Сегодня мы продолжим говорить о переходе с монолита на микросервисы. Многие задумываются над этим, когда наступает необходимость, но не все знают, как и с чего начать. В компании Авито сейчас как раз решают эту задачу и готовы поделиться своим опытом, поэтому рассказ пойдет от имени их специалиста.
В предыдущей части Микросервисы для чайников: как на них перейти с монолита с нуля. Часть 1 я рассказал, как в Авито пришли к переходу от монолитной архитектуры к микросервисам. Какие классическое схемы веб-серверного приложения и приложения на микросервисной архитектуре есть. Можете прочитать об этом подробнее, а мы пойдём дальше.
Меня зовут Семен Катаев, я работаю в Авито над процессом перехода от монолитной архитектуры к микросервисам. Переход у нас все еще продолжается, но мне уже есть чем с вами поделиться. Это краткий обзор того, с чем придётся столкнуться, если вы задумались над созданием надежного, масштабируемого, распределённого приложения.

Runtime для 10 000+ приложений
Откуда взялась цифра 10 тысяч, если до этого я говорил про тысячу микросервисов? У нас все микросервисы скейлятся горизонтально: для слабонагруженных сервисов это минимум 3 экземпляра, а для высоко нагруженных (поиск, рекомендации, сервис пользователей) может быть до 50-100. В среднем получается примерно 10 инстансов на микросервис, и это дает цифру в 10000 микроприложений.
А еще у них есть вспомогательные компоненты. У каждого микросервиса может быть свой pgBouncer, stats-daemon, HAProxy, nginx. Эта цифра может спокойно подняться до десятков тысяч микроприложений, и все их нужно как-то запускать.
Есть похожая алгоритмическая задача по наполнению рюкзака.
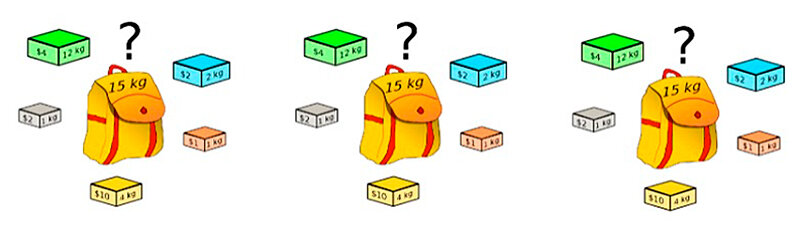
По условию у вас рюкзак заданной вместимости и грузы, которые надо в него уложить максимально эффективно. Рюкзаки — это наши сервера, их тысячи. А грузы — это наши микросервисы, и их десятки тысяч. Нужно их так разложить, чтобы не было переполненных рюкзаков, и все они были загружены на одном уровне. Задача может усложниться правилами: 1) в один рюкзак нельзя положить больше, чем два зеленых груза, 2) к одному синему грузу необходимо добавлять оранжевый и 3) в каждом рюкзаке должен быть один серый груз. Эти правила называются политиками Affinity и Anti-Affinity, и они делают задачу практически нерешаемой вручную. Найти ответ можно перебором и оптимизациями из динамического программирования.
Когда у нас было всего 5-10 микросервисов, DevOps’ы пытались подбирать сервера под каждый микросервис с определенным профилем нагрузки. Но с ростом количества микросервисов делать это вручную стало слишком долго, поэтому нужны инструменты scheduling & Orchestration.
Scheduling & Orchestration
Если вы только хотите идти в микросервисы, обратите внимание на фонд Cloud Native Computing Foundation. Он был анонсирован в 2015 году вместе с Kubernetes 1.0. Его цель — развитие технологий контейнеризации приложений, и его поддерживают множество компаний.
Участники фонда развивают те самые инструменты оркестрации и шедулинга, из которых вы можете подобрать себе подходящий. Я не буду сравнивать, чем они отличаются и какая у них архитектура, а только скажу что верхнеуровнево, все они решают общую задачу. Они все состоят из N серверов, на которых запускаются микросервисы:
Например, в Авито около тысячи серверов в кластере Kubernetes. Есть несколько мастеров, которые управляют этим кластером. У мастеров есть свой storage. В Kubernetes по умолчанию используется etcd (disributed key-value storage). Также мастера предоставляют API для работы command-line interface (CLI) утилит и UI-дашбордов.
Мастер Kubernetes решает за вас, на каких нодах запустить микросервисы. Ноды могут появляться и исчезать, то есть вы можете вводить в эксплуатацию и выводить из эксплуатации новые сервера и микросервисы сами станут «перезапускаться» на наиболее свободных. У вас не будет привязки к конкретному железу. Это особенно эффективно на масштабах от тысячи серверов/приложений.
Container Runtime
Когда у вас вместо одного монолита сотни независимых приложений на одном сервере, надо как-то распределять ресурсы. Чтобы не было «плохих» соседей, когда один микросервис начинает утилизировать все CPU сервера, забивает всю сеть или память, не давая работать другим микросервисам.
Чтобы этого избежать, нужна контейнеризация приложения. Это метод виртуализации, когда приложение запускается в изолированных пространствах пользователей. Вы можете для каждого микросервиса указать, сколько ресурсов CPU, сети, памяти он может использовать. Если сервис пытается использовать, например, больше CPU, то он ограничивается, чтобы оставалось процессорное время для работы других микросервисов.
В Cloud Native Computing Foundation есть множество инструментов для контейнеризации:
Фонд пропагандирует модульный подход — делать так, чтобы каждый компонент можно было заменить. Поэтому все инструменты для Container Runtime заменяемые, верхнеуровнево похоже работают и предоставляют одинаковый API (container runtime interface).
Сам микросервис в контейнере может быть не только одним запущенным приложением, а, например, представлять собой собранный бинарник Golang или php-fpm демон. Также в инстанс микросервиса может входить nginx, haproxy для high availability до внешних ресурсов, pgBouncer, Redis как key-value storage (для каждого экземпляра микросервиса тоже можно так делать), rsyslog для сбора логов. И все эти N контейнеров будут одним инстансом приложения.
Как я уже говорил, мы масштабируемся горизонтально, равномерно распределяя по ним. На схеме 6 реплик одного микросервиса, по которым равномерно будет распределять нагрузка.
Так как микросервисы — это, по сути, наботы контейнеров, а контейнер — это запущенное приложение на базе какого-то образа (image), то нужно где-то хранить собранные образы приложений.
Читать продолжение статьи Микросервисы для чайников: как на них перейти с монолита с нуля. Часть 3
Команда «Онтико» готова помочь тем, кто потерял работу из-за санкций и их последствий.
Заполните анкету и её увидят более 100 потенциальных работодателей.
Если у вас есть друзья, которым актуальна помощь, перешлите им это сообщение.