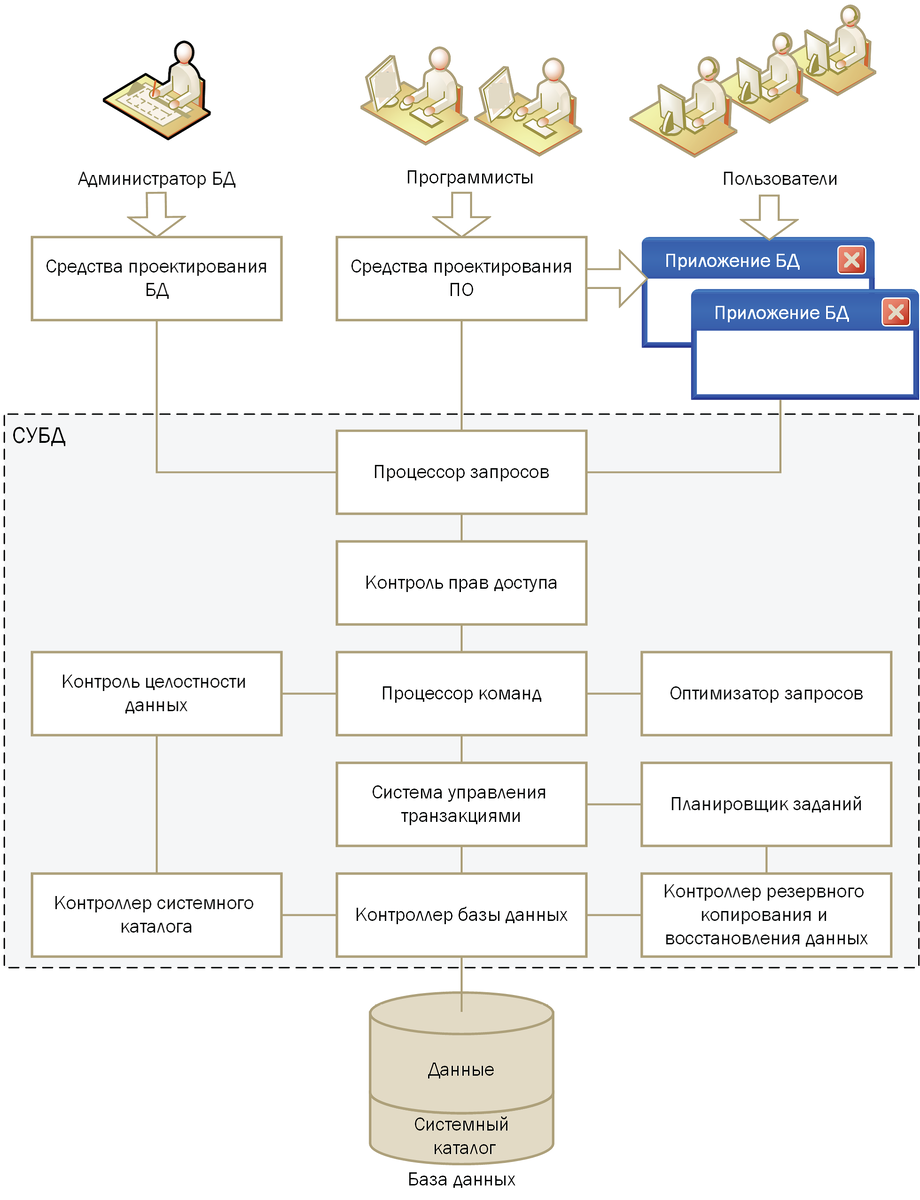
Над верхним уровнем системы расположены потребители услуг СУБД:
- администратор БД;
- программисты;
- конечные пользователи.
Администратор БД отвечает за планирование и физическую реализацию проекта. Он создает основные объекты БД, определяет правила поддержания целостности и непротиворечивости данных, управляет политикой безопасности, анализирует процесс эксплуатации проекта контролирует производительность системы – одним словом, поддерживает жизнедеятельность БД. В распоряжении администратора имеются разнообразные средства проектирования БД, эти средства могут входить в состав СУБД в виде дополнительных программных модулей, а могут быть поставлены и сторонними разработчиками.
Программисты совместно с администратором трудятся над физическим созданием проекта БД. Но прикладных программистов в большей степени интересует не сама концепция проекта БД, а способы донесения этой концепции до конечного пользователя. Поэтому область интересов программистов смещена в сторону разработки клиентских приложений и отчетов. Основным инструментом прикладного программиста выступают многочисленные среды проектирования, как правило, не ниже 4-го поколения.
Основным потребителем услуг СУБД выступает обычный пользователь – в его интересах создаются БД и прикладное программное обеспечение. Среди пользователей есть и неплохие специалисты, чьи советы способны помочь разработчикам БД, а на другом конце спектра находятся пользователи, с трудом обнаруживающие нужные кнопки на клавиатуре. Последние могут даже и не понимать, что они работают с БД, расположенной на другом компьютере.
Основным средством общения между людьми и базой данных выступает структурированный язык запросов SQL. Поэтому средства проектирования БД, ПО и клиентские приложения БД отправляют в адрес СУБД инструкции на языке SQL. Эти команды поступают на процессор запросов, который преобразует их в набор низкоуровневых команд, понятных ядру СУБД.
К базе данных могут обращаться различные категории пользователей, от руководителя предприятия до случайного посетителя. Одним из них разрешается просматривать и редактировать любые данные, другим могут быть доступны лишь выборочные сведения, третьим вообще не стоит даже знать о существовании БД. Именно поэтому в составе большинства СУБД имеется модуль, отвечающий за контроль прав доступа. В простейшем случае модуль следит затем, чтобы к БД присоединялись только авторизованные пользователи, для этого полученные во время регистрации пароль и логин потенциального клиента сверяются с хранящимися в системном каталоге учетными записями. В современных многопользовательских СУБД система безопасности значительно сложнее и включает в себя комплекс программных и аппаратных средств защиты.
Убедившись, что инструкция поступила от доверенного лица, модуль контроля прав доступа передает ее в распоряжение процессора команд. В первую очередь процессор убеждается, что поступившая команда не противоречит ограничениям целостности данных. Это зона ответственности модуля контроля целостности данных. На время проверки команды на соответствие ограничениям целостности доменов, сущностей и связей задействуется контроллер системного каталога.
Именно он имеет возможность собирать метаданные, в которых прячется техническое описание нашей БД. Поняв, что угрозы целостности нет, процессор передает команду оптимизатору запросов. Задача оптимизатора – найти наиболее эффективный способ выполнения поступивших команд. Наконец, оптимизированная команда компилируется и передается во власть системе управления транзакциями. Система управления транзакциями, во-первых, отвечает за полное и корректное выполнение блока команд и, во-вторых, совместно с планировщиком заданий обеспечивает параллельную многопользовательскую обработку данных. Наконец, блок команд передается в распоряжение контроллеру баз данных. Задача модуля заключается в организации взаимодействия СУБД с файлами БД и файлами системного каталога. При этом для осуществления стандартных операций ввода-вывода задействуются возможности операционной системы.
Системный каталог
В отличие от систем, основанных на файлах, хранивших описание своих данных внутри исполняемых файлов, все современные СУБД обладают системным каталогом, в котором хранятся следующие сведения:
1) описание поддерживаемых типов данных;
2) описание развернутых БД (схемы данных) и входящих в них объектов (домены, таблицы, представления и т. д.);
3) сведения об ограничениях целостности;
4) имена и права пользователей, имеющих доступ к данным;
5) разнообразная статистика.
Благодаря системному каталогу легко определить смысл данных, что (в отличие от систем, основанных на файлах) позволит пользователям понять назначение и состав БД.
Архитектурные решения доступа к БД
Поиски эффективных архитектурных решений организации доступа к данным начались с первых дней работы с БД. Все решения так или иначе отталкивались от текущего состояния электронной вычислительной техники. Во времена доминирования больших вычислительных машин доступ к самым первым БД базировался на принципе телеобработки. База данных и СУБД размещалась в памяти центральной ЭВМ, к этой ЭВМ подключались терминалы. Так как терминальные устройства особым умом и сообразительностью не отличались (они не обладали собственными вычислительными возможностями), то вся обработка данных осуществлялась только в процессоре центральной ЭВМ. Системы на основе телеобработки доминировали до начала 1970-х годов, но с изобретением микропроцессоров стали постепенно уступать свои позиции и к сегодняшнему дню практически не используются.
Файл-сервер
Бурное развитие микропроцессорной техники в 70-х годах прошлого века привело к появлению сравнительно дешевых микро-ЭВМ. Теперь руководители предприятий вместо покупки одной большой дорогостоящей ЭВМ начали приобретать несколько менее производительных, но вполне приемлемых для решения задач, стоящих перед их коллективами. Микро-ЭВМ объединялись в простейшие одноранговые локальные сети, в которых каждая из машин обладала равными правами со своими соседями. Одна из ЭВМ (с накопителями на жестких магнитных дисках наибольшего размера) назначалась файловым сервером. На выданной в совместное пользование сетевой папке сервера, кроме обычных документов, размещали и файлы баз данных (рисунок).
Для того чтобы этой БД могла воспользоваться какая-нибудь из рабочих станций, она обращалась к файловому серверу, перекачивала все файлы БД в свою память, вносила правки и возвращала файлы на прежнее место. Такой способ многопользовательского доступа к БД обладал всего одним преимуществом – простотой реализации. Все остальное было сплошными недостатками:
¾ на каждой рабочей станции необходимо устанавливать полную копию СУБД;
¾ во время работы с данными сетевой трафик возрастает до пиковых значений;
¾ управление параллельностью обработки данных и поддержку целостности реализовать было практически невозможно, в то время как один пользователь сохранял свою порцию данных, другой уже вносил в нее изменения.
Сегодня работа с БД в режиме файл-сервер популярностью не пользуется, хотя до сих пор существуют программные продукты, ориентированные на индивидуального пользователя и способные предоставить подобный сервис, например, Microsoft Access.
Клиент-сервер
Факт появления клиент-серверных систем тесным образом связан с парадигмой открытых систем, активно эволюционирующих с начала 1980-х годов. Программисты пришли к выводу о необходимости распределения задач между элементами системы, в данном случае между двумя типами процессов, которые могут выполняться на различных объединенных в вычислительную сеть компьютерах. Сервер отвечает за предоставление каких-либо услуг клиентскому процессу. Клиент запрашивает у сервера определенные услуги и ресурсы.
В клиент-серверных системах БД размещается на отдельном наиболее производительном компьютере, на этом же компьютере разворачивается сервер (это и есть СУБД). На клиентских станциях достаточно установить сравнительно нетребовательное к ресурсам пользовательское ПО и настроить сетевой доступ к серверу СУБД. Работа клиент-серверных систем принципиально отличается от работы в системах «файл-сервер». Теперь вместо перекачки файлов c БД клиентский компьютер отправляет серверу запрос, построенный на основе языка SQL. Получив и обработав инструкцию SQL, сервер возвращает клиентскому компьютеру результаты ее выполнения, например, выборку определенных данных.
Уже несколько десятилетий клиент-серверное построение БД является доминирующим. Причин тому несколько:
1) значительно повышается доступность БД. Сервер представляет собой открытую систему, поэтому клиентские компьютеры могут функционировать под управлением различных операционных систем и с различным ПО;
2) выделенный сервер СУБД в состоянии обеспечить параллельную многопользовательскую обработку данных;
3) основные правила поддержки целостности и непротиворечивости данных описываются на одном сервере СУБД, клиентские приложения никаким образом не в состоянии обойти эти правила;
4) экономно расходуется пропускная способность компьютерных сетей;
5) благодаря централизованному хранению данных сравнительно просто поддерживать единые для всех правила безопасности БД;
6) наличие стандарта на основной язык общения SQL обеспечивает широкие возможности доступа к серверу БД из программного обеспечения различных производителей;
7) упрощены вопросы обслуживания и администрирования БД.
Предусмотрено несколько подходов к распределению обязанностей между сервером и клиентом. В простейшем случае (рисунок (а)) работает модель тонкий клиент (thin client). Это тот вариант, когда клиентское ПО максимально упрощено и представляет собой только интерфейсную часть, состоящую из форм ввода и просмотра данных. Тонкий клиент фактически отвечает лишь за презентацию данных, поэтому можно сказать, что он не умеет думать и вся программная логика сосредоточена на стороне сервера. Есть и обратное решение – толстый клиент (fat client). В противовес своему тонкому собрату, толстый клиент старается максимально облегчить работу сервера (рисунок (б)). Например, реализует дополнительные бизнес-правила, производит сортировку полученных данных на клиентской стороне, выполняет вспомогательные расчеты, проверяет синтаксис инструкций SQL и т. п. Проектирование полнофункционального толстого клиентского приложения значительно сложнее, чем разработка его упрощенного собрата. Но в конечном счете мы получаем существенную прибавку в производительности, а это весьма важно в больших многопользовательских БД.
К настоящему времени существует несколько сотен СУБД, предназначенных для работы по модели клиент-сервер. В России наибольшей популярностью пользуются MySQL, Oracle, SQL Server компании Microsoft, InterBase компании Embarcadero, PostgreSQL, Informix компании IBM, NetWare SQL фирмы Novell и т. д.
Распределенная система
Системы управления распределенными базами данных (СУРБД) – одно из направлений развития современных технологий хранения данных. Подобные системы предполагают организацию работы с данными, распределенными между несколькими серверами, которые, в свою очередь, могут быть удалены друг от друга на значительные расстояния. Любой из серверов должен обладать возможностью обрабатывать как локальные запросы пользователей в своей подсети, так и слаженно работать с внешними запросами, поступающими из других подсетей. В свою очередь, клиент вправе получать одновременный доступ к интересующим его данным, физически размещенным на разных серверах (в идеале с логической точки зрения клиент вообще может полагать, что он работает с единой, а не распределенной БД).
Распределенные системы могут включать как однотипные (гомогенные), так и разнотипные (гетерогенные) БД. СУБД обслуживают фрагменты БД, между которыми может осуществляться частичная или полная репликация данных. Кроме того, могут использоваться специальные серверы, предназначенные для управления всей системой (например, на них может содержаться глобальный системный каталог,
Резюме
Состав и особенности функционирования любой сложной системы, в том числе и СУБД, определяются стоящими перед ней задачами. Еще на заре разработки реляционной модели доктор Эдгар Фрэнк Кодд сформулировал функциональные обязанности классической СУБД, чем определил вектор развития этой области информационных технологий. За более чем 40 лет существования реляционных баз данных идеи Кодда совершенствовались учеными, инженерами и программистами, в результате к сегодняшнему дню разработан широкий перечень эффективных программных и аппаратных решений, применяемых в СУБД.
К настоящему времени существует более 3 сотен разнообразных СУБД (https://db-engines.com), способных удовлетворить самого привередливого разработчика.
Среди множества архитектурных решений доступа к БД на сегодняшний день доминирующее положение занимают клиент-серверные системы с централизованным хранением данных. Вместе с тем развитие сетевых технологий и возрастающие требования предприятий и организаций к быстрому и надежному доступу к данным привели к появлению распределенных БД, основанных на идее децентрализации.