
Почему среди программистов на Haskell бытует легенда, что если программа компилируется, то она верна? Почему мало смысла в споре между приверженцами статической и динамической типизации? Как превратить тип функции в теорему, а программу — в еë доказательство? Об этом и многом другом мы поговорим в мини-серии статей, посвящённой теории типов.
Зачем?
Когда речь заходит о типах и типизации в программировании, то в ход идут самые разные аналогии. Кто во что горазд! Типы сравнивают с наклейками на коробочках и с самими коробочками различной формы в процедурном и низкоуровневом программировании; с подходящими друг другу разъëмами в функциональном программировании; с объектами, интерфейсами, и ручками приборов в ООП... Все эти аналогии неплохи и помогают понять, как типы помогают программистам, писать и читать программы, а "умным" IDE позволяют делать разумные подсказки кодерам.
Но типы данных это не просто наклейки, разъëмы и интерфейсы. Они способны на гораздо большее!
Вы заметили, быть может, что всë тише становятся споры между сторонниками статической и динамической типизации, и огня в этих спорах становится всё меньше и меньше, поскольку математики тоже не сидят без дела и развивают теорию типов, позволяющую с помощью различных техник вывода, соединить эти два мира. Сейчас некоторые динамически типизированные языки обзавелись статически типизированными диалектами, типа TypeScript для JS, или подсказками типов (type hints), как в Python.
Но наиболее далеко продвинулось дело в теории алгебраических типов, на которой основывается вывод типов Хиндли-Милнера. Он, в свою очередь, работает в функциональных языках, таких как Haskell, F#, Scala, PureScsript, Elm, а также открывает путь к зависимым типам в языках Liquid Haskell, Agda или Coq.
Алгебраические типы могут дать программисту новую суперсилу — не просто избегать многих ошибок, а строго доказывать корректность своих программ и программных блоков, причём делать это с помощью компилятора. Так типизация превращается в часть формальной верификации программы: доказательстве того, что она верна и корректна.
О таком подходе к типам я и хочу рассказать. Все примеры в этой заметке будут проводиться, на языке Haskell, который наиболее явно реализует описываемый подход в своей системе типизации.
Пара слов о синтаксисе
Произвольные типы Haskell обозначаются строчными латинскими буквами, а конкретные типы и конструкторы типов — идентификаторами, начинающимися с заглавной буквы. Под конструктором понимается величина или функция, позволяющая получить экземпляр типа.
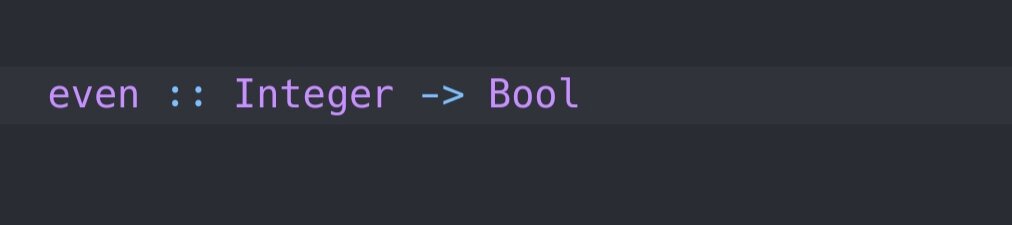
Тип функции записывается в виде стрелки. Так, например, функция even отображающая множество целых чисел на булево множество, будет иметь тип
При вызове и определении функций скобки не ставятся. Например, математическое выражение f(x) = h(x) + g(x+1) в синтаксисе Haskell мы будем писать так:
Обратите внимание на то, что скобки, всë же понадобились для обращения функции g, но только потому, что приоритет операции + ниже приоритета аппликации (применения функции к своему аргументу).
Когда нам не нужно будет давать никакого имени функции, мы будем записывать еë в форме анонимной или лямбда-функции:
Ну, поехали! И начнëм мы наш разговор с такого вопроса:
А что такое правильная программа?
Часто на него отвечают просто: это программа без багов и ошибок, которая эффективно делает то, что нужно. Но наиболее точный ответ такой: правильная программа та, что точно выполняет свою спецификацию.
И если в спецификации есть ошибки, логические противоречия, неопределённое поведение, или даже заложена возможность испортить компьютер, то корректная программа обязана всë это в точности описывать и выполнять.
Так что все вопросы к заказчику 😁
Верификация и подходящая система типов даёт нам возможность проверять на правильность, во-первых, программу, во-вторых, еë спецификацию, и, в-третьих, их эквивалентность. Этим верификация отличается от тестирования, которое сосредотачивается только на первом аспекте.
Можно заметить, в скобках, что тестирование школьников и студентов по схожей причине не сможет дать ответ на вопросы: корректно ли построен курс обучения и соответствует ли ему образовательный процесс, проверяя лишь свойства продукта — учащегося. Тогда как устный экзамен и собеседование выявляют системные качества и ученика и его учителя и программы.
Но вернёмся к программам. Эти ученики туповаты, но очень старательны и делают ровно то, чему учит их учитель, он же их творец, программист. Типы данных помогают нам и правильно выстроить "процесс обучения" и, в то же время, проконтролировать верно ли отражает полученные знания наша программа, которую мы закладываем в механического ученика.
Семантика типов
Для погружения в тему нам нужно взглянуть на типы данных с точки зрения математика. Поэтому я позволю себе на минутку включить лектора и навести некоторую систему.
В наиболее общем смысле тип величины определяет еë семантику, то есть, наделяет величину известным смыслом.
Семантика бывает операционной, она определяет внутреннее представление величины в вычислительной среде (памяти, диске и т. д.). Обычно такую семантику задаёт структурная типизация, как в С, в языках ассемблера, или специальных языках низкого уровня, типа PostScript.
Чаще всего, вместе с операционной семантикой с помощью типов определяют аксиоматическую семантику, которая задаëт допустимые значения величины и операции над ней. В этом направлении хорошо продвинулось объектно-ориентированное программирование, программирование с контрактами, и языки со строгой номинативной, динамической или утиной типизацией, как в С++, Python, JavaScript и вообще, в подавляющем большинстве современных языков программирования. Аксиоматическая семантика прекрасно подходит для выстраивания системы тестов, контрактов и ассертов, то есть, всего того, что работает во время выполнении программы.
Наконец, семантика типа может быть денотационной. Она, с известными ограничениями, позволяет отождествлять тип с каким-то формально определëнным математическим объектом, вроде множества, полугруппы, кольца, отображением или объектом более общих категорий. Денотационная семантика позволяет анализировать программу и еë спецификацию на этапе еë написания.
Денотационная семантика — дело сложное, но стоящее: она позволяет рассуждать о коде и статически анализировать его на принципиально новом уровне. Один из самых продуктивных на сегодняшний день подходов в этом предлагает теория категорий. Я не хочу сейчас детально разбирать основы этой теории, они не сложны, но быстро уведут нас в сторону, а сосредоточусь в своём рассказе на принципе построения алгебраических типов.
Слово "алгебраический" намекает на то, что типы можно как-то вычислять, используя какие-то операции. Базовых операций над типами немного: сложение, умножение и возведение в степень, но понимаются они не в арифметическом смысле, а в категориальном. В свою очередь, операции производятся над типами, как примитивными, так и более сложными.
Главное в алгебраическим подходе это то, что множество типов должно быть замкнутым относительно алгебраических операций, и функционально полным. Это значит, что складывая и перемножая типы, мы всегда будем получать новые типы, и что все доступные программисту типы, могут быть получены алгебраически.
Приведëм несколько примеров денотационной семантики для простых типов:
тип Char = множество символов Unicode;
тип Int = кольцо вычетов по модулю 2³² (для 32-битной архитектуры процессора);
тип Double = подполе вычетов в поле 2-адических чисел;
тип String = свободный моноид над множеством Char.
тип Integer = расширенное кольцо целых чисел ℤ.
Первый странный тип
Конечно же, настоящее кольцо ℤ в памяти компьютера не поместится. Ограничения, накладываемые памятью, в случае Integer в денотационной семантике можно выразить тем, что этот тип представляет целые числа, дополненные специальным значением ⊥, которое соответствует ошибке. Читается этот символ как «bottom», то есть, «дно», что, согласитесь, звучит весьма красноречиво!
Отличие ⊥ от значений null или NaN, существующих в других языках, состоит в том, что получить его нельзя никаким «законным» образом. Такое значение соответствует бесконечному циклу, аварийной остановке программы, либо не пойманному исключению. При всей своей патологичности, наличие этого значения составляет важное отличие вычислительной математики и логики от иных математических разделов. Функция, имеющая в своей области значений ⊥, называется частичной, программисты всячески стараются их избегать, и писать тотальные функции, которые доказуемо не могут сами привести к появлению ⊥. Но даже это не значит, что мы можем избавиться от наступления bottom по какой-то внешней причине. Поэтому в теории типов это значение неявно считается присутствующим в любом типе данных.
Операции над типами
Роль суммы двух типов играет размеченное объединение типов или тип-перечисление (union-type в C или Pascal). Простейшими примерами из Haskell могут быть типы, описывающие логические значения, или отношения порядка (меньше/равно/больше):
Эти два типа представляют собой суммы единичных типов. Такие типы представляют только самих себя. Их денотационная семантика — множество из одного единственного элемента.
Роль произведения типов играют такие привычные конструкции, как структура, запись (record), или кортеж. Простым примером может быть тип для точки
В этом смысле, базовое представление объекта в ООП, как структуры с полями и методами — это произведение типов полей и методов.
Роль возведения в степень в теории типов играют типы функций. Например, упомянутая выше функция-предикат, определяющая чётность целого числа, и имеющая тип
с точки зрения теории типов представляет тип Bool, возведённый в степень Integer.
Вот, собственно, и весь инструментарий! Ничего сверхъестественного или необычного, чего не было бы в вашем любимом языке программирования на том или ином уровне абстракции. Это не значит, что этим исчерпываются все варианты типизации (здесь, например, нет указателей на тип, нет классов и интерфейсов, не говоря уже о более экзотических линейных или зависимых типах) однако, пока для понимания основ теории типов нам этого будет достаточно. Алгебраические типы данных можно аккуратно дополнять более сложными конструкциями, соблюдая определëнные законы. И как показывает опыт языка Haskell, очень многие практически полезные выкрутасы и примыкает могут быть успешно реализованы в рамках его системы типов.
В следующий раз мы поговорим о том, какие законы выполняются в арифметике типов, что такое изоморфизм типов и что такое универсальные свойства.
А те, кому любопытно, как выглядит описание семантики современного языка, могут взглянуть на пример такого описания для языка C в стандарте ANSI:
Присмотревшись, там можно разглядеть монады 🙂