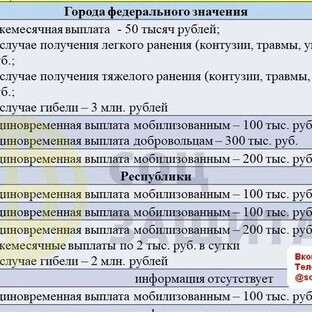
Задачи классификации зачастую характеризуются несбалансированностью классов, когда наблюдения одного типа сильно превалируют над другими. При этом такая ситуация может иметь естественные причины, например, опрашивая 10000 человек для создания выборки о диагностики рака, разумно ожидать, что соотношение заболевших и здоровых будет не равным.
Соответственно, разбиение данных при формировании тренировочной и тестовой выборок должно проводиться с учетом такой несбалансированности. Иначе вы можете обучить модель на датасете из всех здоровых людей и, тем самым, никакой информации о болезни она не получит. Технически это выразится в том, что модель будет склонна всегда прогнозировать, что человек здоров (и для обучения она будет идеальна).
Рассмотрим методы создания выборок с сохранением (по-возможности) баланса классов в тренировочной и тестовой выборках. Для начала создадим датафрейм:
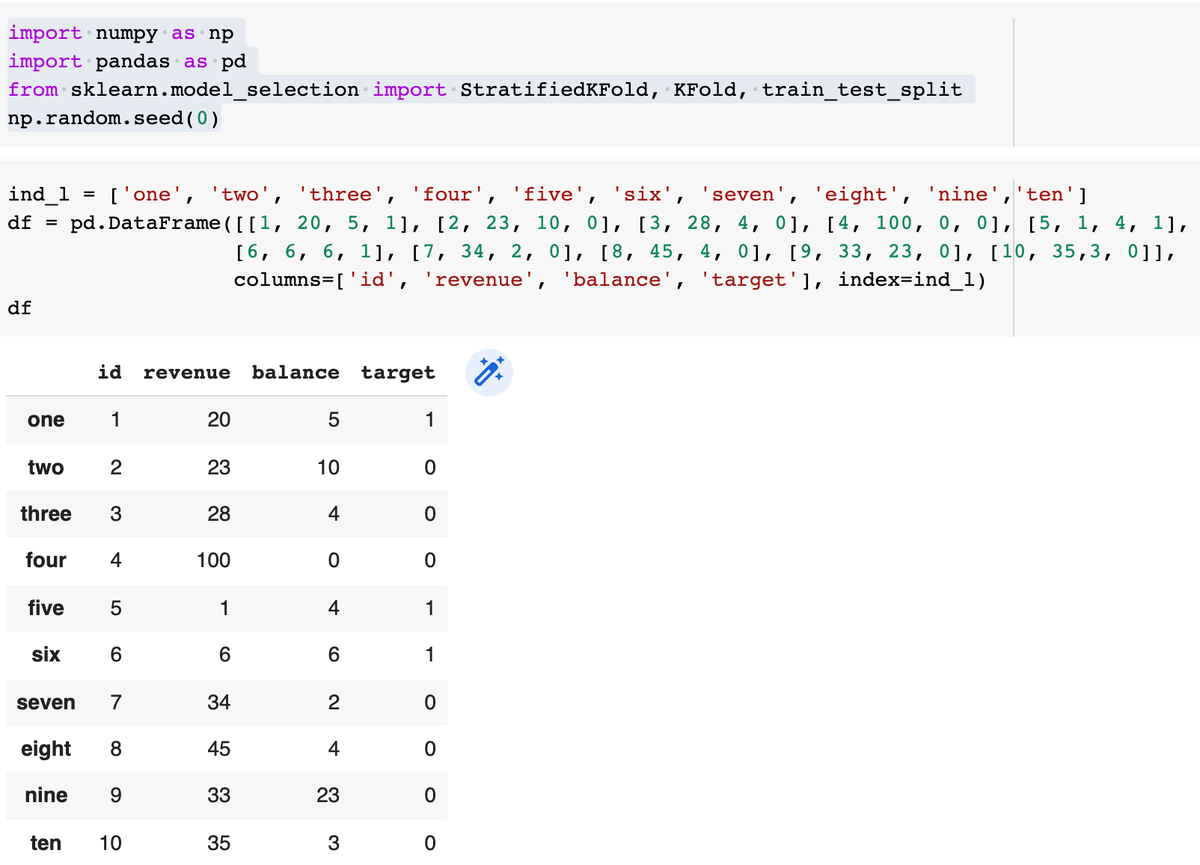
Если воспользоваться обычным методом кросс-валидации - KFold, то получим следующее:

Данный метод не сохраняет пропорции между классами, чтобы это исправить можно воспользоваться StratifiedKFold:
Как видим, StratifiedKFold по-возможности сохраняет пропорции. При этом в первом случае не получилось идеально сбалансировать в силу размера нашей выборки - 10 наблюдений, 3 фолда (в один попадают 4 элемента тестовых, один из них класса - 1).
Если проводить разбиение методом train_test_split, используйте параметр stratify:
Во втором случае лучше удалось сохранить соотношение, однако так же из-за размера данных (10), тестовой выборки (2), лучшим вариантом было оставить в тесте одно наблюдение класса 1 и одно класса 0.