Задача
Используйте текстовый файл размером 46 КБ names.txt, содержащий более пяти тысяч имен. Начните с сортировки в алфавитном порядке. Затем подсчитайте алфавитные значения каждого имени и умножьте это значение на порядковый номер имени в отсортированном списке для получения количества очков имени.
Например, если список отсортирован по алфавиту, имя COLIN (алфавитное значение которого 3 + 15 + 12 + 9 + 14 = 53) является 938-м в списке. Поэтому, имя COLIN получает 938 × 53 = 49714 очков.
Какова сумма очков имен в файле?
Решение
Задача выглядит тривиальной для языков типа Питона. Там можно прочитать массив имён, отсортировать их и выполнить прочие необходимые действия чуть ли не в одну строчку. Ну или в две.
Язык C не обладает подобными возможностями, и даже просто создать массив имён из файла представляется проблемой. Потому что имена это строки, строки надо где-то размещать, а сделать это автоматически, как в Питоне, не получится.
Поэтому значительная часть программы будет посвящена получению списка имён.
Стратегия решения
- Узнать размер файла
- Выделить в памяти текстовый буфер такого же размера и считать в него файл
- Выделить буфер под хранение указателей на имена
- Сканировать текстовый буфер, обнаруживая в нём имена. Указатели на имена класть в буфер указателей
- Отсортировать буфер с указателями в алфавитном порядке
Ну а дальше всё просто.
Парсер
Для начала нужен парсер, который в текстовом буфере сможет найти начало очередного имени. Буфер выглядит так:

Сперва нужно найти открывающую кавычку, после неё будет первый символ имени, и сканировать далее до закрывающей кавычки.
Структура парсера:
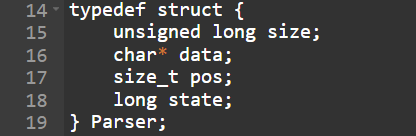
- size: размер буфера;
- data: указатель на буфер
- pos: позиция сканирования в буфере
- state: текущее состояние сканирования
Подготовим парсер к работе, загрузив в него данные из файла:
Чтобы узнать размер файла, нужно переместить позицию чтения/записи на конец файла с помощью fseek(), и затем узнать её с помощью ftell(). Затем переместить позицию обратно на начало.
После этого в парсере инициализируем указатель data, выделив для него память с помощью malloc(). Считываем данные в эту память из файла с помощью fread().
Структура имени
У каждого имени есть указатель на его начало (letters) и посчитанная парсером сумма букв (value).
Буфер сортировки имён
Сами имена находятся в прочитанном из файла текстовом буфере и никуда перемещаться не будут.
Буфер сортировки содержит только указатели на имена, и вот уже эти указатели надо будет сортировать и перемещать внутри буфера.
Чтобы его создать, нужно знать количество имён. Но оно заранее не известно, а усложнять код я не хочу. Поэтому, раз в задаче написано "свыше 5000 имён", то просто возьму размер 6000.
Сканирование
Далее можно вызывать функцию parser_get_name() и искать имена:
Функция parser_get_name():
Состояния парсера могут быть следующими:
#define STATE_NONE 'NONE'
#define STATE_GOGO 'GOGO'
#define STATE_NAME 'NAME'
Переключение между ними происходит так:
- Изначально парсер в состоянии NONE. Когда он найдёт первую кавычку, это будет открывающая кавычка, и за ней начинается слово. Парсер переходит в состояние готовности GOGO.
- В состоянии GOGO парсер сохраняет адрес начала слова и переключается в состояние дальнейшего чтения NAME.
- В состоянии NAME парсер читает символы имени, пока не встретит кавычку. Это закрывающая кавычка, после которой парсер переходит в состояние NONE.
Также парсер выполняет две дополнительные функции: сразу подсчитывает сумму букв в слове, так как она понадобится дальше, и записывает вместо закрывающей кавычки нулевой байт – таким образом участок буфера от начала слова и до нулевого байта превращается в полноценную строку языка C.
Сортировка
Для сортировки воспользуемся стандартной функцией qsort():
qsort(names, name_count, sizeof(Name), compare);
Она оперирует абстрактными параметрами, которые задаются вручную.
- names это адрес начала буфера
- name_count это количество элементов в буфере
- sizeof(Name) это размер в байтах одного элемента буфера – структуры Name
- compare это адрес функции, которая будет сравнивать два элемента:
Строки сравниваются также стандартной функцией strcmp(), куда надо передать указатели на первую и вторую строку.
Но на вход функции compare() приходят указатели типа void*, так как qsort() не знает, какими данными она оперирует. Поэтому нужно привести тип указателя к типу Name*. И затем уже у этого типа взять ссылку на letters, которая и будет строкой.
Больше об адресах и указателях я рассказываю здесь:
Подсчёт
Ну и когда список указателей на имена отсортирован, осталось пройти по нему и умножить позицию указателя на сумму букв слова.
Ссылка на онлайн-компилятор языка C с текстом программы (онлайн работать не будет, потому что требуется чтение из файла)
Подборка всех задач: