Эмоциональное обращение к Читателям
Начиная достаточно серьёзное исследование, следует “сказать пару слов”. В первую очередь – ЗАЧЕМ? С какой целью? Что мы хотим узнать?.. Говорят – Наука наце́лена на Будущее… вот это Будущее мы и хотим узнать! Кстати, огромное количество людей безразли́чно к Будущему (конечно, исключая примитивные моменты чисто личного характера – болезни, жизненный успех etc)… но автор обращается не к таким персона́лиям, конечно!..
- Логично утверждение, что наиболее практично ставить эксперименты по влиянию размера обрабатываемых данных (при неизменном алгоритме обработки) на требуемые параметры вычислительного процесса. В самом деле – как изменятся этим параметры при увеличении размера данных вдвое?.. вчетверо?.. в восемь раз? Чисто технически удобнее использовать увеличение вдвое на каждом этапе.
При этом мы решаем чисто практическую задачу – с какими параметрами (из них основные - число параллельных вычислителей и объём оперативной памяти) понадобится вычислительные система для работы программы (построенной согласно данного алгоритма) с такими-то параметрами (размерами обрабатываемых данных)? В какой точке ресурсов данной вычислительной системы перестанет хвата́ть и потребуется переход на новую систему (если мы возжелаем увеличить размер обрабатываемых данных – напр., увеличить число узлов сетки – если мы используем сеточные методы расчёта - для повышения точности расчётов)? А может быть, необходимо разработать новую вычислительную систему, чтобы можно было на ней решать задачи с ещё бо́льшими требованиями к аппаратуре?..
Близкие методы исследований применял (конечно, много глубже, чем автор в своей работе) в своё время акад. Валентин Воеводин. Им предложена т.н. “теорема об информационном покрытии” (о формулировках здесь и тут), примени́мая к линейному классу программ. Решается всё тот же (чисто практический, кстати!) вопрос – предсказать, каким образом изменяются параметры (параллельной) вычислительной сложности алгоритмов при изменении их параметров (напр., максимальных значений индексов в индексных выражениях - а это определяет степень дискретизации при решении задач сеточными методами)? В зависимости от ответа определяется, какую вычислительную систему необходимо использовать для решения данной задачи (или наоборот - какой сложности задачу можно решить на данной системе). Может быть, уважаемым Читателям (когда-нибудь в будущем) удастся доказать эту теорему?..
Практически все вычислительные эксперименты (симуляции) в дальнейшем будут подчинены этой идее – “А что будет, если и дальше повышать размер обрабатываемых данных при неизменном алгоритме обработки”… И пусть порядок обрабатываемых матриц при моделировании не столь велик (в реальности Исследователи имеют дело с много-многотысячными порядками), основные тенденции мы прекрасно прочу́вствуем.
А как Вы думали – для чего в таблице в публикации #010 большинство программ (файлы с расширением *.set) предста́влены в нескольких вариантах? Напр., slau_5.set, slau_7.set, slau_10.set суть один и тот же алгоритм, но размеры обрабатываемых данных разли́чны (последнее число в имени файла есть порядок СЛАУ - Систем Линейных Алгебраических Уравнений)… Правда, есть минус – при этом реализуется всего лишь однофакторный эксперимент (изменяется только один параметр), но основная идея направления исследований по́нятна – в принципе можно проводить эксперименты с любым числом независимых параметров).
Вду́мчивый Читатель тут же спросит – а как же дело обстоит с совершенствованием самих алгоритмов (напр., алгоритмы Штрассена, Копперсмита-Вино́града, позволяющие значительно снизить вычислительную трудоёмкость умножения матриц? Увы, подобные проры́вы (разработка новых, значительно более эффективных алгоритмов для решения даже ставших классическими задач) случаются очень и очень нечасто и на них обычно рассчитывать не приходится...
Ну а теперь пришло время “королей информати́вности” – графиков!..
На рис. 17 приведены результаты вычислительных экспериментов на ПРАКТИКУМЕ DF по изучению влияния числа параллельных вычислителей на величину максимального ускорения вычислений - думаю, Вы помните что согласно формулы (1) мы приняли, что ускорение вычислений есть отношение времени выполнения последовательного варианта алгоритма (программы) к времени выполнения параллельного (а сейчас уточняем – в условиях неограниченного параллелизма).
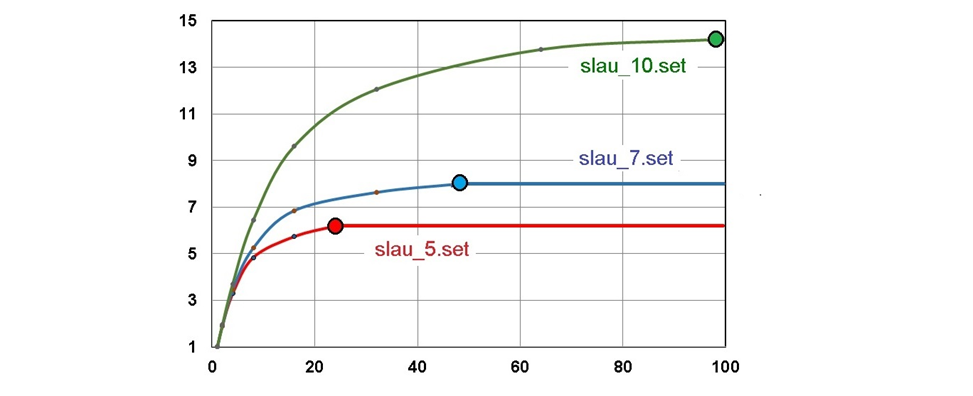
Из рис. 17 видим удивительное явление - в некоторый момент ускорение вычислений перестаёт увеличиваться и остаётся постоянным (выходит на область “плато”)! Эти моменты выделены разноцветными кружками и являются разными для разных размеров обрабатываемых данных (видно, что исследованы были программы решения СЛАУ (Систем Линейных Алгебраических Уравнений) 5, 7 и 10-го порядков (алгоритм решения не изменился – метод последовательного исключения). Конкретно – ускорение перестаёт возрастать для СЛАУ 5-го порядка при числе параллельных вычислителей около 24, 7-го – при числе вычислителей 48 и 10-го порядка – при числе вычислителей более 99.
Из полученных данных следуют два практических вывода (позволю себе обобщить частные результаты эксперимента на всеобщие):
① потенциал распараллеливания на заданном уровне (в данном случае это мелкозерни́стый, fine-grained, ILP - уровень машинных инструкций) каждого конкретного алгоритма (программы) ограничен и не может быть больше вполне определённой величины,
② характер кривых говорит о том, что в большинстве случаев при экономии средств (на число параллельных вычислителей) несильно отличающиеся от предельных значений максимума ускорения могут быть достигнуты при числе параллельных вычислителей в 50÷70% от максимума.
Второй вывод сделан на основе замедления возрастания приведённых кривых вблизи точек максимумов ускорения вычислений и обладает явной практической ценностью.
На рис. 18 приведена уточнённая зависимость ускорения вычислений от числа задействованных параллельных вычислителей для процедуры умножения квадратных матриц традиционным методом (последняя цифра в имени файла – порядок перемножаемых матриц). Хорошо видно, что зависимость на самом деле кусочно-линейная, причём состоит (в области максимального числа АИУ) из горизонтальных и вертикальных прямых. Напр., для M_MATR_10.SET максимальное ускорение вычислений достигается не только при P=1000, но и в диапазоне 550≤P≤1000.
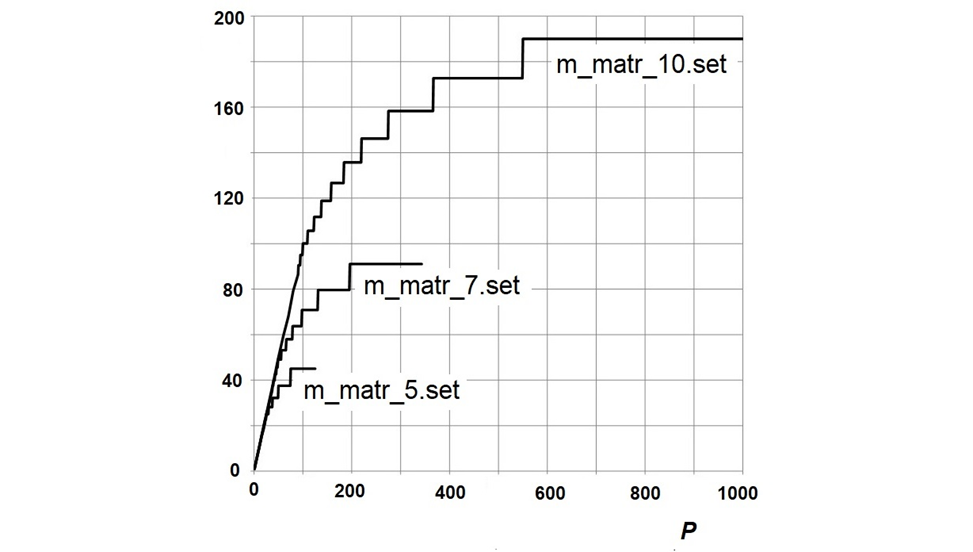
Логично назвать это эффект демпфи́руемостью (амортизацией) процесса выполнения программ на граф-машине. Явление демпфируемости является следствием взаимодействия алгоритма при его выполнении с исполняющей системой (конкретно – буфером команд) и очень полезно с точки зрения экономики вычислительной системы (позволяет получить экстремальную производительность при экономии значительной части АИУ). Для иных алгоритмов демпфируемость меньше, но присутствует в большинстве случаев. У автора исследования вызывает (внутреннее) удовлетворение, что уточнённый анализ подтверждает данные предварительного.
Графики рис. 17÷18 рази́тельно напоминают таковы́е, иллюстрирующие закон Паре́то (1897, пра́вило 80/20). Что ж, тако́е действительно иногда встречается в повседневной жизни..!
На рис. 19 приведены данные экспериментов для двух алгоритмов (программы из файлов M_MATR_N.SET и SLAU_N.SET на а) и b) соответственно, где N – порядок системы); кривые 1 показывают время выполнения алгоритма, 2 – минимально требуемое для реализации наискорейшего выполнения число вычислителей (P0), 3 – ускорение вычислений.
Кривые 1 даны в единицах числа выполняющихся ярусов операторов (эта величина получила название параллельной сложности алгоритма – аналогично числу действий при последовательном выполнении).
Зависимости рис. 19 информативны c точки зрения вычислительных практик – параллельная сложность представляет собой практически линейную зависимость от размера обрабатываемых данных (порядка матриц или систем СЛАУ), что благоприятно для вычислительных практик. Минимально необходимое для реализации наискорейшего выполнения алгоритма число вычислителей растёт быстрее линейной зависимости, что невыгодно в смысле роста затрат на оборудование. Ускорение вычислений растут быстрее линейной зависимости, что вы́игрышно. Заметим, что сказанное соответствует параметрам выполнения алгоритмов в режиме неограниченного параллелизма.
На рис. 20 приведены результаты моделирования выполнения алгоритмов M_MATR_10.SET и SLAU_10.SET на (графики a) и b)) при различном числе АИУ (параллельных вычислителей) от 1000/99 соответственно (режим неограниченного параллелизма) до 1 (последний вариант - последовательное выполнение); кривые 1 – число параллельно выполняющихся блоков операторов, 2 – минимально требуемое для реализации наискорейшего выполнения число вычислителей (P0).
Приведённые на рис. 20 зависимости времени выполнения от числа параллельных вычислителей являются, конечно, гиперболами с горизонтальной асимптотой, равной минимуму времени выполнении (максимум ускорения вычислений). Полученный характер изменения (с пла́то в области повышенных величин абсцисс) кривой 2 благоприятен для вычислительных практик – производительность мало снижается при довольно значительном сокращении (до половины) числа параллельных вычислителей (это выгодно с точки зрения минимизации стоимости вычислительных систем).
Такие вот параметры параллелизма удалось отыскать с использованием исследовательского инструмента DF. На самом деле это удивительно – вот перед нами была ассемблероподобная программа (не имеющая, кстати, никаких указаний на наличие или отсутствие свойств параллелизма в ней) – из неё некими чудесными манипуляциями извлечён наружу скрытый параллелизм и далее эта программа выполнена (точнее, эмулирована программным путём), причём на произвольном числе параллельных вычислителей..! Чудеса да и только… Следует констатировать, что исследовательский инструмент ПРАКТИКУМ DF показал себя во всей красе и надежды оправдал.
- А как Вы думаете – существуют алгоритмы, вообще не допускающие распараллеливания? Попробуйте протестировать (с помощью инструмента ПРАКТИКУМ DF, естественно) программы FIBONN_10.SET, TRIBONN_10.SET и QUADRONN_10.SET (вычисление первых 10 чисел Фибоначчи, “трибоначчи” и “квадроначчи” соответственно) – получите истинное удовольствие от результатов эксперимента (*)..!
* Автор в высшей степени злоко́знен и верит исключительно тому, что видит сам… “Что я слышу - я забываю. / Что я вижу - я запоминаю. /
Что я делаю - я знаю”. // Конфуций
Так что мы получим в результате экспериментов? FIBONN_10.SET можно запустить на выполнение с помощью исследовательского инструмента ПРАКТИКУМ DF, зада́в любое количество параллельных вычислителей (от 1 до 10^6, например) – всё равно получим чисто последовательное выполнение. Вывод – этот алгоритм не распараллеливается вообще (уточним – при размере гранулы параллелизма в одну арифметико-логическую операцию).
TRIBONN_10.SET (вычисление первых 10 чисел “трибоначчи”) даст чуть иной результат – при любом числе вычислителей P>2 увидим, что распараллелить на бо́льшее 2 число вычислителей не получится.
QUADRONN_10.SET (вычисление первых 10 чисел “квадроначчи” – аналогично “трибоначчи”, однако линейная рекуррентная последовательность в этом случае включает уже 4 ста́ртовых числа) даст иной результат – при любом числе вычислителей P>3 увидим, что распараллелить на бо́льшее 3 число вычислителей не получится.
“Однако – тенденция!..” – сказал бы просветлённый чукча. Естественно, при всех случаях, зада́в число параллельных вычислителей единичным, получим полностью последовательный вариант выполнения.
Само собой, конвертировав указанные программы в DOT-формат и исследовав их в системе ПРАКТИКУМ SPF (публикация #013), получим те же результаты.
Для удобства пользователей системы ПРАКТИКУМ DF возможен режим запуска с командной строкой; причём в командной строке обязательны 4 параметра:
имя_Set-файла˅число_ АИУ˅how_Calc_Param˅how_Calc_Prior
где ˅ - один или любое число пробелов.
Например, строкой dаtа_flоw.ехе˅slau_2.set˅15˅0˅1 запускается программа-симулятор потокового вычислителя с файлом-программой SLAY_2.SET с числом АИУ 15 и значениями параметров how_Calc_Param и how_Calc_Prior соответственно 0 и 1.
Самостоятельным исследователям автор рекомендует поэкспериментировать с управлением динамикой вычислений. В самом деле, при накоплении в буфере готовых к выполнению команд числом бо́льшим количества свободных в данный момент параллельных вычислителей возникает вопрос – какие команды “запускать” на поле параллельных вычислителей, а какие “попридержать”. Автор в своё время активно интересовался этим вопросом, но через определённое время интерес погас.
Напомню - при выборке инструкций из буфера для исполнения на АИУ всегда первыми выбираются инструкции с максимальным по буферу приоритетом (а он зависит от определенных параметров инструкции… а каких – тому следуют пункты). В файле настроек DATA_FLOW.INI стратегию порядка выборки (дисциплины обслуживания) определяют две величины - how_Calc_Param и how_Calc_Prior:
how_Calc_Param (рассчитывается как сумма параметров всех тестируемых инструкций – т.е. инструкций, зависящих по входным операндам от результата выполнения данной инструкции):
- при how_Calc_Param=0 все значения параметров инструкций одинаковы (фактически инструкции будут переданы ИУ в порядке “первым вошёл – первым вышел”),
- при how_Calc_Param=1 для значения параметра используется датчик случайных чисел,
- при how_Calc_Param=2 – время выполнения тестируемой (кроме SET…) инструкции,
- при how_Calc_Param=3 – число тестируемых (кроме SET…) инструкций, для которых результат выполнения данной является хотя бы одним из входных операндов,
- при how_Calc_Param=4 – число входных операндов, тестируемых (кроме SET…) инструкций, совпадающих по адресам с адресом результата выполнения данной,
- при how_Calc_Param=5 – если у тестируемой (кроме SET и данной) инструкции имеется N входных операндов, из которых M к данному моменту уже готовы и результат выполнения данной инструкции совпадает по адресу с К из (N-M) неготовых входных операндов, то параметр полезности тестируемой инструкции равен K/(N-M); при K=(N-M) получаем максимальный единичный вес тестируемой инструкции,
- остальные равносильны how_Calc_Param=0 (умолчание).
how_Calc_Prior (служит для управления выборкой по минимальному или максимальному значению определяемого how_Calc_Param параметра: при how_Calc_Prior=0 значение приоритета равно значению параметра, при остальных – обратной величине этого параметра).
Управление динамикой процесса вычислений в потоковом вычислителе
Проанализировав успехи в успешном преобразовании кода посредством системы управления вычислениями на граф-машине, появляется намерение дальнейших исследований этого потенциала. Потенциал это заключается в возможности управления последовательностью ГКВ-операторов, поступающих на поле параллельных вычислителей (АИУ).
Зависимость числа выполненных операций (нако́пленная кривая интенсивности вычислений - ИВ) для конкретного алгоритма от времени выполнения программы и размера обрабатываемых данных представлена рис. ниже (в эстетических целях кривые показаны сгла́женными). В общем случае зависимость текущего числа N исполненных операций алгоритма зависит как от времени tвыполнения программы, так и от размера n обрабатываемых данных. Заметим, что обычно рассматривается только функция вычислительной трудоёмкости N(n), представляющая собой срез графика рисунка в момент окончания вычислений t=t0 ; таким образом форма кривой ИВ признаётся несущественной. При описании работы потокового вычислителя естественно расширение понятия функции вычислительной трудоёмкости в части её изменения по времени выполнения программы.
В самом деле, если в данный момент число ГКВ-операторов не превышает число свободных АИУ, проблемы не возникает. А при обратной ситуации определение подмножества всех ГКВ-операторов для выполнения может представлять интерес для указанного направления исследований, проблема заключается в выборе принципов определения этого подмножества.
Исследователь может провести эксперименты с системой DF, моделируя различные правила выборки ГКВ-операторов из буфера операторов (см. схему на рис. ниже). В исследовательском инструменте DF правилами выборки операторов управляют две переменные how_Calc_Prior и how_Calc_Param секции [Strategy] файла настроек системы.
Важно, что правила выборки операторов применяются к операторам, являющимся информационно зависимыми по данным от каждого конкретного исследуемого (“потомства данного”, см. рис. ниже). Фактически исследуется влияние параметров “доче́рней” популяции относительно родительской.
Управляющая переменная how_Calc_Prior служит для управления выборкой операторов по минимальному или максимальному значению определяемого how_Calc_Param параметра: при how_Calc_Prior=0 значение приоритета равно значению параметра, при остальных – обратной величине параметра).
Поимев (некоторые) возможности управления правилами выполнения операторов, самое время подумать, каким образом этими возможностями разумно воспользоваться. Задача оказалась непростой и потребовала проведения множества экспериментов (например, потерпела крах “лежащая на поверхности” идея о выборе наибольшего приоритета в выполнении операторов с минимальным временем выполнения).
Реальный эффект (в качестве отклика рассматривалось общее время выполнения программы) дала стратегия использования приоритета наискорейшего выполнения операторов, имеющих максимум дочерних (по информационным связам) операторов. Такой подход требует просмотра операторов на одну информационную связь вперёд.
Данные эксперимента иллюстрируются рис. ниже, где представлен результат моделирования управления процессом выполнения программы решения СЛАУ 5-го порядка классическим (неитерационным, двустадийным) методом Гаусса (для этого случая P0=24). Как видно, максимальное ускорение вычислений составляет около 6, а диапазон варьирования (увеличение и уменьшение скорости выполнения программы) составляет 4,5% (двойной размах). Анализ процедур решения СЛАУ различного порядка показывает увеличение управляемости с ростом размера обрабатываемых данных.
Зависимости 2 и 3 на этом рисунке соответственно иллюстрируют применению одной из стратегий управления ИВ c целью интенсификации процесса вычислений и его депрессии (по сравнению с равноприоритетной выборкой ГКВ-инструкций из буфера – график 1). Интенсификация и депрессия в процессе вычислений, естественно, могут целенаправленно перемежа́ться. При значительном количестве операций в алгоритме эффективность управления возрастает.
Представляет интерес вопрос – для какого типа алгоритмов подобный метод управления является эффективным, а для какого таким не является? С целью выяснения ответа на этот вопрос была осуществлена серия вычислительных экспериментов по управлению динамикой вычислений для нескольких типов программ (публикация здесь). С целью исключения влияния различного времени выполнения отдельных арифметических инструкций это время принималось одинаковым. Возможность целенаправленного управления динамикой процесса вычислений в потоковом вычислителей может быть полезна в случае совместного выполнения нескольких задач (особенно в режимах, допускающих одновременное использование различными заданиями разных АИУ из их общего поля).
Авторские ресурсы:
- Мой Мир: https://my.mail.ru/mail/e881e/
Информация о канале вообще и его оглавление…
- Внимание! Со следующих выпусков название несколько изменится – теперь будет “Анализ и целенаправленные эквивалентные преобразования алгоритмов”. Ключевые слова здесь – “целенаправленные эквивалентные преобразования” отражают новые задачи, поставленные Автором (алгоритмы можно не только анализировать, но и целенаправленно преобразовывать – сохраняя, естественно, неизменным граф алгоритма (это же формализованная форма описания программы, а её – программу – мы не вправе изменять).
в принципе можно проводить эксперименты с любым число независимых параметров