
Даниэль Канеман в своих работах рассказывал и эмпирически доказывал, что человек значительно сильнее переживает потерю, к примеру, 100$, чем выигрыш такой же суммы. В поведенческой науке это называется Loss aversion — неприятие потерь. То есть эмоции на просадки у нас острее, чем на аналогичные прибыли.
Трейдинг и временные просадки — две стороны одной медали. В этой статье мы расскажем наш кейс не самого удачного старта торгового года, что мы делали во время просадки и какие уроки извлекли.
Полезные материалы, которые хорошо бы изучить перед продолжением:
Видео о просадках в трейдинге
Как начался 2023 год (спойлер: так себе)
За первые 6 месяцев 2023 кривая капитала алгоритмического портфеля закрылась в -11,22%. А максимальная просадка достигала -20%. S&P 500 же стартовал ростом в 14,9%.
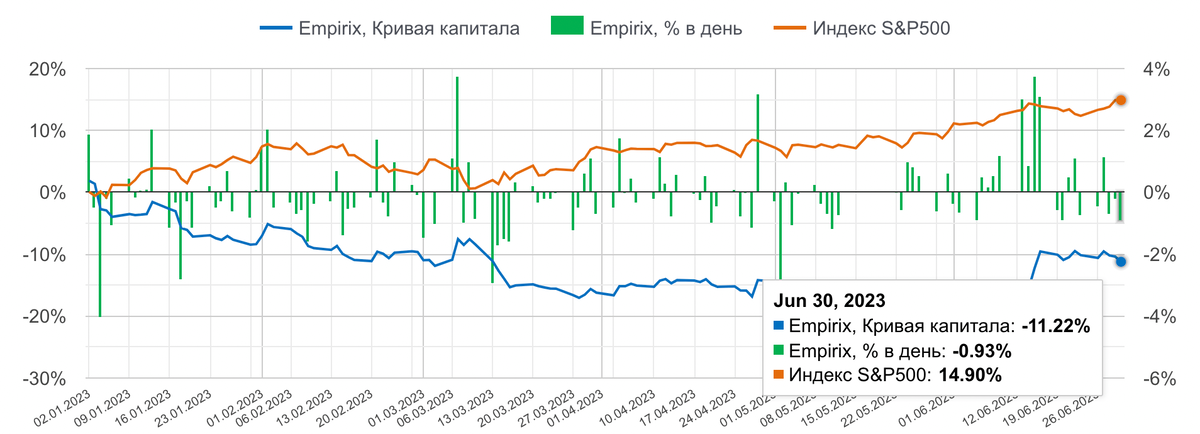
Из всего этого самое неожиданное — мы вышли за рамки допустимой просадки в 15%. И вот какие шаги мы предприняли для проверки всей риск и трейдинг-модели.
За 1 час поможем разобраться с факторами успеха и причинами неудач на финансовых рынках. Бесплатно 🔥
Что мы делали во время незапланированной просадки
Не в наших правилах винить рынок — он никому и ничего не должен. В наших правилах дважды проверить каждую отдельную стратегию, модель риск-менеджмента и найти причину, по которой мы достигли запланированной просадки.
Шаг 1: сравнили доходность исторической модели с лайв-моделью
Это нужно было для того, чтобы убедиться, что мы не переоптимизировали торговые стратегии в процессе их подготовки, и в живой среде они работают так же, как и работали на исторической симуляции.
Вот как выглядит историческая модель (так называемый “миксер” — подробнее о нем еще поговорим ниже) с 2007 года на основе 30-ти алгоритмов:
Кривая капитала выглядит красиво. Но в конце доходность чуть буксует. Сравним последний участок исторической модели с реальной доходностью.
Видим, что бэктест-модель практически один в один совпадает с реальной моделью. То есть просадка — естественный процесс всего портфеля, которая в общей исторической модели особо не заметна. Так мы подтвердили гипотезу, что алгоритмы работают в реальной среде аналогично исторической симуляции.
Подробнее об исторических тестированиях — в статье Тестирование торговых стратегий на исторических данных (бэктест) — почему это так важно? или в видео ниже:
Шаг 2: проверили корреляцию между торговыми стратегиями
Для чего собираются инвестиционные портфели? Для снижения потенциального риска и повышения максимальной доходности. Но при этом корреляция каждого актива в портфеле должна быть низкой — стремиться к нулю.
В нашем случае мы должны были подсчитать корреляцию между поведением алгоритмов. То есть понять, что делает алгоритм А в определенный момент времени, тогда как алгоритм Б открывает сделку в лонг (к примеру).
Технологию самого процесса подсчета рассказывать не будем, но скажем, что корреляция приятно нас удивила — направление и время открытия сделок практически не совпадали.
Пояснение к матрице выше:
- Здесь представлена взаимосвязь между всеми алгоритмами, которые у нас работают в портфеле (на примере выше — 30 штук)
- Корреляцию оценивали примерно как и везде: в диапазоне от -0,3 до 0,3 — низкая корреляция, от – 0,5 до 0,5 — средняя корреляция, ну и все что выше/ниже — высокая корреляция
- Столбец справа — средняя корреляция сделок алгоритма между всеми остальными
То есть мы подтвердили, что сделки у наших алгоритмов имеют нулевую корреляцию (средние значения ни на одном алгоритме не достигли значения даже -0,1/0,1). Портфель работает именно как портфель — распределяет риски между всеми алгоритмами.
Объяснить это можно тем, что значительная часть алгоритмов — среднесрочные. То есть вероятность того, что в один и тот же момент два разных алгоритма откроют две сделки в одном и том же направлении достаточно низка.
Шаг 3: улучшили модель Монте-Карло
Метод Монте-Карло мы используем для подсчета риска на одну сделку для одного алгоритма — так называемый Value at Risk (VaR). Подробнее о методе — в статье Как определить вероятностный результат торговой стратегии, используя метод Монте-Карло или в видео ниже.
Но в нашей версии Монте-Карло 1.0 не было кое-каких элементов, а именно исключения случайных сделок из портфеля и замена их местами. В версии 2.0 мы это сделали и получили более точную риск-модель. Опишем этот процесс подробней — в два этапа.
Этап 1: подготовка "Миксера"
После того, как код стратегии готов, проверен на баги и работоспособность, мы запускаем его в глобальный тест за 15+ лет. На выходе получаем бэктест-доходность. Если бэктест нас устраивает, мы добавляем его к другим стратегиям в портфель. И получаем тот самый “миксер” — склейку из всех алгоритмов, которые прошли все испытания. Выглядит это так:
В итоге мы получаем данные по всем алгоритмам (в нашем случае по 30), среднегодовую доходность, максимальную просадку в зависимости от фракции, коэффициент Шарпа и другие важные метрики. На этом этапе и формируем ориентир для нашей максимальной просадки: в нашем примере при максимальной просадке в 15% риск на сделку равняется 0,32% — то есть если срабатывает стоп-лосс, мы теряем 0,32% от капитала. И это только первый этап в нашей подготовке к Value at Risk, который называется историческим методом — Historical Method.
В нашем Telegram-канале есть то, чего не публикуем в блоге 🙌
Этап 2: подготовка симуляции методом Монте-Карло
Ок, после первого этапа мы получаем большой объем данных:
- 12 159 исторических сделок за 15+ лет тестов по 30-ти стратегиям
- соотношение прибыльных к убыточным
- время открытия и время закрытия сделок
- доходности по этим сделкам
- комиссии и т. д.
Все необходимое, чтобы скормить это Монте-Карло. Скармливаем.
Первый способ, который симулируем в нашем Монте-Карло 2.0 — исключаем случайно выбранные сделки из всего того набора (12 159 сделок). Это называется у нас Random choice. Сперва получаем график:
Что сделал Монте-Карло 2.0? Провел 3000 симуляций на основе наших данных и рандомно исключал сделки (и убыточные, и прибыльные — любые), то есть добавлял как можно больше хаоса в нашу историческую модель. И в итоге дал вот такие значения с нашим условием максимальной просадки в 15%:
Расшифровка:
- Оптимальная фракция (риск на сделку) = 0,23%.
- Риск достижения просадки в 15% — типа 0 (“типа”, потому что в будущем может быть что угодно, но на исторической модели мы хотим сбалансировать наш риск наиболее консервативно).
- Средняя просадка на основе 3000 симуляций = 6,91%.
- Средняя доходность = 34,37%.
Следующий способ — shuffle — замена сделок местами. Обычная перетасовка. График с кривыми получили такой:
И получили данные по результатам такого Монте-Карло.
И здесь получили оптимальную фракцию 0,23% на сделку как и в методе случайного исключения сделок.
Ок, изначально в миксере на основе исторического метода наша фракция была 0,32%, а на основе Монте-Карло с помощью исключения случайных сделок и перетасовки она снизилась до 0,23%. К примеру, если бы мы использовали риск 0,24% или 0,25% на одну сделку, тогда просадка в 15% на симуляции уже бы была достигнута.
По итогу мы пришли к более консервативному риску, который справедливей (на основе миксера мы имеем только одну историческую кривую доходности, на основе Монте-Карло — более 8 000 кривых, то есть 8 000 разных вероятностей).
Заключение
В итоге после проверки всех элементов нашей алгоритмической модели, мы поняли, что слабое место было в нашей фракции — Value at Risk. И если бы использовали оптимизированные методы Монте-Карло до этого, скорее всего, максимальной просадки в 15% не достигли бы.
Ок, какая мораль этой истории:
- Просадки никуда не деваются. Иногда они затяжные. Достойно проходить их — задача любого трейдера.
- Вы должны определить свой уровень Risk of ruin — уровень максимальной просадки, который готовы терпеть. От этого будет формироваться вся остальная риск-модель.
- Просадки становятся не такими страшными, если вы подтверждаете на данных свои торговые гипотезы. Для ручных интуитивных трейдеров все это контролировать сложнее — нет статистической основы.