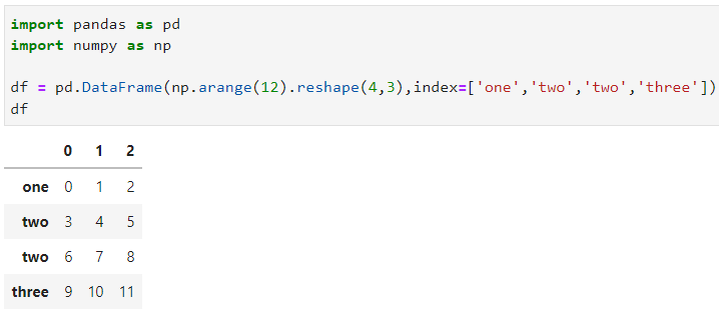
При наличии дубликатов в индексах традиционные способы удаления строк могут привести к неожиданных результатам. Рассмотрим датафрейм:
Допустим, мы хотим исключить последний повтор (2 строка, начиная от 0). При работе с именами индексов мы не достигнем желаемого результата:
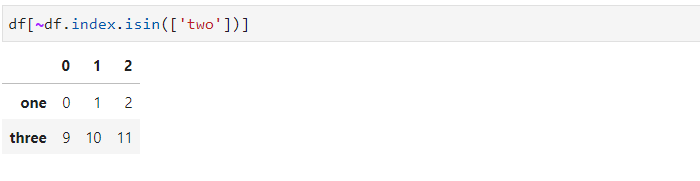
Встречается и такой вариант:
То есть исключения индекса "two" приводит к удалению обеих строк.
Методы удаления дубликатов из индексов так же не работают, так как при адресации по повторяющемуся индексу извлекаются все повторы (подробнее здесь):
Теперь перейдем к тому, как правильно избавляться от дублей в индексе. Например, можно сгруппировать по уникальным значениям индекса (level=0) с выбором первого или последнего значений для дублей:
Альтернативой является перенос индекса в колонки датафрейма и использование мощи метода drop_duplicates с параметром subset:
Другой способ - выбрать порядковые номер дубликатов и избавиться от них: