Целенаправленные преобразования ЯПФ при возможности увеличения её высоты
Ярусно-Параллельная Форма (ЯПФ) графа, показанная на рис. 9, почти идеально подходит в качестве основы для целенаправленных преобразована с целью создания планов параллельного выполнения алгоритмов (программ) для процессоров со сверхдлинным машинным словом (архитектура VLIW - Very Long Instruction Word). В рамках обеспечения импортонезависимости России разрабатываются микропроцессоры ЭЛЬБРУС c VLIW-архитектурой области применения которых - государственные и оборонные структуры, высокопроизводительные вычислительные системы (суперкомпьютеры).
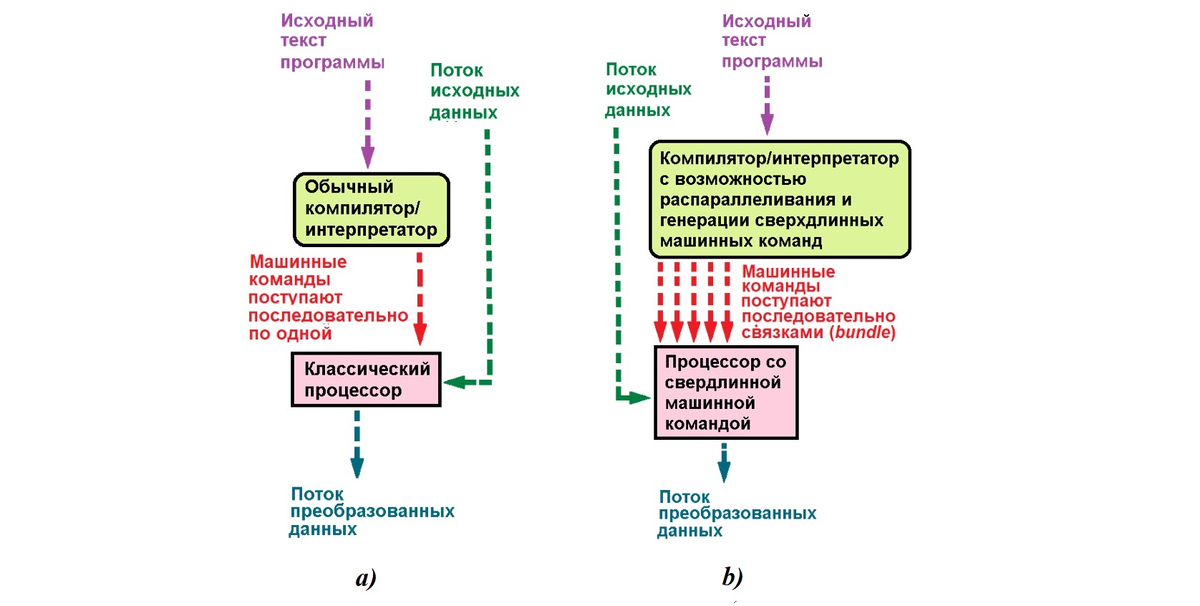
Процессоры архитектуры сверхдлинного машинного слова (рис. 27 b) относятся к специфическим классам архитектур, прямо нацеленным на использование внутреннего параллелизма в алгоритмах (программах), причём параллелизм этот анализируется и планируется к рациональному использованию при вычислениях на программном уровне; собственно аппаратная часть освобождается от процедур распараллеливания (и поэтому должна стать проще и экономичнее использующих внутреннее распараллеливание – как на рис. 27 a). Такой подход носит название EPIC (Explicitly Parallel Instruction Computing, явный параллелизм уровня машинных команд).
VLIW-парадигма основана на идее загрузки во входной буфер процессора одновременно набора (bundle) допускающих параллельное выполнение машинных команд и исполнения этого ряда команд аналогично единой команде в процессорах классической архитектуры. VLIW-процессоры реализуют параллелизм уровня ILP (Instruction-Level Parallelism, параллелизм уровня машинных инструкций) и SMP (Symmetric MultiProcessing, системы с общей памятью) идеологему работы с оперативной памятью.
Кстати, вопрос к Читателю – подумайте, чем отличается VLIW-архитектура от классической многоядерной (при одинаковом количестве вычислительных ядер) ?..
Персоналии
- Джозеф А. «Джош» Фишер (родился 22.06.1946) – американо-испанский учёный в области компьютеров, известный своей работой над архитектурами VLIW (Йельский университет, начало 80-х), идеями компиляции и параллелизма уровне команд (ILP), а также созданием Multiflow Computer (1984). Он является старшим научным сотрудником Hewlett-Packard (почётным). Первый компилятор VLIW был описан в докторской диссертации Джона Эллиса под руководством Фишера. Компилятор был назван Bulldog в честь талисмана Йельского университета.
- Михаи́л Алекса́ндрович Ка́рцев (10.05.1923÷23.04.1983). Главный конструктор первых поколений ЭВМ для систем контроля космического пространства и предупреждения о ракетном нападении СССР. Теоретические аспекты VLIW, были разработаны М.Карцевым на основе его работы шестидесятых годов над военными компьютерами М-9 и М-10. Его идеи были позже развиты и опубликованы как часть учебника за два года до основополагающей статьи Фишера, но из-за “железного занавеса” оставалась в значительной степени неизвестной на Западе. Место работы – НИИВК. Автор горд, что во время работы в НИУ ВШЭ ему пришлось сотрудничать с одним друзей М.Карцева – одним из рабработчиков операционной системы для изделия М-10 - Гринкругом Е.М.
- Бори́с Арташе́сович Бабая́н (20.12.1933). Участвовал в разработке, создании и внедрении нескольких поколений советских вычислительных машин: М-40, 5Э92б, Эльбрус-2 и Эльбрус-3, руководил разработкой архитектуры и логическим проектированием. Группа под руководством Б.Бабаяна разработала компьютер ЭЛЬБРУС-3 с использованием идеологемы EPIC. Бабаян стал первым европейским учёным, удостоенным титула Intel Fellow (заслуженный инженер-исследователь Intel).
Несмотря на выпуклое преимущество (программным путём дешевле реализовать сложные процедуры параллелизации), работа VLIW-процессоров сопряжена с известными проблемами. Среди них выделяют:
- статичность полученных планов параллельного выполнения (напр., на программном уровне нереально учесть все возникающие проблемы с оптимальным расположением исполняемого кода и обрабатываемых данных в многоу́ровневой оперативной памяти) с точки зрения автора недостатком не является, ибо преимущества в качестве распараллеливания с лихвой компенсируют некоторые уж совсем экзотические варианты использования,
- проблемы с излишней неравномерностью времени до́ступа к оперативной памяти разных вычислительных ядер (временна́я антиплотность кода, следствием является резкое снижение производительности из-за неизбежности определения время выполнения всей связки команд сверхдлинного слова по продолжительности наиболее длительной из них), для компенсации этого предусматривается использование процессора в режиме DSP (Digital Signal Processor) при расположении обрабатываемых данных в одноуровневой оперативной памяти.
Автору публикаций (не “по наслы́шке” знакомому с практическими сложностями распараллеливания алгоритмов), EPIC/VLIW-направление представляется очень завлекательным в смысле проверки возможностей алгоритмико-ориентированного подхода. Идея максимального освобожде́ния аппаратуры процессора от задач распараллеливания выглядит как минимум логичной – распараллеливание суть проблема алгоритмов, а не аппаратуры! Проблемы распараллеливания алгоритмов логично решать именно программным путём (вследствие их сложности и масштабности), а аппаратуре собственно процессора делегировать выполнение простейших действий (аналогично RISC-подходу)… у него (процессора) и своих проблем предостаточно (вспомним “закон 4-й степени лорда Рэлея” – см. публикацию #002)! Это выгодно и экономически – затраты на “железо” обычно намного превышают стоимость программной части. А за повышение производительности процессора хотя бы на несколько процентов при использовании в критических областях применения эксплуатационники бьются на́смерть..!
Борис Бабаян о процессорах серии ЭЛЬБРУС
В деле создания процессоров серии ЭЛЬБРУС значительную роль сыграл Борис Бабая́н (интереснейшие воспоминания о работе над созданием этой процессорной архитектуры см. здесь и тут; шутливое упоминание о протагони́сте – здесь).
- Кстати, в публикации “Железо на службе у алгоритма” есть его интереснейшие соображения о роли и важности АЛГОРИТМОВ: / “Вот смотрите: вычислительная техника – это что такое? Это реализация алгоритмов в железе с помощью языков программирования. То есть, имеем три важнейших компоненты: алгоритмы, языки и железо. Поэтому если мы собираемся что-то анализировать, то прежде всего необходимо посмотреть именно на эти компоненты. / Начнем с алгоритмов. Алгоритмы – это нечто абстрактное, нечто вечное. Как числа, например. Может существовать множество разных алгоритмов, и каждый из них вечен. / Каким образом представляются алгоритмы? В них, как и во многих других вещах, связанных с реальным миром, можно выделить две компоненты: временнУю и пространственную. ВременнАя компонента – это последовательность выполнения операций: что за чем выполняется. Эта компонента – предельно параллельная. Конечно, существуют чисто последовательные алгоритмы, но в принципе понятие алгоритма – это представление о параллельной структуре. Обычно граф вычислений очень параллелен и предельно структурирован. / Теперь пространственная компонента. Пространственная компонента тоже параллельна и структурирована. Что она из себя представляет? Это объекты, с которыми работают операции. Масса объектов. Эти объекты могут ссылаться друг на друга, быть вложенными друг в друга. Но их много и с ними работают разные операции. Очень всё параллельно. / Вот что такое алгоритмы.”
Первыми истинными VLIW-компьютерами стали мини-суперкомпьютеры, выпущенные в начале 1980 г. компаниями MultiFlow, Culler и Cydrome (США). К первым VLIW-процессорам относят TriMedia (Нидерланды) и DSP C6000 (США), такую архитектуру имеют многоядерные процессоры фирмы Tilera Corp. Известны VLIW-процессоры Сrusoe, Efficeon (США), Itanium (США), Эльбрус (Россия). В настоящее время VLIW-подход широко применяется в рыночном сегменте устройств класса DSP (Digital Signal Processor) для смартфонов, систем управления автомобилями, носи́мых устройствах иных мобильных систем и в компонентах сетей сотовой связи (напр., процессоры Snapgragon Hexagon QDSP6 компании Qualcomm, Inc.).
Архитектура VLIW (зачасту́ю позиционируется как “анти-х86”) буквально с момента создания вызывает активные дискуссии по вопросу её эффективности. Эти дискуссии активизировались после (до конца не полностью прозрачной) истории с признанной неудачей разработкой Intel Corp. процессора ITANIUM (архитектура и набор команд IA-64, производство прекращено в 2017, поста́вки - в 2021); автор неоднократно встречался с “брызжущими ядовитой слюной” сужде́ниями о VLIW. Известно о наличии (проприентарной) версии программного симулятора Ski для архитектуры IA-64. Жаль – у автора нет доверительной информации о параметрах функционирования этого процессора (особый интерес представляли бы данные о дости́гнутой плотности кода), поэтому автор считает полезным (именно по причине дискуссионности проблемы) предста́вить собственные расчёты для VLIW-процессоров.
Для информирования Читателей добавлены ссылки на статьи создателя канала https://dzen.ru/electromozg. Т.к. блогер Электромозг часто пишет о проблемах процессоров ЭЛЬБРУС, в дополне́ние подбо́рка публикаций на эту тему.
Проблема эффективности применения процессоров VLW-архитектуры фактически упирается в разреше́ние следующих вопросов:
① сама идея программного распараллеливания на уровне ILP (уровень машинных инструкций) неработоспособна в принципе... или же ...
② пока не удалось достичь необходимых высоких требований к культуре разработки и сложности создания распараллеливающих компиляторов ?
Мнение автора – верно ВТОРОЕ! Так что данная работа – одна из попыток ответить на поста́вленный (кардинальный) вопрос.
Т.к. аппаратно во VLIW-архитектуре уже заложена линейка отдельных вычислительных ядер соответственно каждому слоту сверхдлинного слова, важным требованием является задача максимальной загрузки вычислительной аппаратуры (этих ядер). При этом совершенно естественным является метод представления каждого слота сверхдлинного командного слова соответствующим сечением ИГА с выполнением последовательно по ярусам с начала до конца программы.
Предложено большое количество подходов к проблеме построения рациональных планов (расписаний) параллельного выполнения алгоритмов (и созданных на их основе программ); часть из них являются теоретическими и вряд ли когда-либо будут реализованы. Методологически автор данного исследования считает важным выбор соотношения между достаточно быстрой вычислительной процедурой (трудоёмкостью O(N^2), где N - число вершин в ИГА) специального деле́ния графа и ювелирно выполняющейся основанной на использовании Lua-эвристик частью общей задачи. С точки зрения автора, при таком разделении труда (суперпозиция формальной и эвристической компонент) достигается бо́льшая эффективность по сравнению с приёмом, когда выборка каждого оператора начинается с “чистого листа”.
Согласен ли Читатель с (вышесказанным) утверждением автора?
Кстати, в данном случае выявляется один из недостатков алгоритмико-ориентированного подхода – отсутствие учёта временны́х параметров выполнения программ. Вследствие этого из-за труднооцениваемых задержек при выполнении машинных команд (по операциям чтения/записи в многоуровневую оперативную память) решение всегда будет нижней границей общего времени выполнения программы. Это ясно – даже при синхронизации старта всех операций сверхдлинного слова по моменту времени начала определённого яруса ЯПФ общее время выполнения операций определяется наиболее длительной операцией (загрузка следующего слота сверхдлинного слова может начаться только после полного выполнения текущего; некоторые анало́гии см. на рис. 10б публикации #009 и выражения [7] в публикации #019). Механизм учёта времени выполнения вершин (операторов) и дуг (информационных связей) в ИГА в данном случае не был задействован.
Почему методика получения и целенаправленной модификации ЯПФ хорошо подходят для формирования планов (расписаний) выполнения программ на VLIW-процессорах
Автор в предыдущей публикации #015 с упое́нием повествовал́ о недостатках применения ЯПФ-методики при расчётах произвольных (без учёта архитектурных особенностей) параллельных вычислительных систем… и тут же он утверждает об эффективности её (этой методики) применения в случае VLIW-архитектуры. Почему так?
Всё просто – метод ЯПФ максимально эффективен лишь в случае соблюдения условий синхронизации выполнения групп (обладающих ГКВ-свойством, см., напр., публикацию #013) операторов (из любого количества машинных команд) – лучше по началу их выполнения. Сколько времени продо́лжится выполнение оператора – неважно (всё равно следующая группа операторов не может начаться раньше окончания самого длительного оператора предыдущей группы). Так что идея сопоставления каждой группы операторов с очередным ярусом ЯПФ вполне логична.
Какие вычислительные архитектуры используют мелкозерни́стый (fine-grained, ILP) принцип распараллеливания? Intel'вский x86 распараллеливает на конвейере (уровень параллелизации меньше размера машинной команды)… пото́ковая (Data-Flow) архитектура до сих пор полностью не реализована (в основном из-за отсутствия ассоциативной памяти необходимого размера – см. публикацию #008).
Между тем использование ILP-идеологами (распараллеливание уровня машинных инструкций) изначально заложена в принципе формирования составляющих библиотеки алгоритмов (публикация #010). Так что для случая вычислительных систем VLIW-архитектуры можно ожидать наилучшего совпадения теоретических оценок с эмпирикой..!
Пространственная плотность кода для VLIW-процессоров
Т.к. одним из проблематичных вопросов эксплуатации VLIW-процессоров считалась недостаточная плотность кода, специально предпринято было исследование этой проблемы. Усреднённая степень использования параллельных вычислительных ресурсов оценивалась пространственной плотностью кода (рис. 28).
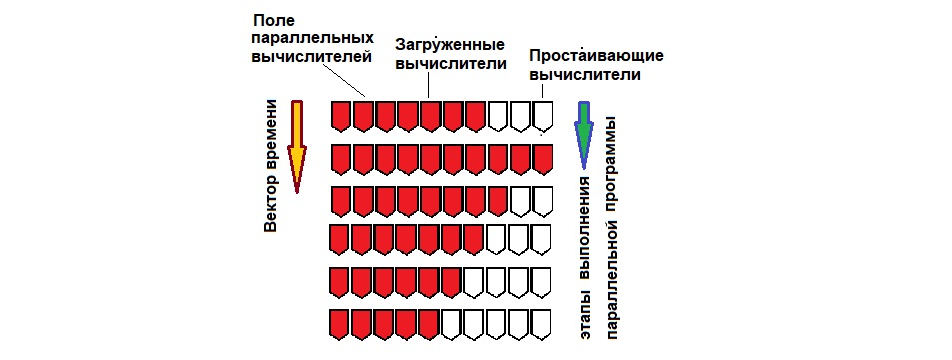
Для практического применения характеристику плотность кода (один из близких аналогов - коэффициент полезного действия) удобно оценивать коэффициентом использования параллельных вычислителей (считая общее число таких вычислителей равным ширине ЯПФ). При этом величина суперскалярности (число одновременно обрабатываемых машинных команд) точно равна размеру слота (числу машинных команд в сверхдлинном слове); незагру́женные полезными действиями вычислители обычно выполняют “команду-пустышку” NOP (нет операции):
где Wi – ширина i-того яруса ЯПФ (здесь ∑Wi=M - число операций в рассматриваемом алгоритме, W=max(Wi), H – число ярусов ЯПФ). При полной загрузке всех вычислителей в течение всего времени выполнения алгоритма (программы) имеем kи≡1 (напр., вариант полностью последовательного выполнения); неслучайному достижению kи≡1 в случае параллельного выполнения активно препятствуют информационные (причинно-следственные) связи типа “операторы → операнды”. Здесь плотность кода вычисляется упрощённо – как среднее по операциям; более точным был бы этот показатель по отношению к процессорным тактам, но анализ информационной структуры алгоритмов не подразумевает учёт количества тактов на операцию.
Заметим, что (в соответствие с основной концепцией АЛГОРИТМА как сущности, учитывающей только события изменения данных и информационные связи между последними) при таком исчислении плотности кода учитываются только машинные команды, изменяющие данные, и не учитываются вспомогательные (напр., реализующие манипуляции с памятью).
А интересно – когда плотность кода (в рамках ЯПФ-модели планирования, естественно) достигает (формально) максимума? Временна́я плотность кода максимальна, если длительность (включая сопутствующие операции по извлечению/сохранению операндов из/в память) выполнения всех операторов каждого яруса ЯПФ одинакова, а пространственная достигается, если на всех ярусах ЯПФ имеем kи=1.
Основными характеристиками эффективности полученных планов считались следующие:
- пространственная плотность кода - уровень загрузки вычислительных ядер VLIW-процессора (аналогично коэффициенту полезного действия в термомеханических системах) - коэффициент использования параллельных вычислителей kи,
- вычислительная сложность целенаправленного преобразования ЯПФ – число элементарных шагов преобразования (в качестве меры выбрано число перемещений операторов с яруса на ярус ЯПФ).
Дополнительно анализировалась полученная в результате преобразования высота ЯПФ (параллельная вычислительная сложность) – оценка времени выполнения алгоритма (программы).
Как сказано, неявно ставилась задача определения максимальных степеней распараллеливания, реализуемых для VLIW-процессоров. Результаты вычислительных экспериментов по целенаправленному преобразованию ЯПФ представлены на риc. 29÷31.
Преобразования заключались в модификации ширины ЯПФ каждого алгоритма с использованием методов (эвристик) WithByWith и Dithotomy до шири́н ЯПФ, соответствующим текущим значениям абсцисс графиков. Т.о. наиболее “правая” абсцисса соответствует ширине исходной (“сырой”, соответствующей условиям неограниченного параллелизма) ЯПФ (в “верхнем” варианте), а крайняя левая – последовательному выполнения алгоритма (единичная ширина ЯПФ; обратите внимание на экспоненциальный характер оси абсцисс). В такой системе координат значение каждой ординаты графика отвечает целевому значению величины, соответствующей конкретной ширине ЯПФ.
Т.о. под планами параллельного выполнения имеется в виду получение для конкретного алгоритма последовательности заполнения слотов сверхдлинного слова (для каждого задаётся список конкретных машинных команд, количеством не превышающим заданный размер слота); дополнительные уточнения возможны, но не имеется необходимой исходной информации.
В ходе исследований были использованы две эвристики преобразования ЯПФ (WithByWith и Dichotomy), обладающие одна повышенным качеством получаемых планов при повышенной же вычислительной трудоёмкости реализации, другая – наоборот (потенциальные кандидаты на разную степень оптимизации). В целом показано, что для VLIW-процессоров с размером слота сверхдлинного слова в 4÷16 команд плотность кода изменяется в достаточно широком диапазоне (может доходить до 0,6÷1,0 с продолжающимся падением при дальнейшим росте слота) и повышается с увеличением размеров обрабатываемых данных (исследовались алгоритмы линейной алгебры с порядком матриц 10 и один искусственно сгенерированный алгоритм).
При этом в случае применения эвристики Dichotomy высота ЯПФ (параллельная вычислительная сложность) всё же больше, чем в случае применения WithByWith (автор исследования считает кривую 3 на рис. 29÷30 наиболее близкой к идеалу максимума плотности кода вследствие наивысшей близости ея́ к режиму асинхронности выполнения операторов).
Причудливая форма кривых в начальной части рис. 29 c) является следствием противоречивых дискретных процессов, происходящих при целенаправленном изменения ЯПФ; автор не счёл необходимым сглаживать кривые и приводит данные “как есть”.
● Приведённые на рис. 29÷31 графики чрезвычайно информати́вны. Видно, что максимальная плотность кода достигается при размере слота сверхдлинного слова в 4÷16 команд, однако при этом высота ЯПФ (а она, как известно, определяет длительность выполнения программы) сильно возрастает (относительно исходного – который соответствующего абсолютному минимуму времени выполнения); вычислительная сложность целенаправленных преобразований ЯПФ при этом имеет уже второстепенное значение.
● Нам придётся решать типичную оптимизационную задачу с взаимно противоречащими друг другу критериями – при малых длинах слота сверхдлинного слова плотность кода максимальна (что благоприятствует быстродействию), но резко возрастает время выполнения программы вследствие роста высоты ЯПФ. Это материал для выбора создателей реального оборудования – какое количество отдельных машинных инструкций является рациональным для VLIW-процессора? Как привычно в Жизни – выбирать приходится не из наилучших, а из нескольких вариантов не самого плохого (принципы “максими́на/минима́кса”).
В целом (на приведённых данных) подтверждается проблемность получения плотности кода величиной выше порядка 0,8 при размере слота сверхдлинного машинного слова 4÷16. “Светом в конце тоннеля” может являться:
- факт улучшения качества получаемых планов параллельного выполнения программ с возрастанием размеров обрабатываемых данных (с ростом порядка матриц резко возрастает число степеней свободы в расположении операторов по ярусам ЯПФ – это подтверждается расчётами),
- улучшение качества эвристик (автор ни в коей степени не считает, что достигнут оптимум при движении в этом направлении).
А как Читатель объяснит снижение плотности кода при возрастании размера слота сверхдлинного машинного слова? А как Читатель думает – плотность кода при увеличении разме́рности обрабатываемых данных (порядка матриц) будет увеличиваться или снижаться (естественно, при неизме́нном размере слота)? Вы имеете возможность самостоятельно провести компьютерную симуляцию с помощью системы ПРАКТИКУМ SPF (см. публикацию #013), получив подобные приведённым на рис. 29÷31 результаты, но при ме́ньшей разме́рности обрабатываемых данных..!
- Рассматривая предмет исследований формально, можно сказать, что EPIC-подход дал возможность анализировать параллелизм на значительно бо́льшей длине исходно-последовательного кода. В самом деле, конвейерная архитектура x86 позволяет находить параллелизм на количестве машинных команд в несколько их штук (столько, сколько обрабатывается одновременно на конвейере), EPIC же не ограничивает это число. Размышляя логически, однако, практически эту длину для EPIC-подхода следует ограничить (напр., размером библиотечных процедур); логично считать, что на какой-то длине происходит усреднение параметров параллелизма.
Усилия России в области импортонезависимости путём производства прямо ориентированных на параллелизацию обработки данных процессоров ЭЛЬБРУС (архитектура со сверхдлинным машинным словом, EPIC-подход к выявлению и реализации параллелизма в алгоритмах) потребуют (уже сегодня и в ближайшем будущем) серьёзных усилий по разработке эффективных распараллеливающих трансляторов для этих процессоров. Связанные с недостаточной эффективностью использования вычислительных ресурсов (а согласно используемой идеологии EPIC в данном случае это область инструментального программного обеспечения) проблемы процессора ITANIUM (Intel Corp.) постепенно привели к осмыслению того (вообще-то давно известного подлинным специалистам) факта, что использование вычислителей со сверхдлинным машинным словом в качестве процессоров общего назначения не смогли преодолеть свой главный недостаток – весьма высокие требования к культуре разработки и сложность создания распараллеливающих компиляторов для них.
- Долгое время казалось (и зарубежным разработчикам тоже), что “всё и так сойдёт” в деле построения инструментального ПО до́лжного качества, однако внезапно выяснилось, что требуются серьёзные дополнительные усилия в этом направлении. Работа автора является поисковой для этой линии исследований и главным образом призвана выявить недостатки положения дел в этом вопросе. Так что перспективы для работ в данном направлении, безусловно, имеются.
Дальнейшие пути повышения плотности кода для VLIW-процессоров
Ранее (см. публикацию #011) был рассмотрен случай ограниченного потенциала параллелизма (чисто последовательное – или при минимальном параллелизме - выполнение машинных команд).
В качестве примера на расположенной сверху миниатюре приведена характерная "стулообра́зная" форма кривой интенсивности вычислений – a) и приведены максимальные значения ординат этой кривой – б) для случаев перемножение векторов, матрицы на вектор и двух матриц соответственно (в функции параметра порядка n).
Сказанное относится к случаям превышения потенциалом параллелизма (максимальное число параллельно исполняющихся машинных инструкций) количества слотов сверхдлинного слова. “Слабым местом” процессоров с длинным командным словом являются т.н. “инженерные алгоритмы”, характеризующиеся наличием длинных цепочек формул, зависящих от одного или ограниченного количества результатов предыдущих вычислений; такие алгоритмы характеризуются последовательным (или почти последовательным) характером выполнения; в этом случае плотность кода априори будет низка́. Для таких случаев возможно применение геометрической многозадачности (наряду с многозадачностью вытесняющей) – разделение части слотов между различными заданиями (статическое или динамическое).
Такое решение встречает затруднения при реализации (заключающееся, напр., в преодолении “барьера а́дресного пространства” для одновременно работающих приложений и др.) и требует серьёзного усложнения диспетчера задач операционной системы в деле предсказания потенциала параллелизма каждого рассматриваемого алгоритма; благодаря редкости встреча́емости таких случаев встаёт вопрос опра́вданности подобного решения.
Теоретически указанные режимы многозадачности представлены на миниатюре выше: однозадачный режим – a), многозадачный со статическим распределение слотов – б) и многозадачный с динамическим распределением слотов сверхдлинного слова – b) соответственно.
Практическое использование целенаправленных эквивалентных преобразований алгоритмов
Естественно, наилучший результат применения методов (какими они бы не были) целенаправленной модификации алгоритмов удастся получить от глобального (сразу ко всей программе) их применения. А как быть при возникших проблемах (напр., нехватке ресурсов – памяти или вычислительных)?
Выход один – последовательное применение выбранной стратегии (стратегий) преобразования!.. На нижерасположенной миниатюре приведена общая схема действий при такой ситуации (естественно, вместо “Алгоритм А” и др. имеем в виду соответствующие библиотечные процедуры).
Какие преимущества и недостатки имеются у такого применении преобразований? Априори неясно, уровень (качество) распараллеливания ухудшится или наоборот (по сравнению с глобальным применением того же метода).
Преимущества – для каждого алгоритма можно (и до́лжно!) использовать наиэффективнейший метод преобразований ("эвристика"). Недостаток – т.к. метод получения ЯПФ параметризован по данным (зависит от их размеров даже при неизменном алгоритме – показано указателями “Данные А→Б” и др.), дополнительно может потребоваться решение задачи выбора метода преобразования с учётом параметризации (оптимальным может оказаться иным).
Дополнительно анализ полного информационного графа алгоритма (и его ЯПФ) может быть затруднён из-за их размера. В самом деле – для алгоритма умножения матриц традиционным способом уже при порядке матриц n=1’000 (а это далеко не максимум для подобных задач) на первом ярусе ЯПФ окажется n^3=10^9 готовых к выполнению операций умножения, при этом могут возникнуть проблемы с самим сохранением графа.