Специалисты лаборатории исследований искусственного интеллекта Tinkoff Research — одна из немногих исследовательских групп, которая проводит научные исследования внутри компании, а не на базе некоммерческой организации — сообщили об открытии нового алгоритма, обучающего ИИ в 20 раз быстрее. Результаты представили на 40-й Международной конференции по машинному обучению (ICML), прошедшей в конце июля на Гавайских островах.
Новый метод назвали SAC-RND — Soft Actor Critic (мягкий актор-критик), RND — Random Network Distillation (случайные нейронные сети). Как показали испытания на робототехнических симуляторах, SAC-RND от Tinkoff Research в 20 раз быстрее и на 10 процентов качественнее достигает результатов при меньшем количестве потребляемых ресурсов и времени.
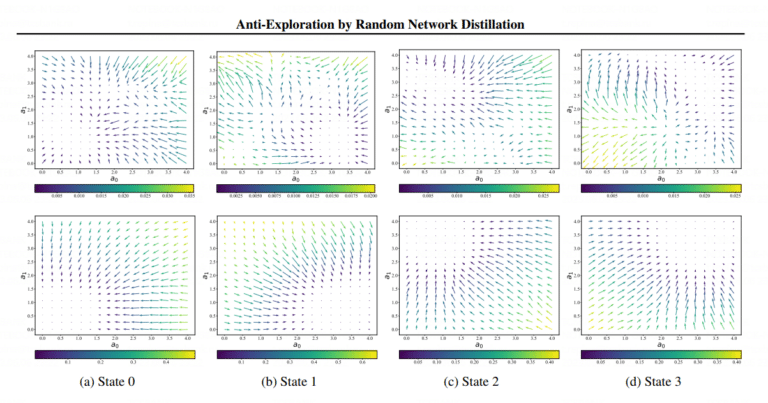
В методе RND задействованы случайная и основная нейросети, при этом вторая пытается предсказать поведение первой. Важна глубина нейросети, то есть количество слоев, из которых она состоит. У основной их не должно быть меньше, чем у случайной, в противном случае она не сможет смоделировать ее поведение. Это повлечет нестабильность либо станет причиной невозможности обучения.
Ученые из Tinkoff Research выяснили, что у авторов предыдущих исследований, посвященных теме использования случайных нейросетей в обучении с подкреплением (Reinforcement learning, RL), размер случайной сети составлял четыре слоя, в то время как у основной их было два. Таким образом удалось выявить недостатки в более ранних экспериментах и выводах, из-за которых считалось, что метод RND не способен классифицировать данные — отличать действия в датасете от тех, что там не было. Специалисты Tinkoff Research исправили глубины сетей, превратив их в эквивалентные, и обнаружили, что в таком случае метод может различать данные.
Затем ученые взялись за оптимизацию метода: в итоге, за счет механизма слияния, в основе которого — модуляция сигналов и их линейное отображение, — роботы научились приходить к эффективным решениям. В предыдущих исследованиях на тему RND сигналы дополнительно не обрабатывали.
Благодаря SAC-RND появится возможность повысить уровень безопасности беспилотных автомобилей, облегчить логистические цепочки, сделать быстрее доставку и работу на складах. Помимо этого, с помощью нового метода можно будет оптимизировать процессы горения на энергетических объектах и сократить выбросы вредных веществ.
Более того, разработка ученых из Tinkoff Research позволит не только сделать лучше работу узкоспециализированных роботов, ускорить исследования, в том числе в области обучения с подкреплением, но и приблизит создание универсального робота, который будет справляться с различными задачами в одиночку.