До сих пор исследования проводились для случая размера гранул параллелизма, равных одной машинной инструкции (fine-grained parallelism, микропараллелизм), причины этого приведены ранее. Там же показаны преимущества (но и трудности) формального обнаружения гранул параллелизма максимально большого размера (макропараллелизм).
Где используется ма́кропараллелизм
● Кстати – а почему гранулы параллелизма большого размера (макропараллелизм) используются в вычислительных кла́стерах? Ответ несло́жен – кластер представляет собой многомашинный (иногопроцессорный) вычислительный комплекс архитектуры MPP (Massively Parallel Processing – вычислительные системы с разделённой между отдельными вычислительными узлами памятью – и оперативной и внешней), в котором передача информации между отдельными узлами осуществляется с помощью компьютерной сети. Т.к. скорость передачи данных в компьютерной сети относительно небольшая (на порядки меньше, нежели по внутренним шинам обмена данными), время обме́нов достаточно велико́ (часто не менее нескольких миллисекунд). Исходя из соображений вокруг формулы [1] в публикации #003 желательно, чтобы время выполнения гранул большого размера (макропараллелизм) было минимум на порядок больше времени обмена данными (чтобы обмены не “тормозили” процесс собственно вычислений); исходя их характе́рного для современных микропроцессоров быстродействия в 10^9 операций/сек число операций в грануле должно быть примерно такого же порядка.
Современные кластеры всё чаще выполняются по упрощённой схеме – с использованием в качестве вычислительных узлов устройства архитектуры SIMD (Single Instruction stream, Multiple Data stream) – чаще всего арифметические ускорители фирм NVIDIA Corp. / AMD. В самом деле – многие алгоритмы с высокой степенью регулярности (напр., процедуры линейной алгебры) хорошо “ложа́тся” на такую (каждый вычислительный узел выполняет одни и те же действия, но с разными данными) архитектуру. Ну а нейронные сети вообще сла́вятся максимально возможной регулярностью при примитивности вычислительных операций в каждой грануле параллелизма…
● Осталось объяснить причины повсеместного использование MPP-архитектуры в кластерах. Тут всё просто – вычислительные комплексы подобной архитектуры обладают повышенной масштабируемостью (проще говоря - возможностью значительного увеличения числа вычислительных узлов без изменения архитектуры системы). Альтернативная архитектура SMP (Symmetric Multi Processing – вычислительные системы с общей памятью) - этим свойством не обладает вследствие возникновения “зато́ров” при попытках одновременного до́ступа множества вычислительных узлов к общей памяти.
Макропараллелизм широко́ используется именно при кла́стерных вычислениях (а большинство суперкомпьютеров фактически являются вычислительными кла́стерами). Для этого случая нечасто применяются ранее описанные процедуры распараллеливания с использованием анализа информационных зависимостей в алгоритмах – давным-давно при численном моделировании стало обычным делом сведе́ние вычислительных задач к серии стандартных процедур (чаще всего разделов линейной алгебры; наиболее часто это решение СЛАУ – Систем Линейных Алгебраических Уравнений, для которых разработаны десятки основанных на макропараллелизме методов параллельного формирования и решения). Узкий специалист обычно не размышляет над программной реализацией этих методов – он просто вызывает некую библиотечную функцию для параллельного решения СЛАУ определённого вида.
● Яркий пример – метод коне́чных элементов (FEM - Finite Element Method); автор в далёкой молодости о́тдал дань этому способу расчётов, разрабатывая программы ещё на Фортран'е (!). Метод заключается в преобразовании проблемной области из непрерывной в дискретную путём разделения её на небольшие части (называемые конечными элементами). Требующие определения функции (напр., перемещения или приращения перемещений для вариантов упругого или упруго-пластического тел соответственно) кусо́чно определены в точках, объединяющих элементы. В результате такого представле́ния задача решения дифференциальных уравнений в частных производных сво́дится к решению системы СЛАУ большой размерности (миллионы и более неизвестных, причём матрица системы обычно имеет ленточную форму). После сглаживания отдельных функций по элементам получаем окончательное решение.
● Цель текущей публикации – показать примени́мость и полезность функционала пакета SPF не только при решении вопросов микропараллелизма, но проблем с макропараллизмом.
Микро- и макропараллелизм. Достоинства и недостатки
В данной главе покажем возможности использования исследовательского инструмента SPF при анализе программ со значительным размером гранул параллелизма (собственно декомпозиция исходного алгоритма производится на основе ясно видимых особенностей его выполнения).
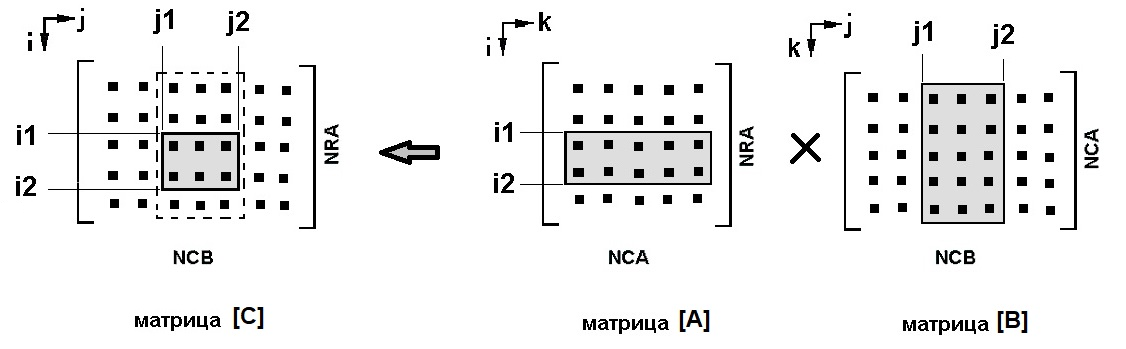
Для анализа выбран алгоритм параллельного ленточного умножения матриц традиционным методом (схема рис. 35) вследствие его максимальной простоты и прозрачности (известны и другие алгоритмы параллельного перемножения матриц (напр., бло́чные алгоритмы Фокса и Кэннона), однако при наличии неоспоримых преимуществ они существенно сложнее разобранного). Эксперименты проводились на инструментальном вычислительном Linux-кла́стере кафедрального уровня РТУ МИРЭА. Межузловые коммуникации поддерживаются технологией MPI (Message Passing Interface, версия библиотек LAM7.0.6/MPI 2 C++ Indiana University), экспериментально определённая аппаратно-программная латентность коммуникационной сети на обме́нах типа “точка-точка” составила 33 мксек).
Общая программа умножения матриц приведена ниже, ленточный метод предполагает разбиение исходных матриц на горизонтальные и вертикальные ленты вдоль индекса k, на отдельных вычислителях исполняется внутренний цикл (по k), результатом является прямоугольный блок данных матрицы-результата (ниже рисунка приведена программа умножения, представляющая гнездо из 3-х вложенных циклов при соответствии индексов рис. 35):
for(i=0;i<NRA;i++)
for(j=0;j<NCB;j++) {
C[i][j]=0.0;
for(k=0;k<NCA;k++)
C[i][j]+=A[i][k]×B[k][j];
}
- Реально можно суммировать частичные произведения в пределах одной строки/столбца (единичная ширина лент, всего таких сумм будет i×j); можно ещё уменьшить размер гранулы параллелизма, разби́в каждую из сумм на несколько частей (используется свойство ассоциативности операций сложения). Полезно исключить избыточность обме́нов данными путём исключения повторных пересы́лок строк матрицы [A] (или столбцов матрицы [B]), организовав для каждой ленты строк [A] цикл по столбцам [B] (или для столбцов [B] цикл по строкам [A]); таким путём снижается число обменов почти вдвое.
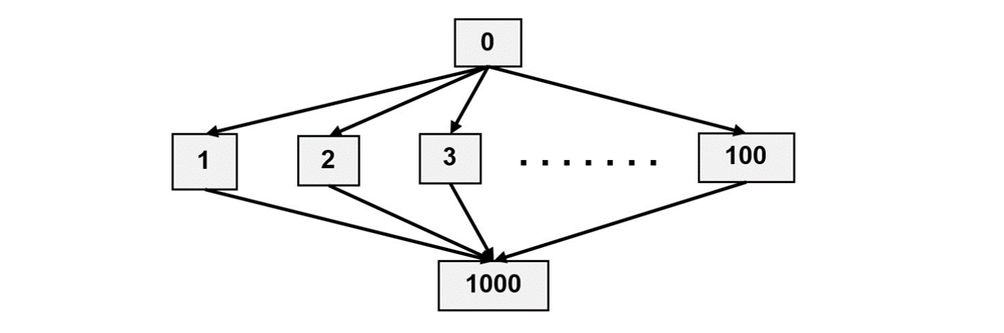
Укрупнённый вид ЯПФ информационного графа алгоритма приведён на рис. 36 (вершины 0 и 1000 представляют исходные и рассчитанные данные соответственно, вершины 1÷100 – параллельно выполняющиеся прямоугольные блоки C[i][j]+=A[i][k]×B[k][j]). Обычно ширина каждой ленты матрицы принимается равной N/P (при делении не на́цело ширина последней ленты равна остатку от целочисленного деления).
Заметим, что собственно вычисления сосредоточены в блоках 1÷100 и фактически представляют единственный ярус ЯПФ. Такой подход часто употребляется при расчётах на вычислительных кластерах, при этом каждый блок выполняется на заданном вычислительном узле кластера. Обычной практикой является подгонка ширин лент под заданный размер матриц, однако в случае нехватки оперативной памяти ширину ленты приходится ограничивать и, следовательно, выполнять блоки не в одну (параллельную) стадию, а в несколько последовательных.
При порядке матриц N размер гранулы параллелизма равен (N^3)/P действий (сложения с накоплением произведений), размер пересылаемых данных 2×(N^2)/P чисел (а при модификации с целью избежания дублирования при передаче данных почти вдвое меньше); приведённые формулы дополнительно свидетельствуют о выгодности использования гранул параллелизма максимального размера (время выполнения гранулы растёт быстрее времени обмена данными в N раз; в результате можно считать kгран≈с×N , где с – постоянная). При ма́лости N (условие kгран≪1) возникает известное явление сетевой деградации вычислений – с ростом числа вычислительных узлов производительность параллельной вычислительной системы падает (вычислительные узлы начинают сильно конкурировать меж собой в части обмена данными и тем самым “мешать друг другу”).
Соответствующий gv-файл (сокращённо) приведён ниже.
#
// Valery Bakanov research computer complex (2008 and further);
// e881e@mail.ru, http://vbakanov.ru/left_1.htm
# Total edges in this directed graph: 200
/* This file was hand-crafted algorithm for banded matrix
// multiplication */
#
digraph M_MATR_BAND_100 {
; рассылка данных с узла #0 к узлам #1 ÷ #100
0 -> 1 ;
0 -> 2 ;
0 -> 3 ;
; строки от 0->4 до 0->99 опущены
0 -> 100 ;
; сбор данных от узлов #1 ÷ #100 к узлу #1000
1 -> 1000 ;
2 -> 1000 ;
3 -> 1000 ;
; строки от 4->1000 до 99->1000 опущены
100 -> 1000 ;
}
Воспользуемся ранее опробованным методом исследования – зафиксируем параметры полученных планов параллельного выполнения для числа вычислителей от ширины ЯПФ до единицы (последовательное выполнение) для двух ранее используемых эмпирик преобразования WidthByWidth и Dichotome. Разница в результатах позволит Исследователю оценить достоинства и недостатки этих эвристик и, надеюсь, улучшить их в дальнейших разработках.
На риc. 37 приведены результаты расчётов планов параллельного вычисления программы умножения матриц согласно графа рис. 36 (ось абсцисс – число параллельных вычислителей; графики a), b), b) – число ярусов, ширина и вычислительная трудоёмкость преобразования ЯПФ соответственно; кривые 1 и 2 – результат применения эвристик WidthByWidth и Dichotomy соответственно).
- Вду́мчивый Читатель понимает, конечно, что наклонные прямые 2 на рис. 37 b) и c) являются результатом гру́бости дискретизации при табулировании функции (в полном согласии со смыслом эвристики Dichotomy они в реальности представляют собой вертикали, естественно)!
Полученные данные очень показательны. Если изменение ширины (рис. 37 а) при использовании двух методов реформирования ЯПФ малоотличимо, то зависимости высоты и особенно трудоёмкости преобразования (рис. 37 б) и в) сильно отличаются для двух вышеуказанных эвристик преобразования ЯПФ. В целом следует отдать предпочтения методу WidthByWidth (кривые 1 на рис. 37) как менее затратному с точки зрения трудоёмкости преобразования ЯПФ и более предсказуемой и точной (практически прямо пропорциональной относительно исследуемому параметру) зависимости времени выполнения алгоритма (хотя в некоторых случаях наблюдается преимущество эвристики Dichotomy – соответствующий график на рис. 37 b) располагается ниже графика метода-конкурента WidthByWidth). При дальнем улучшении процедуры целенаправленного изменения ЯПФ в целях построения рациональных планов выполнения параллельного приложения может быть рассмотрена целесообразность разумного объединения методов WidthByWidth и Dichotomy (например, на основе их поочерёдной работы в рамках единой эвристики).
Для осмысления правил полученного распределения операторов по ярусам на рис. внизу приведён вариант для заданного числа вычислителей P=30 (план параллельного выполнения получен согласно эвристики WidthByWidth). Хорошо виден результат преобразования ЯПФ, справа показана диаграмма распределения ширин ЯПФ . Единый ярус вычислений преобразован в 3 яруса по точному соответствию Ŵ=P последний (4-й) ярус содержит оставшееся до 100 число операторов. При заданном P=30 плотность кода при таком плане выполнения равна kи=0,83.
Полученный согласно эвристике Dichotomy план параллельного выполнения приведён ниже. Согласно описанному подходу общее число операторов 100 дважды разбивается пополам, при такой декомпозиции получилось 4 яруса по 25 операторов (5 вычислителей остаются незадействованными). Плотность кода также равна kи=0,83.
Т.о. показана возможность применения методики целенаправленной модификации ЯПФ и в случае значительного размера гранул параллелизма (макропараллелизм).
“Вычислительная трудоёмкость скрывается в циклах”…
Ранее упомянутая исследовательская система V-Ray направлена на анализ программ с циклами (в самом деле, “Вычислительная трудоёмкость скрывается в циклах!”).
На рис. 38 a) показан пример анализа алгоритма для конкретной задачи; исходные для расчётов данные вводятся в вершинах, расположенных вдоль левой, нижней и правой сторон показанной области, вычисления происходят слева/снизу/справа снизу вверх; каждая операция одного яруса требует трёх аргументов) уровня машинных команд (гранула параллелизма составляет одну команду - микропараллелизм). На рис. 38 b) приведён результат объединения вершин в структуры бо́льшего размера (серые многогранники составляют укрупнённую гранулу - макропараллелизм). При нахождении гранул макропараллелизма автор процитированной работы использует понятие обобщённых развёрток (функций, заданных над вершинами ориентированного графа и удовлетворяющая определённым условиям). Как и в первом, так и во втором случае выполнение гранул параллелизма возлагается на один вычислитель; информационные связи при выполнении укрупнённых гранул осуществляются через вершины, лежащие на границах многогранников.
- Размер собственно многогранников может быть укрупнён и далее, что выгодно с точки зрения повышения коэффициента грануляции kгран. Согласно анализу автором показано, что в общем случае при реализации микроопераций на одном вычислителе число выполняемых им операций алгоритма растёт кубично, а связей между операциями – квадратично.
Из известных специализированных систем разбиения графов в первую очередь следует назвать библиотеку METIS/ParMETIS (университет Миннесоты, 1998÷2003). Надо сказать, что вследствие NP-полноты процедуры разработчики алгоритмов разбиения графов (получение ЯПФ – лишь одна из задач такого рода) большой размерности зачасту́ю также прибегают к эвристическим методам (см., напр., Kernigan & Lin).
Авторские ресурсы:
- Cloud Mail.ru: https://cloud.mail.ru/public/X469/7VmM6aonX