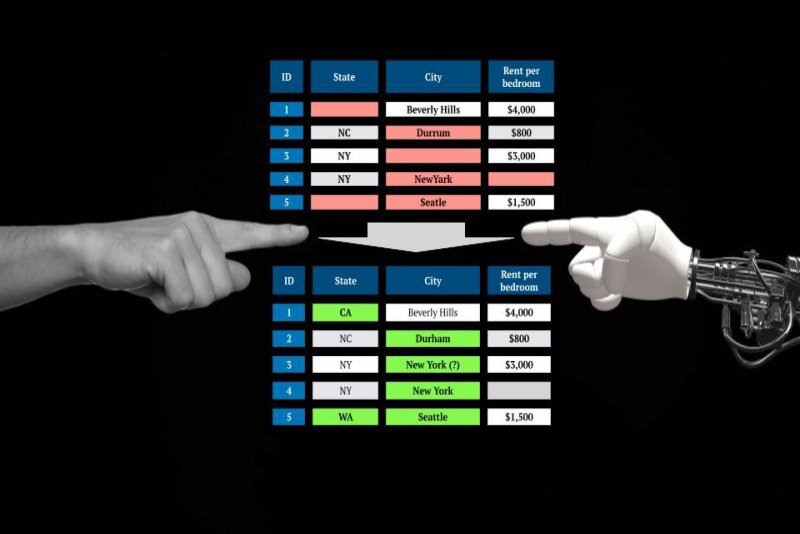
Попробуйте PClean - новая система от исследователей MIT, написанная на предметно-ориентированном вероятностном языке программирования для автоматической очистки данных. Она удаляет опечатки, дубликаты, пропущенные значения, орфографические ошибки и несоответствия, облегчая подготовку датасета к анализу и ML-моделированию. Примечательно, что PClean не просто механически очищает данные, а учитывает их семантику с помощью обобщенных моделей здравого смысла для суждений, которые можно настроить для конкретных баз данных и типов ошибок.
Идея вероятностной очистки данных на базе декларативного и обобщенного знания о контексте исследований – не новая. Впервые она прозвучала в статье 2003 года сотрудников Калифорнийского университета Беркли с предположением, что такой подход потенциально может обеспечить гораздо большую точность, чем другие популярные методы машинного обучения. PClean развивает эту мысль с учетом тренда на «объяснимый ИИ» – применение реалистичных моделей человеческих знаний для интерпретации данных. Исправления в PClean основаны на байесовских рассуждениях, когда каждому альтернативному объяснению неоднозначных данных присваивается некоторый вес и к имеющимся данным применяются вероятности, основанные на предварительных знаниях. Дополнительным преимуществом PClean является возможность чистить действительно большие объемы данных, причем сравнительно быстро. Например, недавнее исследование 2021 года на таблице с медицинскими данными из 2,2 миллионов строк, PClean нашел более 8000 ошибок всего за 7,5 часов. Наконец, благодаря принципу байесовской вероятности, PClean может давать откалиброванные оценки своей неопределенности, которые можно подкорректировать вручную, обучая таким образом ИИ-систему.
https://news.mit.edu/2021/system-cleans-messy-data-tables-automatically-0511