Давайте рассмотрим решение реальной задачи, которую я получил от подписчика. Вот скриншот с озвученной проблемой:
То есть нужно как бы вычесть второй список из первого. Само содержание списков неважно. Это могут быть артикулы товаров, их названия, номера телефонов или табельные номера сотрудников, поэтому давайте рассмотрим решение на простейшем примере - из списка с наименованиями фруктов удалим данные из второго списка, содержащего только пять наименований.
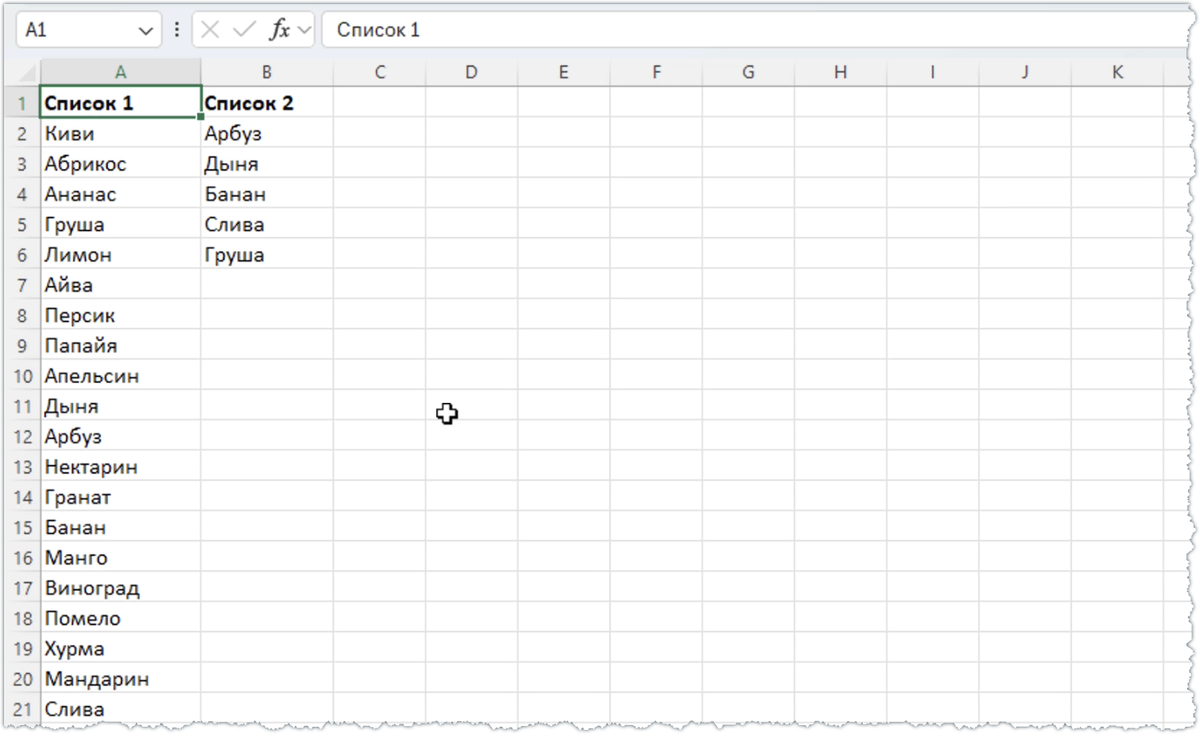
Алгоритм решения будет таким - сначала определим, какие элементы второго списка есть в первом, затем отобразим только эти элементы списка, выделим их и удалим.
Решение с помощью функции СЧЁТЕСЛИ
Поможет в этом функция СЧЁТЕСЛИ. С ее помощью сформируем проверочный столбец.
Мы будем искать в первом списке элементы из второго списка. Для этого сначала выделяем диапазон поиска - второй список, а в качестве критерия поиска укажем первый элемент первого списка.
Теперь размножим формулу на весь столбец и получим числовые значения.
Ноль будет означать, что во втором списке нет такого наименования. Осталось лишь включить фильтр для заголовков таблицы (сочетание клавиш Ctrl+Shift+L) и отфильтровать значения по вспомогательному столбцу - нас будут интересовать только единицы.
Теперь все отфильтрованные строки можно выделить и удалить.
Снимем фильтр, удалим столбцы со вторым списком и вспомогательной формулой и на этом задачу можно считать выполненной.
Решение с помощью удаления дубликатов
Ну и в качестве альтернативного варианта решения задачи хочу предложить следующий. В Эксель есть инструмент, позволяющий удалять дубликаты.
Он работает так - находит дублированные значения в указанном диапазоне и оставляет только первое найденное из них. Воспользуемся этой особенностью, чтобы решить нашу задачу.
Для наглядности я выделил значения из второго списка красным, а соответствующие значения в первом списке синим.
Теперь давайте перенесем первый список и разместим его ниже второго. Если сейчас применить удаление дубликатов в этом общем списке, то уникальные значения останутся только в верхней его части, то есть во втором списке, который я выделил красным.
Эксель будет считать дубликатами значения из первого списка, выделенные синим, и удалит их. После этого можно будет выделить и удалить первые строки с данными второго списка (выделены красным).
Таким образом мы решили ту же задачу, но без задействования каких-либо формул.
Ссылки на мои ресурсы по Excel
★ YouTube-канал по Excel и Word
★ Телеграм



















