Вышеописанный ПРАКТИКУМ DF на самом деле является частью более обширного ПРАКТИКУМА DF-SPF (см. рис. 12). Исследовательский инструмент SPF мы начнём использовать чуть позднее, а пока сосредоточимся на возможности DF.
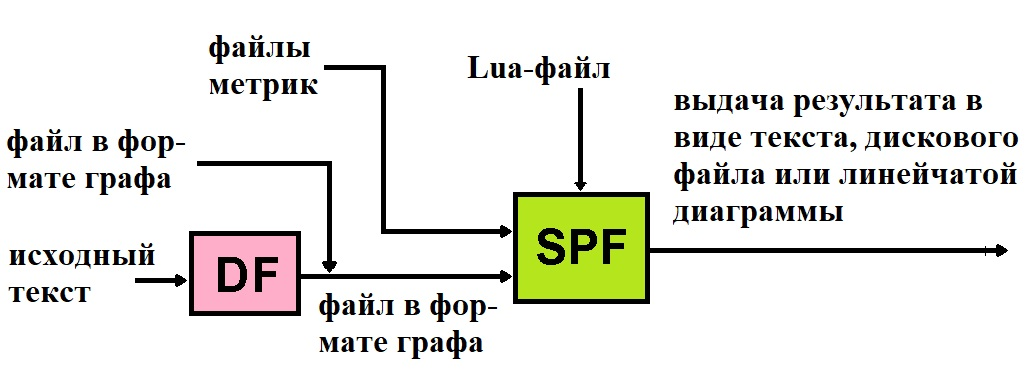
Исследования свойств алгоритмов с помощью инструмента DF
Нас интересуют, конечно, свойства алгоритмов в направлении исследования свойств параллелизма. Начинаем с классического – того самого примера решения полного квадратного уравнения. Загружаем в систему DF (по клавишам Ctrl+O) файл SQUA_EQU_2.SET, убеждаемся в загрузке программы в находящийся в центральной части фрейм (подокно) и нажимаем кнопку “Выполнение”. Любуемся переливами цветов и перемещениями строк (на самом деле они показывают последовательность выполнения отдельных строк – операторов исходной программы), проходит время и правом фрейме главного окна с надписью “Данные” получаем два столбца – первый с именем переменной, второй – с её значением.
В верхнем фрейме ведётся подробнейший протокол выполненных действий (т.к. система имеет исследовательское назначение, всегда может понадобиться тщательный анализ списка выполненных действий). Тут же появляется (дочернее) окно с графиком (диаграммой) интенсивности вычислений (число задействованных параллельных вычислителей в зависимости от времени); их число ограничено, конечно, заданным в поле ввода значением “Число АИУ” (если помните, это аббревиатура от словосочетания “Арифметические Исполнительные Устройства”).
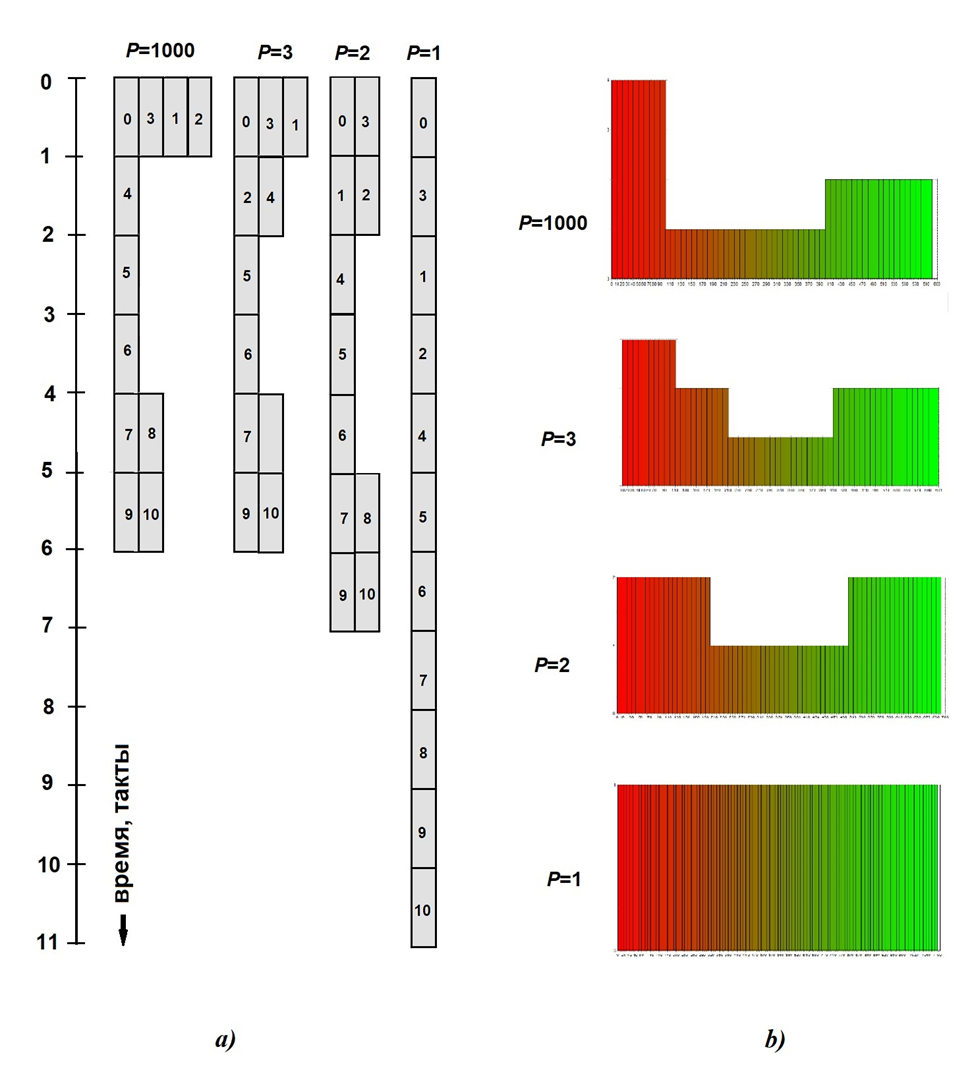
Начнём с анализа того, каким образом DF-симулятор реализует параллельное выполнение реальной программы (всё той же SQU_EQU_2.SET). Фактически мы на основании этих данных можем выстроить план (расписание) выполнения параллельной программы. Ось времени направлена сверху вниз на рис. 13 a) и слева направо на диаграммах интенсивности вычислений (рис. 13 b), длительности выполнения операторов выделены серыми прямоугольниками (в их центре – номера операторов начиная с 0).
В подрисуночной надписи встречается слово “неограниченный параллелизм” – это простое понятие, означающее работу вычислительной системе в условиях неограниченных ресурсов (в данном случае – сколь угодно большого числа отдельных параллельных вычислителей P, при невозможности задания бесконечно большого числа обычно задают большое конечное – напр., P=10’000). Информация о функционировании вычислительной системы в режиме неограниченного параллелизма много даёт много информации о её параметрах. В правой части рис. 13 приведены диаграммы интенсивности вычислений в условиях “ограниченного параллелизма” (P=3, 2 и 1 – напомним, что P=1 соответствует последовательному выполнению операторов). На рис. 13 длительность выполнения всех операторов одинакова (только при этом можно считать, что операция построения ЯПФ полностью соответствует схеме рис. 9).
На рис. 14 время выполнения операторов сильно различается (при длительности операций сложения и вычитания операции умножения и деления удлинены в 4,15 раза, а вычисления квадратного корня – в 8,35 раз).
Из рис. 13 видно, что при равных длительностях всех операций между ними нигде нет “холостых” промежутков, на рис. 14 лакуны уже имеются. Это интересное явление (после окончания выполнения оператора на данном вычислителе не нашлось никакого иного с характеристикой “готовности к вычислению”), говорящее о невозможности добиться 100% временно́й плотности кода (если каждый момент времени каждого параллельного вычислителя загружен выполнением операторов, то можно говорить о 100% плотности кода по времени).
Автор свою точку зрения высказал. А как считает Читатель – возможно ли (в принципе) добиться 100%-ной временно́й плотности кода при заданном в публикации #008 принципе действия Data-Flow - машины?
Немного интересного о характере диаграмм интенсивности вычислений
На рис. 15 изображена диаграмма интенсивности вычислений, полученная при выполнении программы SLAU_7.SET (решение системы линейных алгебраических уравнения методом методом исключения переменных) в режиме неограниченного параллелизма.
Как видно, функция интенсивности вычислений обладает крайне неравномерным (“шква́листым”) характером, отражающим внутренние свойства алгоритма (при ситуации многократной зависимости иных операторов от результатов выполнения данного периодически возникают “взрывы” по терминологии Всеволода Бурцева; сглаживание “взрывов” осуществляет буферная память ГКВ-команд). Проведённая “от руки” огибающая имеет характерную форму – резкий подъём вначале с постепенным плавным понижением к концу выполнения программы. Подобная форма кривой ИВ является типовой при вычислениях по различным алгоритмам (программам).
Не наводит ли Вас подобная форма кривой (“несимметричный ко́локол”) на некие соображения о сущности исследуемого процесса?.. такая форма встречается при анализе процессов массового обслуживания (потоковый вычислитель фактически и осуществляет процесс массового обслуживания с ожиданием!). При анализе функционирования параллельной вычислительной системы автору представляется супермаркет (варианты – зал ожидания аэропорта, вокзала) с огромным количеством покупателей (операторов) и сную́щих среди них зверского вида надзирателей, по высшим причинно-следственным критериям выстраивающим покупателей (операторы) в очередь к кассам (отдельным вычислителям).
А как будут выглядеть диаграммы интенсивности вычислений при несоблюдении условия неограниченного параллелизма?
Видно, что по мере снижения числа задействованных параллельных вычислителей график сглаживается (автор считает приемлемой метафору “раска́тки теста хозяйкой круглой cка́лкой”), при этом при сохранении “шква́листого” характера графиков растёт плотность кода (что визуально заметно по снижению числа и размеров светлых промежутков на графике). Такое состояние всё менее благоприятно для совместного использования АИУ другими программами (многопользовательский режим).
- Очень интересный психологический момент “огово́рки по Фрейду” – в своё время автор занимался конструированием оборудования для пластической деформации металлов (см. здесь, тут и здесь), поэтому симво́лика процесса “раска́тки теста круглым валко́м” для него вполне естественна.
Решение уравнения итерационным численным методом (бисе́кция) при использовании ма́кросов 1D-псевдомассивов
Напомним, что затруднения при программировании (являющиеся следствие использования симулятора вычислительной системы статической архитектуры Data-Flow) могут быть вызваны необходимостью использования принципа единократного присва́ивания - все переменные (фактически адреса́ в памяти) создаются в момент присваивания и обладают свойством ReadOnly (т.е. могут быть неограниченно раз счи́тываемы, но не перезапи́сываемы); условность выполнения частей программы реализуется предика́тным способом (без использования регистра-счётчика команд и, соответственно, “goto”).
Алгоритм (на C-подобном языке программирования с сохранением имён переменных) решения приведён ниже; посредством *fun обозначена ссылка на функцию, нулевое значение которой ищется (диапазон поиска корня обозначен XN и XK).
XI=(XN+XK)/2.0; // XI - точка посредине между XN и XK
//
FN=(*fun)(XN); // вычисление значения функции в точке XN
FK=(*fun)(XK); // … то же в точке XK
XI=(*fun)(XI); // … то же в точке XI
//
do { // начало итераций по поиску корня функции
//
if(FI*FB)>0.0 // точку XK перемещаем в XI
{
XK=XI;
FK=FI;
}
//
if(FI*FN)>0.0 ) // точку XN перемещаем в XI
{
XN=XI;
FN=FI;
}
//
XI=(XN+XK)/2.0 // точка XI посредине между XN и XK
//
FI=(*fun)(XI); // за́ново вычислим значение функции в точке XI
//
} while(fabs(XN-XK) > eps); // циклы, пока за́данная точность не достигнута
Как сказано, текущие параметры тела функции располагаются в соседствующих индексах одномерного массива, для реализации условий в алгоритме использованы инструкции PGT (выделены цветом на листинге); присваивание переменных следующему индексу псевдомассивов реализованы с помощью флагов-предикатов FLAG_1 и FLAG_2 (выделены цветом).
Число итераций при нахождении корня функции конста́нтно задаётся равным 10 (строка 27 нижеприведённой иллюстрации – что соответствует точности определения корня приблизительно в ≈5×10^(-3)), исходные данные заданы инструкциями 7,8 (первое приближе́ние – элементы псевдомассивов XN[1] и XK[1]).
Общее число вычислений искомой функции равно 3+N (где N – количество итераций). Инструкции вычисления функции fun=x^2-1 включены в код и соответствуют операторам 15÷16, 18÷19 и 22÷25 соответственно, решение располагается в переменной XI[N+1] (где N – максимальный индекс псевдомассива). Исследователь может дополнить алгоритм анализом достиѓнутой точности (необходимо с помощью инструкции анализа значений модуля (XN-XK) установить флаг достижения точности, скомпоновать его с флагами FLAG_1 и FLАG_2 и использовать во всех инструкциях с целью организации их выполнения/про́пуска).
В правой части вышеприведённого рисунка изображена кривая (график) интенсивности вычислений в условиях неограниченного параллелизма. Видно, что в данном случае одновременно задействованы не более 5 параллельных вычислителей, форма кривой имеет 10 (по числу итераций) явных пи́ков (обладает неравномерным шква́листым характером, что характерно для итерационных процессов).
Умножение двух векторов с использованием ма́кросов 1D-псевдомассивов
Несложно реализовать перемножение векторов (исходные данные генерируются в строках 11÷15, частичные суммы результатов умножений накапливаются в последовательных элементах C[j]); первоначальное обнуление C[1] осуществляется в строке 7, результат перемножения векторов формируется в скаляре C[1’001]. ЯПФ информационного графа имеет крайне неравномерную форму по высоте – первый ярус имеет ширину 1’000 (общее число входных данных 2’000), оставшиеся 1’000 – единичную ширину. Из такого распределения шири́н следует удобство первоначальной генерации ЯПФ в “верхнем” варианте (с последующим переносом операторов “сверху вниз”), при этом последующие 1’000 ярусов не могут иметь ширину более 1 (что соответствует чисто последовательному выполнению операций).
Заметим, что график интенсивности вычислений крайне неравноме́рен и имеет характерный “стулообра́зный” вид (спин́ка стула + сиде́нье). При этом на ширину “спинки стула” приходится всего (10^2)% общего времени выполнения программы (используются 1’000 параллельных вычислителей - это длина векторов и соответствует операциям перемножения их элементов) и оставшееся время (“сиденье стула”) – всего 1 вычислитель (соответствует накопи́тельному суммированию полученных ранее произведений).
Умножение матрицы на вектор с использованием ма́кросов 2D-псевдомассивов
Пример использования 2D-псевдомассовое приведён выше (размер матрицы 10×10, но Исследователь без труда изменит его). В строках 9÷15 происходит инициализация элементов матрицы A[10:10], вектора-столбца B[10:1] и вектора-результата перемножения C[10:1] (промежуточные произведения будут накапливаться в элементах C[i:2,3..11]; в строках 19÷25 – собственно умножение). График интенсивности вычислений также имеет характерный “стулообра́зный” вид. При этом на около 10% начального времени вычислений используются 100 параллельных вычислителей (это квадрат порядка матрицы и соответствует операциям перемножения элементов строк матрицы и столбца вектора) и на 90% оставшегося времени - 10 вычислителей (это порядок матрицы и соответствует накопи́тельному суммированию полученных ранее произведений).
Кстати, при необходимости использования одноме́рных 1D-псевдомассивов в макросах 2D-псевдомассивов достаточно применить конструкцию типа B[i:1] (при объявлении начального значения индекса j равным 1 данный индекс использоваться не будет). В этой ситуации интерпретатор системы DF сгенерирует предупреждающее сообщение вида “-W- add_Data(): Обнаружена попытка переписи элемента данных B[3:1] тем же значением 1 (время: 2 тактов)... -W-”, ошибкой не являющееся.
А теперь “научно предскажи́те”, какие конструкции псевдомассивов понадобятся для реализации перемножения двух матриц (без искусственных ухищрений, при́званных обойти принцип единократного присваивания)?..
● Правильно (ответ “лежит на поверхности”) - будет необходим 3D-псевдомассив соответственно… придётся автору запрограммировать макросы для реализации 3D-псевдомассивов!..
● Следующий вопрос к вду́мчивому Читателю – а как изменится форма графика интенсивности вычислений? Из соображений анало́гии сохранится “стулообра́зная” форма. Но какова высота “спинки” и “сиденья стула”?
● По секрету - высота “спинки” будет пропорциональна кубу порядка матриц, а высота “сиденья” – о́ной квадрату.
● Автор (в силу своей зловре́дности) всё же задаст ещё один вопрос – а как будет соизмеря́ться ширина (по времени - оси абсцисс) “спинки” и “сиденья” в зависимости от порядка перемножаемых матриц? Правильно отве́тивший “получит водока́чку” - в дополнение к собственному (глубокому) моральному удовлетворе́нию…
Некоторые идеи автора по поводу только что полученных данных (касаются ограниченности потенциала параллелизма в области “сиденья стула” для реализаций операций перемножения векторов и матриц) – см. публикацию #016.
Удачными (удобными) ли кажутся Вам основные приёмы работы с программной системой (исследовательским инструментом) ПРАКТИКУМ DF? Что бы хотелось Вам добавить в его функциональность для получения лучших результатов?
Авторские ресурсы:
Информация о канале вообще и его оглавление…
- В работе мы используем специализированное авторское программное обеспечение (фактически исследовательские инструменты), предназначенное для выявления в произвольных алгоритмах параллелизма и его рационального использования при вычислениях.
В.М.Баканов. Практический анализ алгоритмов и эффективность параллельных вычислений. ISBN 978-5-98604-911-3. 2023. LitRes.ru