Подво́дим итоги
В академической среде традиционно перед подведением итогов работы требуется делегировать будущим Исследователям глобальную посы́лку, обобщающую проделанную работу. Т.к. фактически мы решаем оптимизационную задачу, этим обобщением должно стать некое искомое идеализированное состояние системы, к которому мы стремимся. Автор (согласно своим представлениям) предлагает обобщённую функцию цели и таблицу c им рекомендуемым ранжированием отдельных о́ткликов.
Из вычислительных экспериментов для каждого множества исходных данных (заданный алгоритм и размер обрабатываемых данных, число вычислителей в поле параллельных вычислителей, эвристика преобразования ЯПФ) получаем величины функций отклика. В общем случае формально описать производи́мые действия можно так:
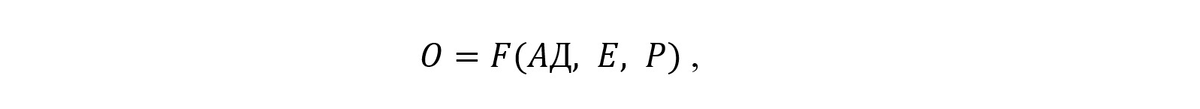
где O – кортеж откликов (O1÷O4, см. первый столбец нижерасположенной таблицы),
F - программный интерпретатор - обработчик входных данных (напр., исследовательский инструмент SPF),
АД – описание алгоритма и обрабатываемых данных (в предлагаемом случае данные внедрены в описание алгоритма),
E – описание действий (“эвристика”, реализованная в форме Lua-скриптов) по целенаправленному преобразованию ЯПФ с конечной целью построения плана параллельного выполнения алгоритма АД,
P – количество параллельных вычислителей (для случая преобразования ЯПФ без возрастания высоты оной имеем условие W≥P≥⸢Ŵ⸣, при возможности возрастания высоты - W≥P≥1; здесь через ⸢Ŵ⸣ вынужденно обозначаем ближайшее к Ŵ сверху целое число).
Список откликов (фактически отдельных показателей эффективности процесса создания и выполнения параллельной программы) приведён в нижеследующей таблице, причём в порядке, представляющимся автору наиболее логичным (строго говоря, в порядке снижения зна́чимости при составлении глобальной оптимизационной функции).
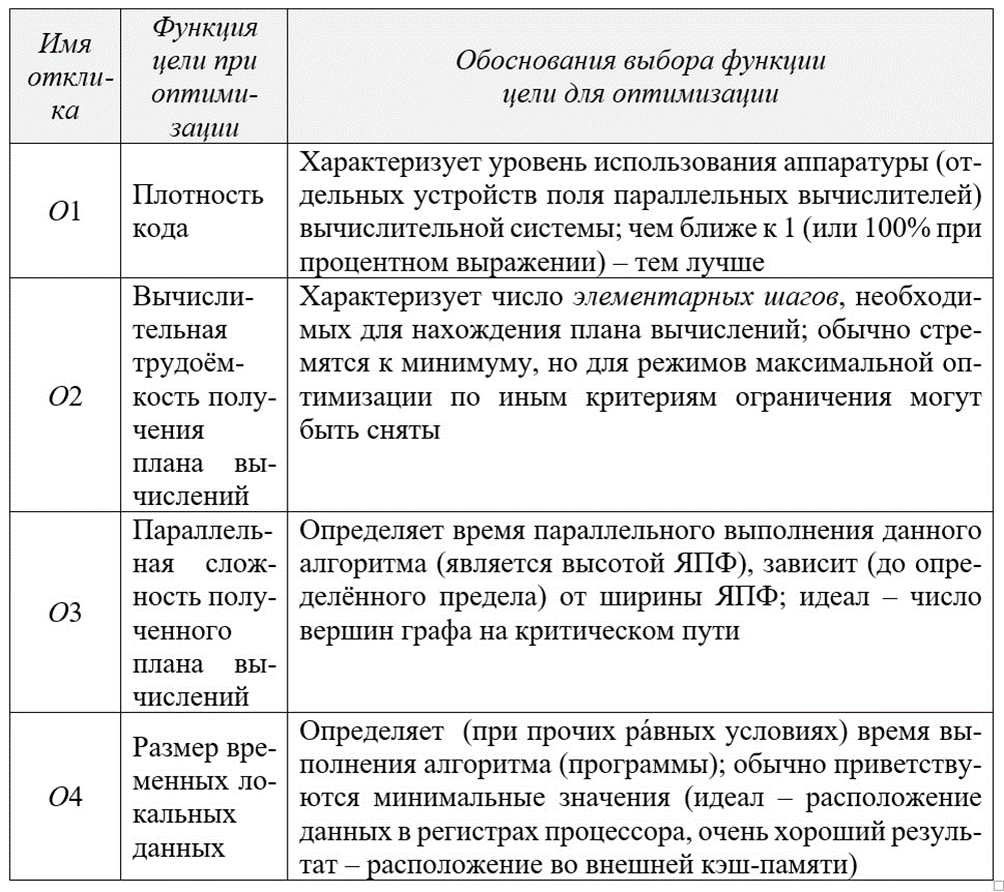
Конечная (практически используемая при оптимизации) обработка откликов O1÷O4 должна быть решена конкретным исследователем (это может быть, напр., некая формула свёртки отдельных откликов для поиска экстремума полученного выражения или иной разумный подход к многокритериальной оптимизации).
Автор в тексте книги вполне обдуманно “готовил” Исследователей к вопросам оптимизации, рассуждая (при построении и обсуждении экспериментальных графиков) о допустимых диапазонах изменения параметров, форме полученных кривых и др. В каждом конкретном случае список функций цели может меняться, как и степень их значимости. Решение оптимизационной задачи - “Это совсем-совсем другая история”..!
В целом процесс достижения поставленной цели требует итерационного подхода к улучшению качества преобразования по выбранным параметрам. Схематично этот процесс представлен на рис. 40; в центральной части этого рисунка условно показана реорганизуемая ЯПФ, итерации осуществляются при метафорическом движении против часовой стрелки.
После наработки необходимого онтологического базиса (особенно набора эвристических методов и ситуаций их примени́мости) схема рис. 40 должна быть эффективной для автоматизации с элементами искусственного интеллекта в нейросетевой реализации… но это материал для разработок будущих Исследователей!..
После представления результатов исследований логично привести выводы по работе:
- Предложенные программные модели получения планов параллельного выполнения произвольных алгоритмов показали свою эффективность (в исследованной области размерности данных, обрабатываемых алгоритмами). Модели позволяют определять основные характеристики (ме́ры) исходного параллелизма в алгоритмах (высота и ширина ЯПФ информационного графа, статистические показатели распределения этих величин) и параметры использования найденного параллелизма при вычислениях (плотность кода при параллельном выполнении на вычислительной системе заданной конфигурации, размер временных данных и др.) произвольных алгоритмов, описанных с использованием ассемблероподобного языка и предикатным методом реализации условности выполнения операций. Одновременно определяется вычислительная сложность (трудоёмкость) при совершении адресных преобразований сечений информационного графа с целью получения рациональных планов параллельного выполнения алгоритмов.
- Попытки получения планов параллельного выполнения алгоритмов cневозрастающей параллельной сложностью (высота ЯПФ постоянна) показали ограниченную эффективность (пространственная плотность кода не выше 0,5÷0,7, во многих случаях порядка 0,2).
- Получение планов параллельного выполнения алгоритмов при возрастании параллельной сложности (высоты ЯПФ) показали более благоприятные результаты (напр., пространственная плотность кода до 0,8÷0,95, причём при возрастании размеров обрабатываемых данных показатель улучшается).
- Задача получения планов выполнения программ на гетерогенном поле параллельных вычислителей требует значительно бо́льших затрат, при этом достигнутая моделированием плотность кода ниже, чем для случая гомогенного вычислительного поля.
Да нет, конечно! Вариантов следующих действий минимум два – ждать разработки “умными дя́дями” распараллеливающих компиляторов/интерпретаторов (вообще-то "сего счастливого случая” можно ожидать и десятилетиями) или распараллеливать свои программы самостоятельно. Ясно, что во втором случае сложностей будет “выше крыши” - разработчику придётся пройти все (или близкие) этапы обработки – от этапа анализа на наличие параллелизма в программе до этапа целенаправленной её модификации (для получения максимального соответствия программы вычислительной системе заданной архитектуры). Кстати, этот вариант сопряжён с опасностью со стороны используемого транслятора – т.к. почти всегда неизвестны досконально особенности преобразования исходного кода в машинный, вполне можно ожидать неожиданностей при выполнении программы.
Поддержка VLIW-архитектуры в наборе инструментов для компиляции LLVM
Конечно, высший уровень – разработка реальных компиляторов/интерпретаторов, создающих рациональные исполняемые коды для параллельного исполнения на основе исходных последовательных текстов на определённом языке (языках) программирования с использованием предложенных исследований. После трансляции исходных текстов уже имеется набор операторов, фактически представляющих ИГА данной программы; создание на его основе плана параллельного выполнения реализуется вышеразработанными методами.
При работе на уровне машинных команд следующий этап – разработка реальных компиляторов/интерпретаторов, создающих рациональные исполняемые коды для параллельного исполнения на основе исходных последовательных текстов на определённом языке (языках) программирования с использованием предложенных исследований. После трансляции исходных текстов уже имеется набор операторов, фактически представляющих ИГА данной программы; создание на его основе плана параллельного выполнения реализуется вышеразработанными методами.
- Существует целая область человеческих знаний – теория (а значит, и практика) разработки трансляторов (компиляторов/интерпретаторов). При создании реальных трансляторов приходится учитывать огромное количество фактически малозна́чимых для стратегии, но критически важных для программной реализации особенностей (включая известные проблемы использования указателей, конфликтов при работе с памятью в связках атома́рных инструкций Load/Store etc); поддержка VLIW в наборе инструментов для компиляции LLVM (Low Level Virtual Machine, https://llvm.org/) в настоящее время шаг за шагом развивается. Эти проблемы могут снизить эффективность предложенных методик получения рациональных (субоптимальных) планов параллельного выполнения алгоритмов, но вряд ли кардинально изменят найденные моделированием тенденция протекания процессов.
Кстати, рекомендую книгу Бруно Кардос Лопеса и Рафаэля Аулера “LLVM: инфраструктура для разработки компиляторов” (2014, 244 стр., LitRes.ru).
Потом придётся ещё сравнить эффективность разработанных трансляторов для выявления наилучшего подхода (автор считает важнейшим критерием плотность кода исполняемой параллельной программы).
Задача автора – заинтересовать самую динамичную группу людей практическим анализом алгоритмов в целях совершенствования процесса параллельных вычислений. Метод достижения – разработка общедоступных компьютерных программ с современным привычным интерфейсом общения с пользователем, позволяющих в “полуигрово́м” режиме осваивать достаточно сложные исследовательские приёмы. Автор надеется на возникший интерес у Читателей к указанному предмету и, возможно, влияние этого на (связанный с исследовательскими практиками) жизненный выбор Читателей.
Вопрос адекватности полученных решений
Вопрос об адекватности проводимых с помощью инструментов DF и SPF расчётов, конечно, приемлем. Въедливый читатель не преминет упомянуть об ограниченном размере обрабатываемых данных при моделировании. Однако “Что есть - то есть!”… Единственный вариант при этом – экстраполировать (продо́лжить) полученные данные в область бо́льших значений исследуемого параметра. Как и в большинстве исследований, важно определить форму анализируемой зависимости, а эксперименты показывают, что эффективность целенаправленного изменения ЯПФ возрастает с увеличением размеров обрабатываемых данных.
Существует целая серия дополнительных вопросов (на самом деле их, конечно, больше), в данной работе вообще не рассматривавшихся; пытливый Читатель, конечно, рассмо́трит эти пункты в качестве дополнительных тем для рассмотре́ния:
① Обойдена́ проблема описания циклических выражений (путём развёртывания циклов - unrolling). Однако возможен иной путь – отказ от требования ацикличности графа; это ста́вит дополнительную (непростую!) задачу – выделе́ние в графе циклических участков.
② Не рассмо́трена (а только наме́чена) задача целенаправленной модификации последовательного варианта алгоритма (в некоторых случаях при этом можно получить снижение размеров “временно живущих данных” и, соответственно, повышения общей производительности вычислительной системы за счёт оптимального использования регистров общего назначения и/или кэша). И конечно, полностью опу́щено рассмотре́ние вопроса фактического распределения и оптимизации данных при использовании внутренних регистров процессора…
Возможность достижения пресловутого “общего и окончательного решения” в виде создания универсального метода, строящего субоптимальный план параллельного выполнения произвольного алгоритма, остаётся сомнительной.
- С другой стороны, исследования показывают, что “большое разнообразие алгоритмов не приводит к такому же разнообразию информационных структур”. Следственно, “типовых информационных структур алгоритмов в конкретных прикладных областях немного” (акад. Валентин Воеводин).
Ничто не препятствует Исследователю (а я уверен - Читатель уже частично стал им!) обратиться и к более изощрённым методам построения планов параллельного выполнения программ - напр. :
① защита диссертации А.Н.Черных (словами соискателя “работа носит теоретический характер”),
② хорошее (с подробным описанием методов планирования) учебно-методическое руководство предлагает А.А.Прихожий (Минск, БНТУ),
③ в книгах И.Е.Федотова (дополнительно здесь) имеется вполне вне́млемое перечисление приёмов выявления в алгоритмах скрытого потенциала параллелизма.
Как автор и обещал – он “уложился" в 20 публикаций (статей). Ка́юсь – часто не удава́лось соблюсти рекомендуемый DZEN’ом размер статей (3’000÷5’000 символов) – нере́дко получалось больше… Конечно, проблема информационного (читай – причинно-следственного) анализа алгоритмов огромная и автору довелось поставить лишь ключевые вопросы. Автор не прощается полностью с Читателями, но обязуется совершенствовать каждую публикацию по отдельности (есть материалы, не воше́дшие в окончательный вариант цикла) и на продолжение контактов надеется !
Напр., автор считает полезным обнародовать свои выступления на ежегодных конференциях “Свободное программное обеспечение в высшей школе” в г. Переславле-Залесском, организованных на базе Института программных систем имени А.К.Айламазяна РАН :
® Презентация выступления 2022 г. “Параллелизм в алгоритмах - выявление и рациональное использование”. // Тезисы докладов Объединённой конференции СПО: от обучения до разработки (OSEDUCONF-2022, OSSDEVCONF-2022).
® Презентация выступления 2023 г. “ПРАКТИКУМ по изучению скрытого в алгоритмах параллелизма и его рационального использования в вычислениях”. // Ежегодная конференция “Свободное программное обеспечение в высшей школе” (OSEDUCONF-2023).
® На конец июня 2024 г. была назначена очередная конференция OSEDUCONF-2024… Однако организаторы (настоятельно – и, похоже, справедливо) порекомендовали перенести доклад на профессиональную конференцию разработчиков OSSDEVCONF-2024 в конце сентября… Последние данные – конференция назначена на 04÷06 октября 2024 г. ; см. программу конференции (доклад автора 04.10.2024 г. в 16:45).
® Презентация и тезисы доклада автора на ХХ юбилейной конференции (OSEDUCONF-2025) “Свободное программное обеспечение в высшей школе” 07÷09 февраля 2025 г. (см. программу конференции, доклад 07.02.2025 в 17:25 час).
Важное достижение автора – получение количественных решений
Главной своей заслугой автор считает достижение не качественных (“хуже/лучше”, “ши́рше/уже́е” и т.д.), а количественных результатов (полученных в ходе компьютерной симуляции и выведенных в форме графиков, таблиц etc - – приведены́ в публикациях #011, #012, #015, #016, #017, #018 и #019). В данном случае обработка информации в самом деле близка́ к задачам Big Data (однако сложнее их, ибо требует обработки данных с много более глубоким уровнем понимания сути процессов).
- Известное высказывание Дмитрия Менделеева “Наука начинается с тех пор, как начинают измерять. Точная наука немы́слима без ме́ры.” Абсолютно верно – человек превращается в слепца́ без количественных данных об окружающем Мире. А как только человек начинает измерять, происходит второе чудо – появляется возможность объективно сравни́вать различные сущности друг с другом по заданным параметрам... А это, пожалуй, сопостави́мо с небольшой технической революцией!
И последнее – не было бы никаких количественных данных без специализированного программного обеспечения (с помощью которого эти данные и были получены). Т.к. оно довольно специфическое, время на создание было потрачено предостаточно (необходимо было сделать возможно более универсальную систему, а не узко специфическую). Особо рад автор идее управления преобразования ЯПФ с использованием скриптового языка (скриптовый язык даёт гибкость, а базовый компилируемый – скорость выполнения). Оба в формате инсталляционных файлов, GUI, Win’32; общее описание см. публикацию #011:
® исследовательский инструмент ПРАКТИКУМ DF - вы́грузка здесь (подробнее см. публикацию #010)
® исследовательский инструмент ПРАКТИКУМ SPF - вы́грузка тут (подробнее см. публикацию #013)
Последние публикации автора :
- Баканов В.М. Формирование планов организации параллельных вычислений на процессорах со сверхдлинным машинным словом. // Журнал “Программная инженерия". — М.: 2025, том 16, #3, c. 115-121. DOI: 10.17587/prin.16.115-121
- Баканов В.М. Построение планов выполнения программ с максимальной плотностью кода на фиксированном наборе параллельных вычислителей // Известия высших учебных заведений. Технические науки. 2023. #1. С.14–31. DOI: 10.21685/2072-3059-2023-1-2
- Баканов В.М. Вычислительная сложность построения рациональных планов выполнения программ на заданном поле параллельных вычислителей. Russian Technological Journal. 2022; 10(6):7-19. https://doi.org/10.32362/2500-316X-2022-10-6-7-19
- Баканов В.М. Research and selection of rational methods for obtaining framework of schedules for the parallel programs execution. // Lecture Notes in Networks and Systems. Springer, Cham, 2021, pp. 268-280. DOI: 10.1007/978-3-030-90321-3_22 ISBN: 978-3-030-90320-6 Интернет ISBN: 978-3-030-90321-3
Информация о канале вообще и его оглавление…
- В работе мы использовали специализированное авторское программное обеспечение (фактически исследовательские инструменты), предназначенное для выявления в произвольных алгоритмах параллелизма и его рационального использования при вычислениях.
В.М.Баканов. Практический анализ алгоритмов и эффективность параллельных вычислений. ISBN 978-5-98604-911-3. 2023. LitRes.ru