Как это славно - вовремя помереть!.. // Братья Стругацкие. ГАДКИЕ ЛЕБЕДИ, 1967.
В процессе вычислений постоянно “вырабатываются” (как результат выполнения операций) и “потребляются” (как операнды) данные. Эти данные могут быть как локальными (определёнными “внутри” данного алгоритма), так и глобальными (их область видимости простирается за пределы данного алгоритма). Логично определить сущность TLD (Temporary Local Data), представляющую локальные данные (глобальные данные фактически входят в область понятий входных и выходных данных). Интерес к TLD-данным понятен – частота обращения к ним определяет возможность расположения их в кэш-памяти (или даже во внутренних регистрах процессора – разница по времени доступа к этим слоям памяти достигает многих сотен раз, а размеры кэша и регистровой памяти всегда ограничены).
Важно, что анализ TLD в режиме выполнения программы, а не в режиме реализации алгоритмико-ориентированного подхода. Как было сказано ранее в публикации #001, при АОП временны́ми парамерами обычно пренебрегают. Однако именно TLD-параметры могут значительно (не в лучшую, естественно, сторону) изменить характеристики выполнения программы. При абстракции от TLD остаётся согласиться с критическим высказыванием пользователя “ereinion” от 24.08.2021 г. - “При использовании в качестве процессоров общего назначения, VLIW пока не смогли преодолеть свой главный недостаток — высокие требования к культуре разработки и сложность создания компиляторов”.
Т.к. инструмент DF фактически выполняет вычисления, появляется возможность отслеживания числа обращений к переменным (при условии единократного присваивания результат получится с некоторым избытком). Само понимание существования “временно живущих данных” важно для понимания учащимися принципов функционирования вычислительных систем.
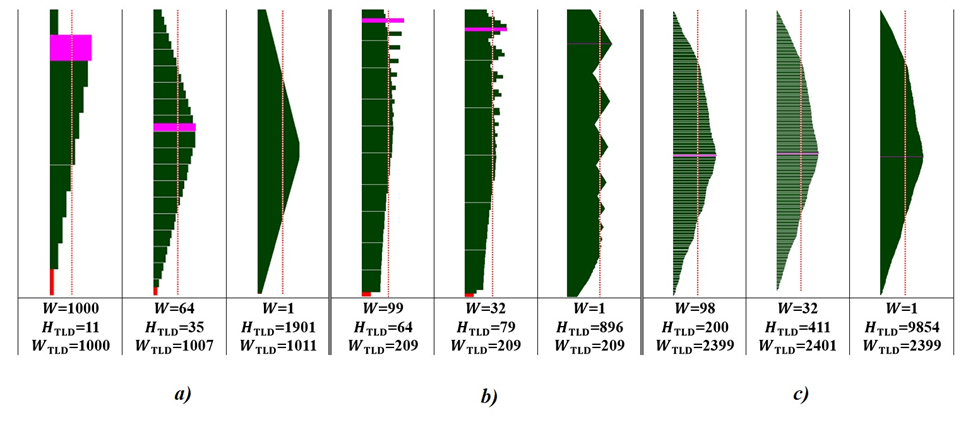
На рис. 32 приведены линейчатые т.н. TLD (Temporary Local Data) диаграммы распределения размеров временных локальных данных. Размер данных определяется в единицах некоторых обобщённых величин, для определения реальных размеров данных (напр., в байтах) используется информация из пула мер линий передачи данных.
Обычно (три слева направо расположенные линейчатые диаграммы) фиксируется исходное состояние (W=1000), некоторое промежуточное состояние (W=64 или W=32) и режим последовательного выполнения (W=1) для конкретного алгоритма. На рис. 32 через HTLD и WTLD обозначены высота и ширина TLDпо ярусам ЯПФ. Видно большое разнообразие в распределении TLD-данных по ходу выполнения алгоритма (для упрощения сравнения высо́ты графиков одинаково масштабированы).
На рис. 33 представлен размер TLD-данных для различных степеней “ужа́тия” по ширине (ось абсцисс) ленточной диаграммы алгоритма умножения квадратных матриц 2÷10-го порядка с иллюстрацией расположения максимума TLD-диаграмм вдоль этой оси (можно утверждать, что экстремумы практически постоянны). Интересный момент – для учащихся это часто представляется необычным - им кажется, что c возрастание высоты ЯПФ (включая последовательное выполнение) размер TLD-данных должен уменьшаться (некий аналог теоремы о среднем определённого интеграла); данные рис. 33 развеивают это заблуждение.
Кстати, на сайте AlgoWiki имеется специальный подраздел “Профиль обращения в память” и подразделы отделения специальных оценок взаимодействия программ с памятью – gaps (daps estimation) и cvg (cvg estimation).
В заключение – об интересной особенности формы кривой интенсивности вычислений, могущей быть практически выгодной в смысле уменьшения вычислительной трудоёмкости преобразования ЯПФ.
"Верхний" и "нижний" варианты ЯПФ
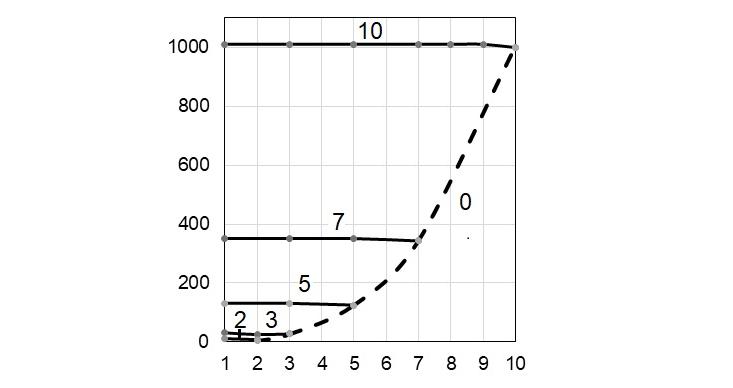
Оба варианта (“верхний” и “нижний”) получения ЯПФ (в первом случае все операторы максимально "прижа́ты" к началу программы, во втором - к концу оной; назовём их ЯПФ(в) и ЯПФ(н) соответственно) требуют одинаковой вычислительной сложности при получении, но параметры их сильно отличаются (рис. 34).
Как видно из рис. 34, характер диаграмм интенсивности вычислений для ЯПФ(в) сохраняется; в случае использования ЯПФ(н) имеется явная тенденция к смещению максимума диаграмм ЯПФ к конечной части диаграммы (да и собственно неравномерности распределения – что хорошо видно по расположению пунктирной прямой, показывающей среднеарифметическое значение ординат кривой интенсивности вычислений). А раз вычислительная трудоёмкость получения ЯПФ(в) и ЯПФ(н) одинакова, есть резон начинать процесс целенаправленной модификации с состояния именно ЯПФ(н), при этом основным направлением переноса операторов будет “снизу вверх”. Обосновать (возможные) преимущества использования ЯПФ(н) при построении рациональных планов выполнения параллельных программ – задача Исследователя (возможно, из лица Читателей)..!
В дальнейшем ничто не препятствует Исследователю (а я уверен - Читатель уже на пути превращения в него!) обратиться и к более изощрённым методам построения планов параллельного выполнения программ - напр. :
① защита диссертации А.Н.Черных (словами соискателя “работа носит теоретический характер”),
② хорошее (с подробным описанием методов планирования) учебно-методическое руководство предлагает А.А.Прихожий (Минск).
и так далее.
Нельзя считать невозможными дальнейшие усовершенствования эвристических методов целенаправленного преобразования ЯПФ как каркасов планов параллельного выполнения алгоритмов (программ). В действительности указанные показатели могут оказаться не полностью достижимыми (вследствие труднопредсказуемых ограничений при схемотехнической реализации), однако это величины, на которые можно опираться.
Дальнейшие методы повышения степени использования поля параллельных вычислителей в случае выполнения алгоритмов с ограниченным потенциалом параллелизма (напр., разделение параллельного вычислительного поля несколькими приложениями одновременно) не анализировались вследствие требуемого излишнего усложнения планировщика задач местной операционной системы.
Как сказано, целевыми потребителями разработанных методов генерации расписаний параллельного выполнения программ в первую очередь являются разработчики трансляторов и виртуальных машин, исследователи свойств алгоритмов (в направлении нахождения и рационального использования потенциала скрытого их параллелизма). Информационный граф алгоритма без особого труда восстанавливается на основе анализа причинно-следственных связей в программе после завершения работы компилятора; при этом логично библиотечные процедуры обрабатывать (компоновать) отдельно, используя имеющиеся наработки.
Авторские ресурсы:
- Cloud Mail.ru: https://cloud.mail.ru/public/5n6e/C8p1WWW78
Информация о канале вообще и его оглавление…
- В работе мы будем использовать специализированное авторское программное обеспечение (фактически исследовательские инструменты), предназначенное для выявления в произвольных алгоритмах параллелизма и его рационального использования при вычислениях.
В.М.Баканов. Практический анализ алгоритмов и эффективность параллельных вычислений. ISBN 978-5-98604-911-3. 2023. LitRes.ru