Исследовательский инструмент ПРАКТИКУМ DF
На рис. 11 показан пользовательский интерфейс программы DATA-FLOW (при проблемах прямой вы́грузки с сайта автора воспользуйтесь зеркалом), являющейся частью инструмента для исследований ПРАКТИКУМ DF. Данный программный продукт (формат Win’32, GUI) доступен для свободной выгрузки и подробно описан в прилагаемой книге. Установка с инсталляционной версии instаll_df.ехе (MD5: 974cec8e049244c28a9149bc1b7c4673), запуск с файла dаtа_flоw.ехе (MD5: 41f6f890df7aa9763043142d2c24e10c). Свидетельство Роспатента о государственной регистрации #2018665726 от 10.12.2018; руководство Исследователя, репозиторий GitHub.

Т.к. программный модуль data_flow.exe при работе использует некоторые данные с сервера разработчика, будьте готовы при первом запуске программы после сообщения брандмауэра Защитника Windows разрешить до́ступ указанного исполняемого файла к серверу разработчика (впрочем, запрет доступа не ухудшит существенно качество работы программы).
- Данная программная система удовлетворительно функционирует под WINE (“Wine Is Not an Emulator”) в Unix-подобных операционных системах.
Этот программный продукт является симулятором Data-Flow машины (близкий к граф-машине), предназначенным для проведения исследований по выявлению в произвольных алгоритмах скрытого параллелизма и выполнения данного алгоритма на гомогенным поле параллельных вычислителей разного количества и при разных дисциплинах обслуживания данных выходного коммутатора.
Автору данной работы очень импонирует идея об использовании граф-машины в качестве “хорошего инструмента для изучения любых существующих и даже еще не существующих реализаций конкретного алгоритма”, высказанная акад. Валентином Воеводиным на стр. 68 (2-й абзац снизу) в его книге “Вычислительная математика и структура алгоритмов”.
Библиотека программ (алгоритмов) для исследований
Список имеющихся программ (библиотека) для данного симулятора (set-файлы) приведён в таблице ниже (после инсталляции программного продукта эти файлы окажутся в текущем каталоге системы). По умолчанию все файлы расположены в текущем каталоге системы. Исследователь имеет возможность добавлять в библиотеку новые программы.
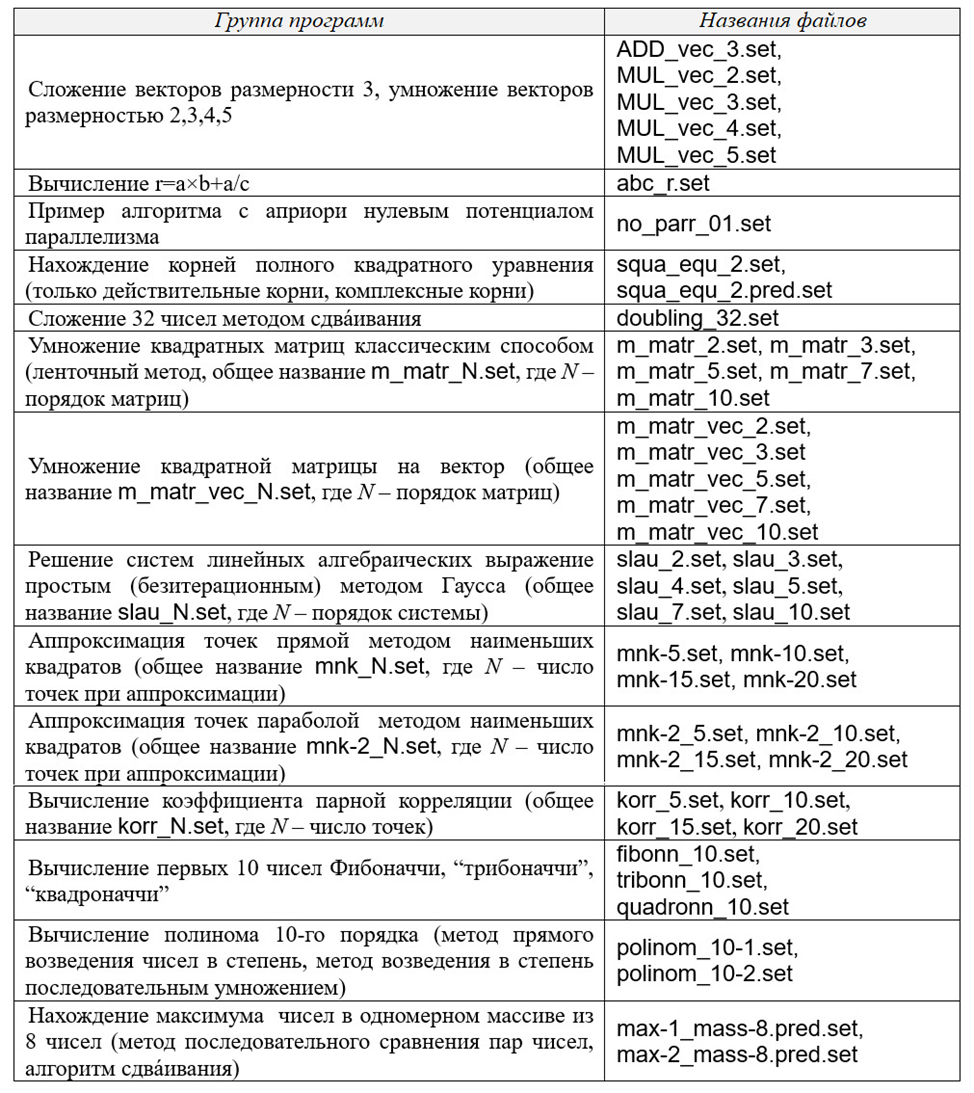
Все программы разработаны в императивном стиле, имеют ассемброподобный синтаксис в стиле AT&T (“результат праве́е операндов”), отдельные строки исходного кода имеют свободное расположение (не сгруппированы в порядке выполнения, а соответствуют идее “облака операторов”). Условность выполнения реализована методом предикатов, реализован принцип “единократного присваивания“ (все переменные создаются однократно и далее доступны только по чтению). Работа с псевдомассивами реализуется посредством ма́кросов, все действия производятся над 64-битовыми вещественным числами. Симулятор выполняет программы не в реальном масштабе времени, а в замедленном (масштаб времени можно задавать в относительных единицах – ти́ках, длительность которых определяется в долях секунды).
- Обратите внимание, что большинство программ представлено не менее с чем 4-мя размерами обрабатываемых данных (для задач линейной алгебры это, напр., порядок обрабатываемых матриц). Связано это с тем, что графы алгоритмов параметризо́ваны (“зависят от…”) по размеру обрабатываемых данных (при неизменности собственно алгоритма).
Формат команд системы DF с использованием предикатов приведён ниже (квадратные скобки означают необязательность заключённого в них текста, знак ‘¦’ позволяет выбрать один из двух расположенных слева и справа от него символов):
ADD Op1 [, Op2], Res [?¦, Pred] [; комментарий до конца строки]
где ADD – мнемоника команды (здесь - сложение), Оp1 и Оp2 – аргументы (операнды) команды, Res – результат выполнения команды, Pred – необязательное имя предиката (при отсутствии считается true), символом-разделителем перед полем предиката могут служить ‘?’ или ‘,’ ; перед именем предиката допускается символ отрицания ‘!’. Как принято, в квадратных скобках указаны необязательные поля.
Напр., вышеупомянутое решение полного квадратного уравнения (в вещественных числах) программно выглядит так (после символов “|||” указаны номера операторов, после символа “;” следует комментарий до конца строки):
; Решение полного квадратного уравнения (файл squa_equ_2.set)
; в вещественных числах (неотрицательный дискриминант)
; A×X^2 + B×X + C = 0
; автор - великий индийский астроном и математик
; БРАХМАГУПТА (7-й век н.э.)
; in case A = 1, B = 7, C = 3
; the solve is: X1 = -0.45862 , X2 = -6.5414
;
MUL A, TWO, A2 ; A2 ← 2 * A ||| #100
MUL A, FOUR, A4 ; A4 ← 4 * A ||| #101
MUL B, NEG_ONE, B_NEG ; B_NEG ← NEG_ONE * B ||| #102
POW B, TWO, BB ; BB ← B^2 ||| #103
MUL A4, C, AC4 ; AC4 ← A4 * C ||| #104
SUB BB, AC4, D ; D[iskriminant] ← BB - AC4 ||| #105
SQR D, sqrt_D ; sqrt_D ← sqrt(D) ||| #106
;
ADD B_NEG, sqrt_D, W1 ; W1 ← B_NEG + sqrt_D ||| #107
SUB B_NEG, sqrt_D, W2 ; W2 ← B_NEG - sqrt_D ||| #108
DIV W1, A2, X1 ; X1 ← W1 / A2 ||| #109
DIV W2, A2, X2 ; X2 ← W2 / A2 ||| #110
;
SET 1.0, A ; A ← 1.0
SET 7.0, B ; B ← 7.0
SET 3.0, C ; C ← 3.0
SET 2, TWO ; TWO ← 2
SET 4, FOUR ; FOUR ← 4
SET -1, NEG_ONE ; NEG_ONE ← (-1)
А та же программа (с учётом возможности появления комплексных результатов) при использовании предикатов выглядит так (условность выполнения управляется предикатом IS_re):
; Решение полного квадратного уравнения для получения
; решения в комплексных числах (файл squa_equ_2.pred.set
; из подкаталога ./PrP_Examples) используем флаг предиката IS_re
; IS_re есть true при значении дискриминанта D>=0
; (вещественные корни) и и false в противоположном случае
; A×X^2 + B×X + C = 0
; in case A = 1, B = 7, C = 3
; the solve is: re_X1=-0.45862,im_X1=0; re_X2=-6.5414,im_X2=0
; in case A = 1, B = 3, C = 3
; the solve is: re_X1=-1.5,im_X1=0.866; re_X2=-1.5,im_X2=-0.866
;
MUL A, TWO, A2 ; A2 ← 2 * A
MUL A, FOUR, A4 ; A4 ← 4 * A
MUL B, NEG_ONE, B_NEG ; B_NEG ← NEG_ONE * B
POW B, TWO, BB ; BB ← B^2
MUL A4, C, AC4 ; AC4 ← A4 * C
SUB BB, AC4, D ; D[iskriminant] ← BB - AC4
;
SET 1, A ; A ← 1
SET 3, B ; B ← 7/3
SET 3, C ; C ← 3 SQR D, sqrt_D, IS_re ; sqrt_D ← sqrt(D)
ADD B_NEG, sqrt_D, W1, IS_re ; W1 ← B_NEG + D_SQRT
SUB B_NEG, sqrt_D, W2, IS_re ; W2 ← B_NEG - D_SQRT
DIV W1, A2, re_X1, IS_re ; re_X1 ← W1 / A2
DIV W2, A2, re_X2, IS_re ; re_X2 ← W2 / A2
;
MUL D, NEG_ONE, NEG_D, !IS_re ; NEG_D ← NEG_ONE * D
SQR NEG_D, sqrt_D, !IS_re ; sqrt_D ← sqrt(NEG_D)
DIV B_NEG, A2, re_X1, !IS_re ; 1-th root (real)
DIV sqrt_D, A2, im_X1, !IS_re ; 1-th root (img)
CPY re_X1, re_X2, !IS_re ; 2-th root (real)
DIV sqrt_D, A2, W, !IS_re ; temp for im_X2
MUL W, NEG_ONE, im_X2, !IS_re ; 2-th root (im)
;
SET 2, TWO ; TWO ← 2
SET 4, FOUR ; FOUR ← 4
SET -1, NEG_ONE ; NEG_ONE ← (-1)
SET 0, ZERO ; ZERO ← 0
;
PGE D, ZERO, IS_re ; IS_re ← “true” if D>=0
- Ну, на́чали! Как известно, учиться эффективнее всего на практических примерах. Начинаем с самого простого – тестирование работы инструмента ПРАКТИКУМ DF(конечно, предварительно нужно вы́грузить на собственный компьютер инсталляционную версию и установить её). Загруж́аем (Ctrl+O) исполня́емый файл squa_equ_2.set (имя файла без расширения является именем исследуемого проекта) и нажимаем клавишу Выполнение (или F9). Пару минут любуемся переливами цвето́в (выполняемую команду системы индицирует голубым в строке Мнемо (мнемоника машинных инструкций) и иными цветами условие ГКВ для команд и др.) на экране и появлением имён переменных вместе с их значениями в окне Данные (в скобках – общее число). При окончании расчёта система выводит окно интенсивности вычислений (опи́сано ранее в этой же публикации), по Ctrl+F6 дополнительно выдаётся график Ганта (информационные зависимости при выполнении вычислений). Повто́рим то же самое для программного файла squa_equ_2.pred.set.
- На данном этапе исследования для нас максимальный интерес представляют “картинки” графиков интенсивности вычислений (для копирования активного окна используйте Alt+Enter) – они очень информативны! Проанализируйте их форму, определите максимальное число использованных при решении целевой задачи параллельных вычислителей, обратите внимание на дости́гнутый коэффициент ускорения (убыстре́ния) вычислений при распараллеливании. На всякий случай – в поле ввода “Число АИУ (вычислителей)” сначала зада́йте некое большое число (напр., 1’000) и проанализируйте, сколько реально параллельных вычислителей программа использовала (при значении этого параметра равным единице получаем чисто последовательный вариант вычислений – без распараллеливания).
- Не хочу “забегать вперёд”, но по клавише F7 выдаётся файл информационного графа алгоритма данной программы (в международном DOT-формате). Вариант главного меню “Файлы->Сохранить все файлы протоколов в каталоге системы” выполняет именно то, что имеется в виду. Любым текстовым редактором откройте файлы с именем проекта (*.gv, *.dat, *.pro etc, где ‘*’ – имя проекта) и ознакомьтесь с их содержимым (подробная информация в файле Base.pdf).
Естественно, первый (имеющий наиболее важное практическое значение) вопрос исследования – а как зависит время выполнения программы от числа отдельных вычислителей? Используйте поле ввода с названием “Число АИУ” (сиречь отдельных “Арифметических Исполнительных Устройств”, отдельных вычислителей); при зада́нии в этом поле значения 1 получаете вариант последовательного выполнения (общее время выполнения программы равно сумме времён выполнения отдельных операторов).
Второй по важности параметр для исследования – размер обрабатываемых программой (алгоритмом) данных. В set-файлах размер обрабатываемых данных выражается последним (после символа подчёркивания) числом (это или порядок ма́триц или количество обрабатываемых точек).
Для желающих убедиться в том, что порядок расположения операторов незна́чим для пото́кового (Data-Flow) вычислителя можно рекомендовать выполнить вариант “Самое УДИВИТЕЛЬНОЕ” главного меню (при этом строки исходного кода перемешиваются случайным образом и программы вновь запускается на выполнение – результат, естественно, остаётся неизменным).
Применение псевдомассивов при программировании в исследовательском инструменте ПРАКТИКУМ DF
Во многих случаях (особенно для сильносвязанных вычислительных систем) использование регистра-счётчика команд затруднительно. Альтернативой служит применение предика́тов для управления последовательностью вычислений. Предикатный метод имеет ряд преимуществ по равнению с использование счётчика команд – поток команд стано́вится линейным (устраняются условные и безусловные перехо́ды) и отпадает необходимость в предсказании перехо́дов в программах; недостаток – невозможность переходов “назад”.
Однако при такой организации системы команд имеются трудности организации итерационных циклов; механизм псевдомассивов даёт возможность реализации итераций (реку́рсии) без нарушения режима единократного присваивания; При такой организации вычислений переменные каждого итерационного цикла располагаются в последовательных индексах псевдомассивов.
Синтаксис препроцессорной команды (ма́кроса) for для работы с одномерными (1D) псевдомассивами (псевдомассивы формально выглядят как обычные массивы с индексными переменными, однако фактически представляют собой обычные переменные соответствующего вида) приведён ниже (между элементами допускается любое количество пробелов):
for[i]=i1,i2,i3 { ; заголовок макроса
...инструкция #1
SET f(i), A ¦ M[f(i)] ;
ADD A ¦ M[f(i)], A ¦ M[f(i)], A ¦ M[f(i)] ;
...
...инструкция #N
} ; конец макроса
Описание синтаксиса макроса:
• f(i) – функция от переменной-индекса псевдомассива (в качестве индекса используется единичный буквенный символ, данном случае это i) или выражения над числами - поддерживаются основных операций: сложение (+), вычитание (-), умножение (⁎), деление (/), остаток от деления (%) и возведение в степень (^), набор стандартных функций: sin, cos, tg, ctg, arcsin, arccos, arctg, arcctg, sh, ch, th, cth, exp, lg, ln, sqrt, круглые и квадратные скобки любой вложенности,
• i1,i2,i3 - целые числа, определяющие начальное, конечное значения изменения переменной индекса цикла и шаг оного изменения,
• A – простая переменная,
• M[] – псевдомассив (имена псевдомассивов должны начинаться с буквы, длина до 32 символов),
• поле предиката в макросах также может использоваться.
Т.о. при включении в тело макроса for[i]=1,100,1 для переменной Val[i] макрос сформирует последовательность простых переменных Val[1], Val[2], …Val[100]. Для 1D-макроса значения i вычисляются как функция только от i; для 2D-макросов - от i и j соответственно (имена индексных переменных должны соответствовать заявленным в заголовке макроса). Переход от итерации k к следующей k+1 осуществляется присваиванием типа Val[k+1] ← Val[k] (и расши́ренно относительно вычислению значений индексных переменных).
Макрос для работы с двумерными (2D) псевдомассивами приведён ниже:
for[i:j]=i1,i2,i3:j1,j2,j3 { ; заголовок макроса
...инструкция #1
SET f(i,j), A ¦ M[f1(i,j):f2(i,j)] ;
ADD A ¦ M[f1(i,j):f2(i,j)], A ¦ M[f1(i,j):f2(i,j)], A ¦ M[f1(i,j):f2(i,j)] ;
...
...инструкция #N
} ; конец макроса
где f1(i,j) и f2(i,j) – функции от переменных-индексов псевдомассивов i и j (причём первый рассматривается как управляющий внешним, а второй - внутренним из вло́женных циклов), символ ‘:’ служит раздели́телем индексов.
- Основная область применения 2D-псевдомассивов – линейная алгебра (операции с одно- и двумерными матрицами). Надеюсь, вдумчивый Читатель (Исследователь) без излишних затруднений сообразит, как рационально использовать предоста́вленную возможность (пример практического использования псевдомассивов - см. публикацию #011).
Заметим, что возможен режим спекулятивного выполнения инструкций (“режим Itanium'а) - инструкции исполняются, но результат выполнения теряется после завершения (режим устанавливается при ненулевом значении переменной SpeculateExec в секции [RuleSpeculateExec] файла настроек DATA_FLOW.INI); в проти́вном случае инструкции даже не распределяются для выполнения свободными вычислителями.
Нюансы использования исследовательского инструмента ПРАКТИКУМ DF, возможности отладки программ и форматы выходных данных подробно описаны в документе Base.pdf.
Вопрос – а зачем мы сначала создали исполняемый set-файл и только потом “по нему” создаём граф-файл (то, что называем ИГА – Информационный Файл Алгоритма)? Ответ – не у всех такой уровень интеллекта, какой наличествует у Эдсгера Вэйба Дейкстры – великого АЛГОРИТМи́СТА, за всю свою жизнь не написавшего ни единой строки кода…
- Это, конечно, шутка (при́званная затушевать проблему). Ответ а самом деле такой – мы с Вами рассматриваем исследовательский инструмент (не зря он именуется ПРАКТИКУМ). Инструмент предполагает наличие объектов исследований – ими и является (вышеприведённый) набор программ (библиотека). На этом наборе отрабатываются методы исследования, которые в дальнейшем предлагаются для применения на практике.
- Целевыми потребителями разработанных методов генерации расписаний параллельного выполнения программ в первую очередь являются разработчики трансляторов и виртуальных машин, исследователи свойств алгоритмов (в направлении нахождения и рационального использования потенциала скрытого их параллелизма). Информационный граф алгоритма без труда восстанавливается на основе анализа причинно-следственных связей в исходном коде при работе компилятора; при этом логично библиотечные процедуры обрабатывать (компоновать) отдельно, используя имеющиеся наработки.
Итак – приступаем! Разработали план эксперимента и начинаем его выполнять…