Раскрытие скрытой логики, стоящей за порядком выполнения команд SQL.
SQL стал обязательным языком для любого специалиста по обработке данных.
Большинство из нас использует SQL в нашей повседневной работе, и после написания множества запросов у всех вырабатывается свой собственный стиль и свои привычки, как хорошие, так и плохие.
SQL обычно изучается в процессе использования, и в большинстве случаев люди обычно не понимают логики, стоящей за ним.
Вот почему сегодня мы погружаемся в интригующий мир порядка выполнения SQL запросов, где последовательность событий иногда может показаться головоломкой.
Итак, давайте обратим внимание на наиболее распространенную структуру SQL-запросов.
SQL как декларативный язык
Первое, что нужно понять, это то, что SQL является декларативным языком программирования, что означает, что мы указываем желаемый результат, но не то, какие шаги требуются для его достижения.
Это полная противоположность процедурным языкам, которые определяют каждый шаг, который необходимо выполнить для достижения желаемого результата.
Но что это значит?
Это означает, что SQL требует, чтобы команды были закодированы в определенном синтаксисе. Однако порядок, в котором мы пишем эти команды, не отражает порядок, в котором SQL их обрабатывает.
Обычно запрос выполняется со структурой, подобной этой:

Даже если человек читал и кодировал, следуя предыдущей структуре, при рассмотрении того, как выполняется этот код, порядок полностью меняется.
Например, хотя оператор SELECT написан как первая команда, он не вычисляется почти до конца.
Визуальное представление порядка выполнения
Чтобы лучше понять этот порядок выполнения, давайте пройдемся шаг за шагом и посмотрим, что SQL делает с каждой командой, которую мы пишем в коде.
Шаг 1 - FROM и JOIN
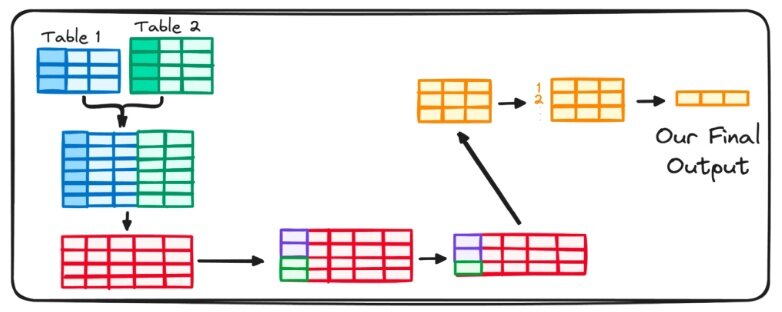
Процесс выполнения SQL-запроса начинается с оператора FROM, которое указывает на источник данных. В то время как простые запросы могут обращаться только к одной таблице, данные, которые мы ищем, часто содержатся в нескольких таблицах.
Именно здесь вступает в действие команда JOIN, идущая рука об руку с командой FROM, для объединения потоков данных.
Это сочетание всегда играет ведущую роль, подготавливая почву для точного определения данных, которые будут играть определенную роль в нашем запросе.
Шаг 2 - WHERE
После первоначального выбора оператор WHERE занимает центральное место.
Его основная роль заключается в просмотре базовой таблицы или объединенных выходных данных, гарантируя сохранение только строк, удовлетворяющих определенному условию.
Шаг 3 - GROUP BY
Оператор GROUP BY выполняет упорядочивание данных, разбивая их на кластеры в соответствии со значениями в одном или нескольких столбцах. Это позволяет нам выполнять агрегирование или сводку.
Считайте его мастером обработки данных, сводящим множество переменных к единственному значению для каждого уникального элемента или комбинации элементов.
Этот оператор является основной командой, лежащей в основе агрегирования данных, подготавливающей почву для итоговой производительности с помощью таких функций, как COUNT(), SUM(), MIN() и MAX() среди прочих.
Шаг 4 - HAVING
Оператор HAVING играет роль строгого фильтра, устраняющего те группировки, которые не соответствуют установленным критериям.
Представьте это как гейткипер (Gatekeeper – это программа, управляющая доступом к видеоконференциям, маршрутизацией и обработкой вызовов и голосовых потоков), гарантирующий, что к работе допускаются только те группы, которые соответствуют нашим агрегированным условиям. Он вступает в действие после того, как оператор GROUP BY выполнило свою часть работы, позволяя нам применять фильтры к уже агрегированным данным.
На данном этапе базе данных уже известны вычисленные агрегированные значения, что означает, что мы можем использовать эти агрегированные значения в последующих инструкциях.
Для устранения распространенного заблуждения о том, почему оператор WHERE не может вызывать агрегированные переменные, в то время как HAVE может:
Это потому, что WHERE занимает этап перед оператором GROUP BY, в то время, когда отдельные точки данных еще не были скомпилированы в группы. С другой стороны, HAVING имеет место, когда GROUP BY уже вычислена
Шаг 5 - SELECT
Оператор SELECT определяет столбцы, которые мы хотим сохранить в нашей таблице, вместе с любыми сгруппированными или агрегированными полями, которые были вычислены в процессе выполнения.
Здесь мы можем применить псевдонимы столбцов с помощью оператора AS .
Команда SELECT обычно используется вместе с командой DISTINCT , которая позволяет нам отбросить любую строку с повторяющимися значениями во всех столбцах, помеченных как DISTINCT.
Шаг 6 - ORDER BY
После завершения базовых задач запускается оператор ORDER BY, организующий отсортированное представление значений либо в порядке возрастания (ASC), либо в порядке убывания (DESC).
Представьте это как заключительный этап нашего запроса.
Мы собрали данные из наших исходных таблиц, усовершенствовали их с помощью фильтров, создали значимые группы и сводки и точно определили столбцы для отображения в наших конечных результатах.
Шаг 7 - ORDER BY
Наконец, оператор LIMIT помогает определить количество строк, которые мы хотим вернуть.
Оно особенно полезно при работе с большими таблицами, особенно на этапах разработки и тестирования.
Почему это важно?
Понимание последовательности выполнения SQL-кода с самого начала может показаться тривиальным, особенно когда запросы выдают правильные результаты.
Зачем беспокоиться о механике, если движок работает нормально, не так ли?
Тем не менее, для тех, кто погружается в глубины сложных запросов, знание этого порядка не просто полезно — оно крайне важно.
Без этого понимания поиск и устранение неисправностей превращается в лабиринт путаницы, где повсюду таятся ошибки. Для умелой отладки и более плавной обработки запросов необходимо четкое представление о том, как SQL обрабатывает операторы.
Вывод
Понимание порядка выполнения SQL имеет решающее значение для специалистов по обработке данных при разработке эффективных запросов.
Это понимание позволяет предвидеть поведение запроса, особенно в сложных наборах данных.
Освоение SQL предполагает выход за рамки синтаксиса и принятие его логики для стратегического манипулирования данными.
Путь, который мы проделали, от оператора FROM до LIMIT, представляет собой стратегический план обработки данных и формирования информации в соответствии с конкретными потребностями.
https://www.kdnuggets.com/the-essential-guide-to-sql-execution-order