Приветствую, мои дорогие читатели!
Сегодня я хочу рассказать вам об одном замечательном проекте, который я написал за эти выходные Russian Toxicity Classifier API. Пришла мне в голову идея создать его после того как я начал собирать большой датасет с матюками (и их комбинациями) для другого моего проекта (о нём обязательно расскажу в одной из следующих публикаций).

Введение
Так вот, в процессе работы над упомянутым выше датасетом я столкнулся с потребностью в наглядности и в быстрой и автоматической классификации текста на "токсичный" и "нейтральный", потому как альтернатива была в ручной или полуручной разметке, чего мне делать естественно не хотелось.
И именно эта проблема, а также моя лень стали отправной точкой для создания проекта классификации русских текстов на токсичный и нейтральный.
Label Studio
Начну издалека, некоторое время назад мне пришла в голову идея создания системы для управления датасетами, чтобы можно было какие-то сырые данные импортировать, отмечать в них лейблы и экспортировать датасет пригодный для обучения модели в нужный формат. Но чуть более продолжительная работа над данной идеей и гуглёж показали, что существует уже готовая система, выполняющая схожие функции, под названием Label Studio.
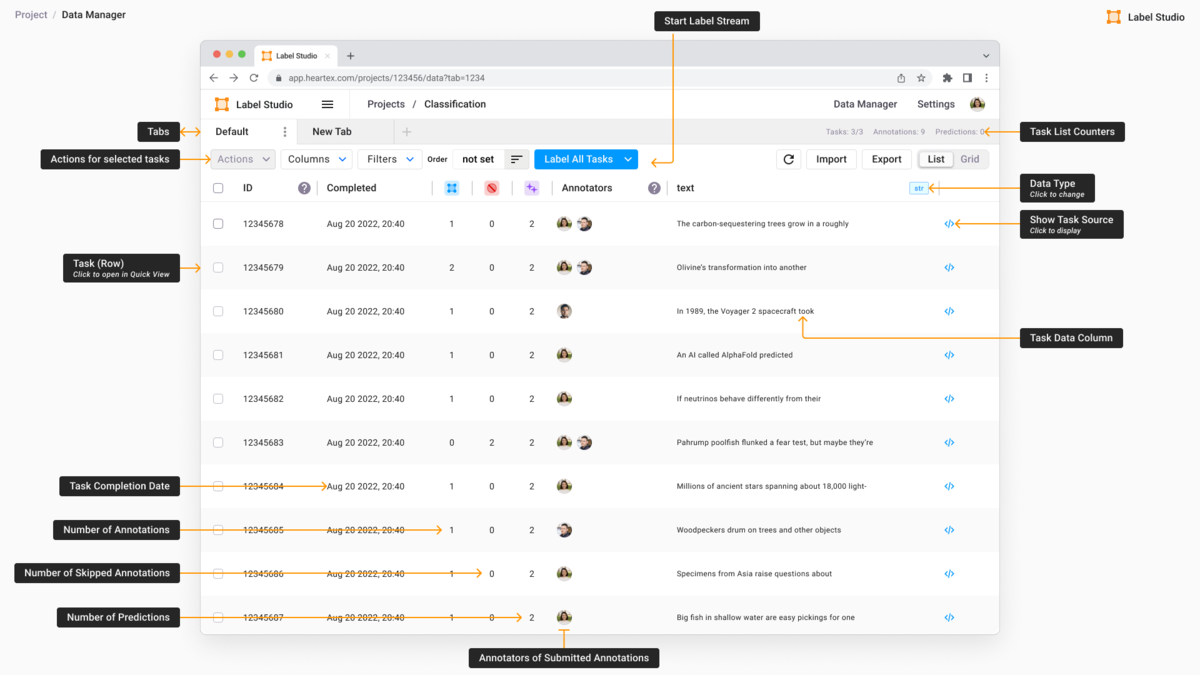
К слову сказать эта система настолько мне понравилась, что я перенёс упомянутый ранее "токсичный" датасет в неё из своей, короче проблема с наглядностью и удобством была решена.
ML-Assisted Labeling
Но самая главная фича Label Studio это не столько удобный и отзывчивый интерфейс, сколько встроенная возможность общаться с внешними API для выполнения задач предсказания, например классификации текста, осталось только найти какие-то готовые решения и использовать их.
И я наткнулся на репозиторий Label Studio ML backend, в ней, в папке examples было несколько любопытных решений, позволяющих реализовать интеграцию для Label Studio, и как следствие, полностью автоматизировать процесс расстановки лейблов типа toxic/neutral.
Для классификации токсичности русскоязычного текста я решил использовать модель s-nlp/russian_toxicity_classifier, с которой можно очень удобно работать через transformers. Но, как это часто бывает, готового решения, которое удовлетворяло бы моим требованиям, в примерах не нашлось, даже гугл не помогал, такое ощущение, что никто не додумался использовать классификацию при помощи трансформеров совместно с Label Studio ML backend (однако, замечу, что есть пример работы с трансформерами через GPT модели).
И вот, под впечатлением от возможностей Label Studio, я решил взять инициативу в свои руки и написать эту интеграцию самостоятельно.
В итоге, теперь у меня есть инструмент, который не только экономит мне кучу времени, но и делает процесс классификации текста гораздо более точным и автоматизированным. А теперь техническая часть...
Запуск проекта
Но перед тем как мы продолжим реклама^W хочу сразу предупредить, что желательно иметь не самую старую видеокарту Nvidia (например что-то на уровне 3050 или выше), а также свежий драйвер видеокарты и драйвер cuda (не ниже 11.7).
В принципе можно выполнять операции классификации текста и на процессоре (без видеокарты), оно будет работать, но скорость будет в разы меньше чем на видеокарте.
Едем дальше.
Когда я задумывал проект Russian Toxicity Classifier API я предусмотрел два варианта запуска: локальный при помощи Python VirtualEnv и при помощи Docker-контейнера, рассмотрим для начала вариант локального запуска в виртуальном окружении.
Локально через venv
Данный способ кажется мне наиболее простым, для того чтобы потыкать возможности проекта, плюс не нужно настраивать nvidia-runtime в конфигурациях Docker, достаточно иметь драйвер видеокарты и cuda драйвер.
Для начала, склонируйте репозиторий проекта:
git clone https://github.com/EvilFreelancer/ru-toxicml-api.git
cd ru-toxicml-api
Создайте виртуальное окружение и активируйте его:
python3 -m venv venv
source venv/bin/activate
Установите необходимые зависимости:
pip install -r requirements.txt
И запустите проект при помощи gunicorn:
gunicorn --preload --bind :5000 --workers 1 --threads 8 --timeout 0 app.main:app
Теперь вы можете перейти в ваш браузер и открыть http://localhost:5000, чтобы увидеть работу API.
При помощи Docker
Альтернативный вариант запуска осуществляется при помощи Docker-контейнера, в корне репозитория я подготовил Dockerfile и docker-compose.dist.yml с описанием того как это происходит.
Скопируйте конфигурацию docker-compose:
cp docker-compose.dist.yml docker-compose.yml
Выполните сборку контейнера:
docker-compose build
И запустите контейнер:
docker-compose up -d
Теперь вы можете перейти в ваш браузер и открыть http://localhost:5000, чтобы увидеть работу API.
Как пользоваться API
У проекта имеется несколько эндпоинтов, полный список можно посмотреть вот тут, но нас на данный момент интересует только два из них.
GET /
В корне будет отображаться информация о статусе системы, если открыть через браузер то API покажет что-то типа этого:
Иными словами данный эндпоинт можно использовать для мониторинга с целью проверить не отвалилась ли система.
POST /predict
Чтобы выполнить предикшен необходимо отправить POST запрос на эндпоинт /predict, ниже приведён пример простого curl запроса, который выполняет указанное действие:
curl -X POST "http://localhost:5000/predict" -H "Content-Type: application/json" -d '{"tasks": [{"data": {"text": "Your text 1"}},{"data": {"text": "Your text 2"}}]}'
Из примера видно, что нужно передать массив tasks, в котором содержатся текстовые сообщения, которые вам бы хотелось проанализировать.
Интеграция с Label Studio
Наше API готово, осталось заставить Label Studio общаться с ним, для этого перейдём на страницу Settings / Labeling Interface через интерфейс редактирования проекта датасета и добавим XML конфигурацию в которой будет описано какие лейблы можно выставлять у текста.
Нажмём на кнопку Save.
Далее, перейдём на страницу Settings / Machine Learning.
На данной странице нам будет нужно подключить наш API для выполнения задач автоматической классификации, для этого нажмём кнопку Add Model, после чего откроется модальное окно.
В поле Title напишем произвольный текст, лично мне удобно указывать там названия моделей которые я использую для классификации. В поле URL укажем http://localhost:5000. Можно ещё добавить Description, но это не обязательно. Переключатель Use for interactive preannontation можно включить.
По итогу у вас получится что-то вроде этого:
Далее жмём кнопку Validate and Save и если всё выполнено правильно, то модалка закроется и чуть ниже на странице появится только что добавленная модель.
В случае если Label Studio и проект ru-toxicml-api запущены у вас внутри Docker Network вместо localhost надо будет указать название сервиса который обслуживает ru-toxicml-api.
Из любопытных моментов, которые могут вам пригодится это переключатель Retrieve predictions when loading a task automatically. Он заставляет Label Studio отправлять на API классификатора все видимые элементы вашего датасета, так что рекомендую его включить.
Теперь если перейти в интерфейс ручной классификации элемента данных можно увидеть, что лейбл был автоматически проставлен.
Ну и как следствие в момент прокрутки у всех видимых элементов лейблы будут проставляться автоматически.
Чтобы запустить большого количества элементов датасета (все или например только выбранные), надо слева понажимать на чекбоксы, либо же в шапке нажать на чекборкс выбрать всё, после чего нажать на кнопку Actions и нажать Retrieve Predictions.
Система спросит подтверждение операции, после чего отправит запрос на API, получит лейблы и проставит их у элементов датасета.
Вот в принципе и вся магия.
Завершение
Кстати, я забыл упомянуть, что API сервер пока ещё не умеет выполнять автоматическое дообучение модели, но думаю в дальнейшем я и этот функционал реализую, на данном этапе мне было просто интересно как в принципе подружить какие-нибудь трансформеры классификаторы с Label Studio.
Надеюсь, что этот гайд будет полезен для вас и поможет легко и быстро развернуть и начать использовать Russian Toxicity Classifier API совместно с Label Studio. Если у вас возникнут вопросы или предложения, обязательно напишите мне!
Благодарю за внимание, пишет, жмите и не забудьте подписаться на мой Telegram-канал.
К тому же, если вы хотите поддержать мои усилия и вклад в развитие общества знаний, вы можете сделать пожертвование на CloudTips. Ваша поддержка поможет мне продолжать свою работу и делиться новыми открытиями с вами.