Оптимизация SQL для больших наборов данных - важный шаг в управлении производительностью вашей базы данных. Следуйте этим рекомендациям, чтобы добиться более быстрого поиска данных и эффективности.

Оптимизация SQL для наборов данных актуальна независимо от размера набора данных, но это особенно важно при работе с большими неструктурированными данными.
Игнорирование оптимизации может привести к таким проблемам, как медленное выполнение запросов, высокое потребление ресурсов и потенциальная потеря данных. Оптимизируя SQL, вы управляете производительностью своей базы данных с точки зрения скорости и экономии места, позволяя быстрее извлекать данные из больших таблиц в более короткие сроки.
4 МЕТОДА ОПТИМИЗАЦИИ SQL-ЗАПРОСОВ ДЛЯ БОЛЬШИХ НАБОРОВ ДАННЫХ
- Избегайте использования SELECT*.
- Выберите правильный JOIN: LEFT, RIGHT, OUTER и INNER.
- Используйте обычные табличные выражения.
- Управляйте объемом извлечения данных с помощью LIMIT и TOP.
Как выбрать правильный индекс базы данных
При рассмотрении индексации базы данных как кластеризованные, так и некластеризованные индексы играют решающую роль в определении производительности вашей базы данных. Точность и стратегическая реализация этих индексов являются жизненно важными аспектами, которые существенно влияют на общую эффективность вашей системы баз данных. Важно знать, когда использовать каждый тип индекса, чтобы максимизировать преимущества, которые они приносят.
КЛАСТЕРИЗОВАННЫЕ ИНДЕКСЫ
Кластеризованный индекс упорядочивает строки данных на диске в соответствии с порядком следования индекса. Это обеспечивает высокоэффективный поиск данных по столбцам, к которым часто обращаются. Представьте это как хорошо организованную книжную полку, где каждая книга находится именно там, где вы ожидаете. Однако таблица может иметь только один кластеризованный индекс, поэтому крайне важно применять его разумно. Лучше всего применять его к столбцам, по которым часто выполняется поиск, и данные в значительной степени уникальны.
Чтобы реализовать кластеризованный индекс в таблице базы данных, выполните следующие действия:
- Выберите таблицу и столбцы для индекса на основе использования запроса и распределения данных.
- Просмотрите текущие индексы, чтобы избежать конфликтов с новым кластеризованным индексом; скорректируйте или удалите по мере необходимости.
- Используйте соответствующую команду SQL на основе вашей системы управления базами данных (СУБД).
- Проверьте создание индекса и его влияние на производительность запросов.
-- SQL Server
CREATE CLUSTERED INDEX IX_Country ON Customers (Country);
Планируйте создание индекса в непиковые часы, чтобы минимизировать сбои и оценить влияние на операции с данными.
НЕКЛАСТЕРИЗОВАННЫЕ ИНДЕКСЫ
Некластеризованные индексы действуют как сложный каталог, который указывает на данные, расположенные в другом месте, а не в фактическом хранилище данных таблицы. Эти индексы позволяют создавать множество опорных точек, каждая из которых настраивается для конкретной оптимизации запросов. Представьте, что некластеризованные индексы создают сеть быстрых переходов к вашим данным.
Это наиболее полезно для столбцов с широким диапазоном значений и нечасто обновляющихся. Хотя некластеризованные индексы, как правило, более универсальны, чем кластеризованные, у них есть некоторые компромиссы. Например, они требуют больше места для хранения и потенциально могут замедлить вставку и обновление данных.
Рекомендации по реализации некластеризованных индексов в таблице базы данных:
- Определите таблицу и столбцы, которые больше всего выиграют от некластеризованного индекса
- Оцените существующие индексы, чтобы убедиться, что новый индекс будет дополнять их, а не конфликтовать с ними.
- Используйте синтаксис SQL для создания некластеризованного индекса в соответствии с вашей СУБД.
- После внедрения индекса следите за производительностью запросов и корректируйте индекс по мере необходимости для оптимизации скорости и использования ресурсов.
-- SQL Server
CREATE NONCLUSTERED INDEX IX_Country ON Customers (Country);
Создание индексов и управление ими требует тщательного планирования и постоянной оценки для обеспечения эффективной работы. Регулярно пересматривайте и корректируйте свою стратегию индексации для поддержания оптимальной производительности БД по мере роста объема данных и изменения требований к запросам.
Основное различие между кластеризованными и некластеризованными индексами заключается в том, как данные физически организованы на диске. Кластеризованные индексы изменяют порядок строк данных, в то время как некластеризованные индексы указывают на местоположения данных. Оба типа имеют решающее значение для оптимизации SQL с большими наборами данных и эффективного извлечения данных.
ОПТИМИЗАЦИЯ ИНДЕКСАЦИИ ТЕКСТОВЫХ СТОЛБЦОВ
Помимо классических типов индексов, существует специализированный подход для текстовых столбцов: индексы полнотекстового поиска. Оптимизация текстовых столбцов с помощью этих индексов расширяет возможности поиска в вашей базе данных, выходя за рамки простого сопоставления с шаблоном, позволяя выполнять сложный поиск по большим объемам текста с поразительной легкостью. Важно использовать весь потенциал этих текстовых индексов, чтобы ваша база данных оставалась отзывчивой.
Вы можете реализовать это, создав полнотекстовый индекс в таблице вашей базы данных, который индексирует текстовые столбцы на основе содержащихся в них слов и фраз. Это позволяет получать более быстрые результаты поиска при поиске определенных слов или фраз в больших блоках текста с минимальными накладными расходами.
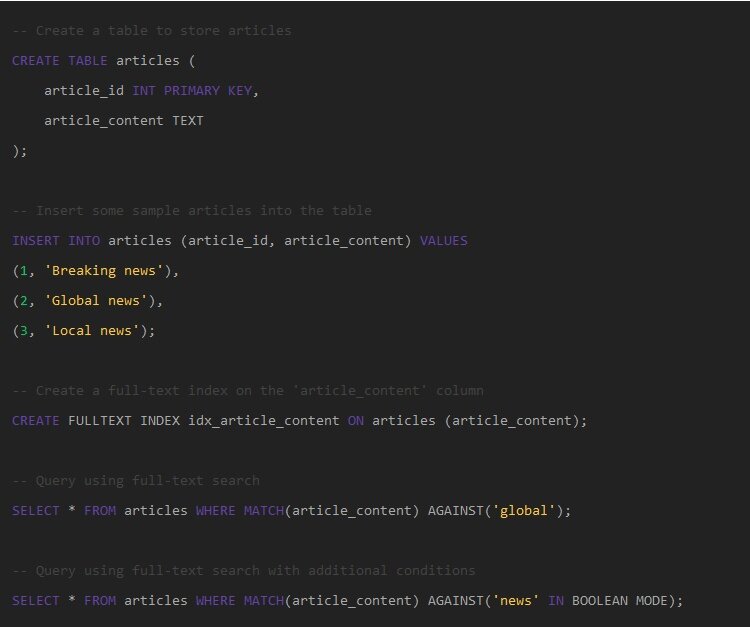
Полнотекстовые индексы используют процесс, называемый токенизацией, для разбиения текста на более мелкие блоки, что упрощает и ускоряет поиск в базах данных. Эта функция позволяет полнотекстовому индексу функционировать как инвертированный индекс.
Для дальнейшей оптимизации индексации текстовых столбцов вы также можете указать дополнительные параметры, такие как стоп-слова и разделители слов для конкретного языка. Стоп-слова - это часто встречающиеся слова, которые не повышают ценность результатов поиска, такие как "the", "a" и "and". Указав список стоп-слов, полнотекстовый индекс может исключить эти слова из процесса индексации, что приведет к более точным и эффективным результатам поиска.
Эффективная стратегия индексирования заключается не просто во внедрении индексов; речь идет о выполнении правильного индексирования для текущей задачи. В качестве наилучшей практики напомните себе об этом принципе: индексируйте намеренно, и за этим последует доступность ваших данных.
Методы оптимизации запросов
Эффективные запросы являются основой высокопроизводительных баз данных и освоение этого может привести к значительному повышению скорости поиска и использования ресурсов.
Независимо от того, работаете ли вы с базовыми извлечениями или организуете сложные симфонии данных с помощью нескольких соединений, грамотная разработка запросов может значительно сократить время отклика и нагрузку на систему.
ИЗБЕГАЙТЕ ИСПОЛЬЗОВАНИЯ SELECT *
Давайте применим стратегический подход, подобный опытному игроку в шахматы. Вместо неразборчивого подхода `SELECT *`, который, по сути, охватывает все столбцы независимо от их непосредственной полезности, вместо этого сосредоточьтесь на выборе только важных столбцов. Этот целенаправленный выбор подобен выполнению хорошо спланированного шага, который гарантирует выполнение вашего запроса с оптимальной скоростью и эффективностью.
ВЫБЕРИТЕ ПРАВИЛЬНУЮ ОПЕРАЦИЮ ОБЪЕДИНЕНИЯ
Когда дело доходит до операций объединения, представьте их в виде тонких швов, которые связывают таблицы в единое целое. Ключ заключается в выборе правильного типа объединения — LEFT, RIGHT, OUTER или INNER, чтобы гарантировать целостность ваших данных и безупречную производительность запросов. Это точный выбор, во многом подобный выбору правильной нити для ткани, который может повлиять на результат.
Пример LEFT JOIN
LEFT JOIN возвращает все строки из левой таблицы (сотрудники) и соответствующие строки из правой таблицы (отделы). Если совпадения нет, NULL возвращаются значения для правильных столбцов таблицы.
Пример INNER JOIN
INNER JOIN возвращает только те строки, в которых есть совпадение в обеих таблицах, на основе указанного условия.
Пример RIGHT JOIN
RIGHT JOIN возвращает все строки из правой таблицы (отделы) и соответствующие строки из левой таблицы (сотрудники). Если совпадения нет, NULL возвращаются значения для левых столбцов таблицы.
Пример OUTER JOIN
OUTER JOIN возвращает все строки, если есть совпадение в левой или правой таблице. Если совпадения нет, NULL возвращаются значения для столбцов таблицы без совпадения.
ИСПОЛЬЗУЙТЕ ОБЩИЕ ТАБЛИЧНЫЕ ВЫРАЖЕНИЯ
Подзапросы в большом наборе данных могут создавать множество сложностей. Вместо этого ознакомьтесь с обычными табличными выражениями. Общие табличные выражения (CTE) улучшают читаемость ваших SQL запросов и представляют собой более упорядоченную альтернативу, оптимизирующую производительность.
Пример CTE
CTE — это временный результат выполнения SQL-выражения, который можно использовать в другом SQL-выражении. CTE позволяет упрощать сложные SQL-запросы, разбивая их на составные части. Давайте используем те же таблицы employees и departments для этого примера:
УПРАВЛЯЙТЕ ОБЪЕМОМ ИЗВЛЕЧЕНИЯ ДАННЫХ С ПОМОЩЬЮ LIMIT И TOP
Думайте об операторах LIMIT и TOP как о бархатной веревочке вашей базы данных. Они являются требовательными защитниками, которые обеспечивают прохождение только необходимых данных, предотвращая перегрузку вашего сервера избыточными строками.
Пример LIMIT и OFFSET
Мониторинг производительности и тонкая настройка
Погружение в мир мониторинга производительности похоже на работу детектива. Вы ищете подсказки, которые выявят узкие места, замедляющие выполнение ваших SQL-запросов.
Это требует неустанной работы в фоновом режиме для обнаружения и обозначения любых падений производительности по мере их возникновения. Представьте себе настройку современной информационной панели, которая немедленно предупреждает вас даже о малейшем сбое в производительности запросов. Такой уровень бдительности имеет решающее значение для обеспечения зоркого контроля за работоспособностью вашей базы данных.
ОПЕРАТОРЫ ОБЪЕДИНЕНИЯ
Когда вам нужно объединить результаты из нескольких операторов SELECT, вы можете перейти к объединению`UNION`. Но есть и другой нюанс — переключитесь на `UNION ALL` и наблюдайте, как стремительно растет производительность ваших запросов. В отличие от `UNION`, который кропотливо удаляет дубликаты, вызывающие накладные расходы, `UNION ALL` подобен свободной реке, быстро объединяющей результаты без дополнительной проверки на наличие дубликатов. `UNION ALL` доверяет оригинальности ваших данных и не подвергает их сомнению, что приводит к более быстрым результатам.
Пример UNION ALL
‘EXISTS’ VS. ‘IN’
При подтверждении наличия данных используйте "EXISTS", а не "IN" для более эффективной работы с запросом. Предикат "EXISTS" останавливается при первом обнаружении, что сродни быстрому просмотру для подтверждения наличия, в то время как "IN" может неоправданно расширить поиск. Этот стратегический выбор может значительно сократить время выполнения запросов.
Пример EXISTS
В этом примере внешний запрос выбирает department_name из таблицы departments . Оператор EXISTS используется с оператором WHERE , чтобы проверить, есть ли какие-либо сотрудники в отделе ‘IT’ . Подзапрос возвращает результат 1 если такие сотрудники есть, и условие EXISTS выполнено.
Освоение нюансов настройки производительности SQL - это путешествие, требующее тщательного подхода к управлению данными и понимания широкого спектра доступных методов оптимизации.
Точно так же, как точно настроенный инструмент может поднять производительность до новых высот, хорошо оптимизированная база данных может значительно повысить скорость реагирования и эффективность вашего приложения. Независимо от того, профессионал ли вы или готовитесь к собеседованию по SQL, стремление оптимизировать свои способности в области SQL, несомненно, окупится на быстро меняющейся технологической арене, в которой мы работаем сегодня.
https://builtin.com/articles/optimize-sql-for-large-data-sets