Kafka - это высокопроизводительная, масштабируемая и устойчивая система обмена сообщениями, созданная внутри компании LinkedIn и ставшая популярным инструментом для обработки потоков данных в реальном времени. Она предназначена для работы с большим объемом данных и обеспечивает надежную доставку сообщений между различными компонентами системы.

Kafka основана на принципах распределенной очереди событий (publish-subscribe), где сообщения публикуются в топики, а затем потребители могут подписаться на эти топики и получать сообщения в режиме реального времени. Поставка сообщений в Kafka гарантируется благодаря ее постоянному хранению на диске с возможностью репликации и резервирования данных.
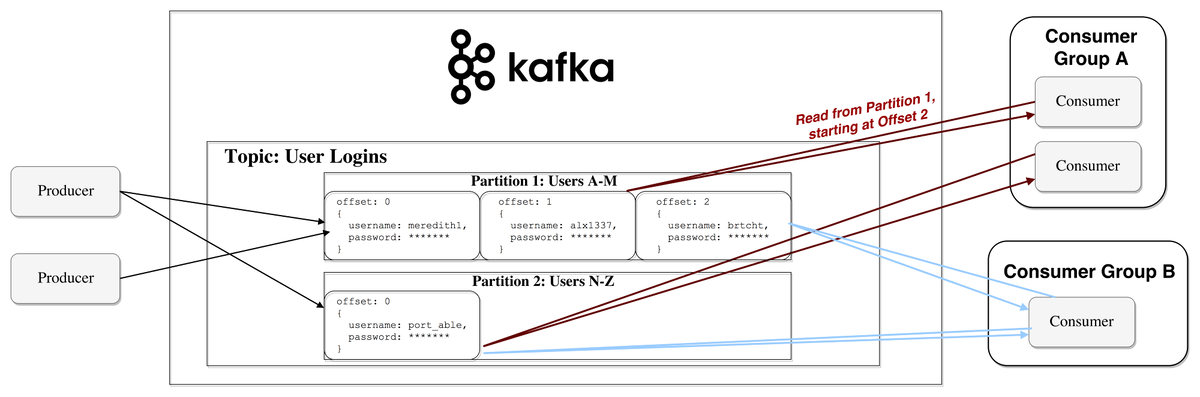
Архитектура Kafka состоит из следующих компонентов:
- Брокеры Kafka: Кластер Kafka состоит из одного или нескольких брокеров, которые являются основными узлами обработки данных. Брокеры берут на себя ответственность за хранение данных, обеспечивают репликацию топиков и принимают запросы от клиентов.
- Топики: В Kafka сообщения группируются в топики. Топики представляют собой категории, к которым можно публиковать и из которых можно потреблять данные. Каждое сообщение, отправленное в Kafka, ассоциируется с определенным топиком.
- Производители: Производители публикуют сообщения в топики. Они отвечают за создание и инициализацию сообщений и отправляют их на брокеры. При отправке производители могут выбирать, в какой раздел топика отправить сообщение, или позволить брокерам самим выбирать раздел.
- Потребители: Потребители подписываются на топики и получают сообщения в режиме подписки на события. Они могут читать сообщения сразу после публикации или продвигаться по курсору, чтобы получить старые сообщения. Потребители работают в группах, что позволяет масштабировать обработку сообщений.
- Консюмеры: Консюмеры представляют собой клиентов, которые обрабатывают и анализируют полученные данные из Kafka. Они могут использовать Kafka Streams для агрегации, фильтрации, трансформации и обработки данных в реальном времени.
Надежность и масштабируемость являются ключевыми преимуществами Kafka. Она сочетает высокую производительность с поддержкой множества производителей и потребителей, а также способностью генерировать и обрабатывать огромные объемы сообщений.
Кластер Kafka способен обрабатывать миллионы сообщений в секунду и поддерживать множество терабайтов данных, благодаря распределению загрузки между брокерами и возможности горизонтального масштабирования.
Кроме того, Kafka обладает рядом дополнительных возможностей:
Устойчивость: Kafka сохраняет сообщения на диске, что обеспечивает долгосрочное хранение и восстановление данных в случае сбойных ситуаций. Каждое сообщение имеет уникальный идентификатор (offset), которым определяется положение сообщения в логе, что позволяет точно воссоздать последовательность событий.
Масштабируемость: Kafka способна масштабироваться горизонтально, позволяя добавлять новые брокеры и распределять нагрузку, чтобы обеспечить обработку большого количества данных. Также производители и потребители могут быть разделены на разные группы, что позволяет гибко масштабировать обработку сообщений.
Эффективность: Kafka работает с очень низкой задержкой и обеспечивает высокую пропускную способность при передаче сообщений. Благодаря своей асинхронной природе и оптимизированному хранению данных на диске, Kafka способна обрабатывать сообщения с высокой эффективностью.
Гарантированная доставка: Kafka обеспечивает гарантированную доставку сообщений, что позволяет строить надежные и устойчивые системы. Producer и consumer могут настраивать различные уровни подтверждения, например, подтверждение только после записи на диск, чтобы обеспечить даже более высокую надежность.
Интеграция с экосистемой Big Data: Kafka стал основным компонентом экосистемы Big Data, поскольку хорошо интегрируется с платформами типа Hadoop, Spark, Flink и другими инструментами для обработки данных в реальном времени. Это делает Kafka центральным элементом передачи данных и взаимодействия между различными системами.
В целом, Kafka представляет собой мощное решение для обработки потоков данных в реальном времени с высокой производительностью, устойчивостью и масштабируемостью. Она нашла широкое применение во многих областях, таких как аналитика, обработка событий, мониторинг и других сценариях, где требуется надежная передача и обработка больших объемов данных.