Статья размещена с разрешения автора, оригинал размещен на medium.com.
Я решил написать эту статью, опираясь на свой опыт чтения лекций по RL на курсе “Нейронные сети и их применение в научных исследованиях” в МГУ им. М. В. Ломоносова.
Часто на занятиях я сталкивался с недопониманием студентов в части применения Reinforcement Learning под конкретные цели. Не один раз слышал споры о том, какой алгоритм RL лучше, при этом многие не понимали или забывали, что выбор алгоритма зависит от его возможности “просчитать” саму среду или ее изменение, а также того, зависит ли само изменение среды от действий агента.
Наконец, накипело и я решил показать на примере, что начинать надо не с перебора новомодных методов и статей, а с анализа того, какой именно метод подходит для конкретной задачи!
На простом примере.
Мотивация
Когда мы сталкиваемся с числовыми рядами, то сразу возникает вопрос об их стационарности (об этом еще поговорим в отдельной статье). При стационарном числовом ряде (имеющего постоянную среднюю, дисперсия и без тренда), задача классификации ряда легко решается классическими методами машинного обучения (ML).
Если же числовой ряд нестационарен, например, курс акций, то при его прогнозировании или классификации возникают сложности. Такие исследования требуют затрат времени и определенного подхода к обучению нейронных сетей.
Тут нам на помощь приходит Reinforcement Learning, который особенно полезен, если нашу проблему можно описать
как MDP, и предвещает хорошие результаты, когда Среда или Вознаграждение нестационарны, т. е. значительно меняются со временем..
Давайте разберемся в том, что я сейчас написал ))
Немного теории о Reinforcement Learning
Как вы, возможно, уже знаете, основными частями системы обучения с подкреплением являются:
Среда (Environment) — это «игровое поле» или в нашем случае рынок, который может подсказать нам, что происходит прямо сейчас и какова будет наша награда в будущем, если мы совершим какое-то действие прямо сейчас. То, с чем взаимодействует Агент.
Агент (Agent) — «Игрок», который взаимодействует с окружающей средой и учится максимизировать долгосрочное вознаграждение, выполняя различные действия в различных ситуациях. Выбирает действия, основываясь на том, что известно о Среде из собранных данных и политики.
Действие (Action) — Различные варианты действий, которые Агент может выбрать в каждый момент времени.
Состояние (State) — Текущая ситуация агента.
Награда или Вознаграждение (Reward) — обратная связь от Среды, которая нужна агенту, чтобы узнать, было ли предпринятое Действие хорошим.
Политика (Policy) — Процесс выбора действий на основе известной информации об окружающей среде.
Ценность (Value) — будущая награда, которую агент получит, совершив действие в определенном состоянии.
Графически это можно представить на следующей схеме:
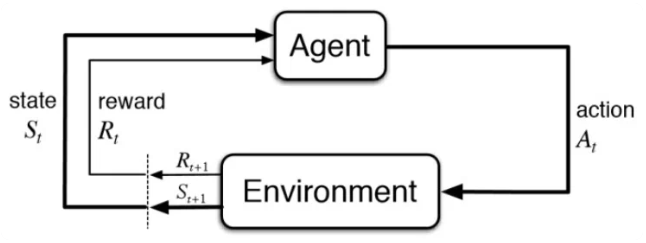
Упомянем также о Марковских процессах принятия решений (Markov Decision Proces (MDP)) — это последовательность временных шагов, в которых происходит взаимодействие с окружающей средой.
В каждый момент времени текущее состояние используется для выполнения шага действия, после чего среда предоставляет обратную связь в виде вознаграждения об этом шаге и новом состоянии
Рабочая среда
Если состояния сложны и их трудно представить в виде таблицы действий (Марковского процесса), их можно аппроксимировать с помощью нейронной сети (это то, что мы будем делать).
С помощью нейронной сети мы можем выбрать самое прибыльное действие в каждом состоянии (согласно нашей функции Q) и максимизировать награду.
Но как построить такую функцию Q? Здесь нам поможет алгоритм Q-Learning, основой которого будет знаменитое уравнение Беллмана:

где:
S = Состояние или наблюдение
A = Действие, которое предпринимает агент
R = Награда за действие
t = Временной шаг
a = Скорость обучения
ƛ = Коэффициент дисконтирования, из-за которого вознаграждения со временем теряют свою ценность, поэтому более немедленные вознаграждения ценятся выше
И немного про Дисконтирование:
В RL агент стремится к оптимальной политике, набору шагов, которые приводят к траектории (стратегии), обеспечивающей наибольшую награду. Это достигается путем оценки прямого вознаграждения за каждый следующий шаг плюс оценка вознаграждения за все будущие шаги при совершении этого действия.
Когда это непрерывная задача, расчет всех будущих вознаграждений невозможен, а оценка вознаграждения за большое количество шагов в будущем часто сопряжена с неопределенностью. Таким образом, Дисконтирование гарантирует, что больший вес придается ожидаемым вознаграждениям в ближайшем будущем, а меньший — более неопределенным вознаграждениям в отдаленном будущем.
Подходы к реализации Reinforcement Learning
Время от времени приходится наблюдать попытки нейронщиков подойти к решению задачи предсказания направления движения числового ряда. Обычно, при первых неудачах, делается вывод, что использованный алгоритм плох и нужно его усложнить.. От DQN перейти к A2C, от A2C к MOPO … и тд и тп…
Одной из наиболее важных точек ветвления в алгоритме RL является вопрос о том, имеет ли агент доступ к модели среды (или изучает ее).
Под моделью среды мы подразумеваем функцию, которая предсказывает переходы состояний и вознаграждения. Алгоритмы, использующие модель, называются методами, основанными на модели model-based, а те, которые не используют модель, называются безмодельными model-free.
Безмодельные методы отказываются от потенциального повышения эффективности выборки за счет использования модели. Поэтому их, как правило, легче реализовать и настроить.
Со своей стороны очень рекомендую, прежде чем принимать решение о том, какой метод RL Вы будете использовать, подумать о том, а годен ли он для Вашей задачи?
Процесс обучения нашей нейронной сети с помощью Deep Q-Learning
Иллюстрация автора
- Инициализируем нейронную сеть
- Выберем действие.
- Обновим веса сети, используя уравнение Беллмана.
Другими словами, мы будем итеративно, на каждом шаге t, обновлять значение, соответствующее состоянию S и заданному действию A, с двумя весовыми частями:
- Текущее значение функции Q для этого состояния и действия
- Награда за такое решение + долгосрочная награда от будущих шагов
Альфа здесь измеряет компромисс между текущим значением и новым вознаграждением (т. е. скоростью обучения), гамма дает вес для долгосрочного вознаграждения.
Кроме того, во время итераций (обучения) в нашей среде мы иногда будем действовать случайным образом с некоторой вероятностью эпсилон — чтобы позволить нашему агенту изучить новые действия и потенциально еще большие награды!
Обновление функции Q в случае аппроксимации нейронной сети будет означать аппроксимацию нашей нейронной сети Q новым значением для данного действия.
Посмотрим на код
С помощью нашего кода мы можем создавать Среду разной протяженности и, при необходимости, зашумлять ее, приближая к реальным условиям:
Примечания по реализации нашего кода
Реализация классов Environment и Agent относительно проста, но я хотел бы еще раз напомнить цикл обучения: итерация происходит в течение N эпох, где каждая эпоха — это общая среда итерации.
Для каждого образца в среде мы:
- Получаем текущее состояние в момент времени t
- Далее получаем функцию значений для всех действий в этом состоянии (наша нейросеть выдаст нам 3 значения)
- Выполняем действие в этом состоянии (например, действуем случайным образом, исследуя)
- Получаем награду за это действие от окружения (см. класс)
- Получаем следующее состояние после текущего (для будущих долгосрочных вознаграждений)
- Потом Сохраним кортеж текущего состояния, следующего состояния, функции значения и вознаграждения за повтор опыта.
- Воспроизведем опыт — подгоним нашу нейронную сеть к некоторым образцам из буфера воспроизведения опыта, чтобы сделать функцию Q более адекватной в отношении того, какие награды мы получаем за действия на этом этапе.
Рекомендую здесь , но изучить статью о том, что лучше тренироваться на некоррелированных мини-пакетах данных, чем на очень коррелированных пошаговых наблюдениях — это помогает обобщению и сходимости.
Агент
Архитектура нашей нейронной сети будет очень похожа на простую нейронную сеть классификации с несколькими классами.
Функции, которые представляют состояние, находятся слева, затем есть скрытые слои с функциями активации, такими как relu, которые допускают нелинейные отношения и сложные взаимодействия, а справа находится выходной слой.
Однако вместо использования функции softmax для преобразования выходных данных в распределение вероятностей выходные данные останутся абсолютными значениями.
Образно говоря, это на самом деле больше похоже на настройку регрессии с несколькими выходами.
Наш Агент:
Тренировка сети
В нашем случае, мы натренируем нашего Агента определять восходящие и нисходящие тренды на синусоиде и потом посмотрим, достаточно ли такой тренировки для решения более сложных задач (зашумленный сигнал и нестационарный временной ряд).
Функцию обучения нейронной сети и полный код можно посмотреть по ссылке на Git автора.
Проверка того, как наш алгоритм предсказывает направление движения тренда на той же синусоиде, на которой обучался
Напомню, что у Агента есть всего 2 действия: купить и продать
Ниже показана разметка сигналов от Агента:
И функция его Вознаграждения:
Синус с разными частотами
Давайте усложним жизнь нашему Агенту — просуммируем 4 функции синуса с разными частотными периодами и попробуем торговать по этим объединенным волнам.
Результат по-прежнему отличный — наше представление рынка четко отражает тенденции, и даже если наша модель была обучена на данных другого типа, она все равно знает, что делать с другой волной.
Зашумленная синусоида
Теперь давайте немного усложним упражнение и добавим гауссов шум во временной ряд без переобучения модели.
Алгоритм, обученный на простой синусоиде по-прежнему справляется с задачей! Теперь есть некоторые запутанные моменты, но в среднем модель все еще узнает, где находятся долгосрочные тренды нашей зашумленной функции синуса.
Проверка алгоритма на реальных данных (акции Tesla)
Осталось проверить, сможем ли мы обогатиться, применив эту же нейронную сеть к реальным котировкам акций. Для этого загрузим котировки акций из yfinance:
Почему вдруг мы не можем получить стабильный результат?
Ответ: в сильной нестационарности временного ряда и том, что наш Агент учился в Среде, сильно отличающейся от той, с которой ему пришлось столкнуться.
Посмотрите на распределение динамики изменения цены акции:
Оно абсолютно случайно!
В реальной жизни, котировки акции носят практически случайный характер: меняется среднее, дисперсия и частота изменений. Поэтому наша нейронная сеть ловит только частные случаи несовершенства рынка и, в такие моменты, Алгоритм увеличивает свое вознаграждение. А в остальное время - теряет.
И последнее..
Почему я не рекомендую учиться на готовых средах и симуляторах типа GYM?
Именно потому, что реальная жизнь очень разнообразна, а краткосрочные движения цены носят случайный характер, мало пользы в обучении RL на основе рафинированных (упрощенных) моделей сред, предлагаемых готовыми симуляторами.
Нужно учиться самостоятельно описывать Среду, Агента и Вознаграждение. Подбирать не модный Алгоритм, а соответствующий задаче. Только тогда Вы поймете, насколько это тонкая работа, требующая понимания взаимосвязи реальных факторов друг с другом и с действиями Агента.
Некоторые ссылки:
Подборка "Нейронные сети в трейдинге"