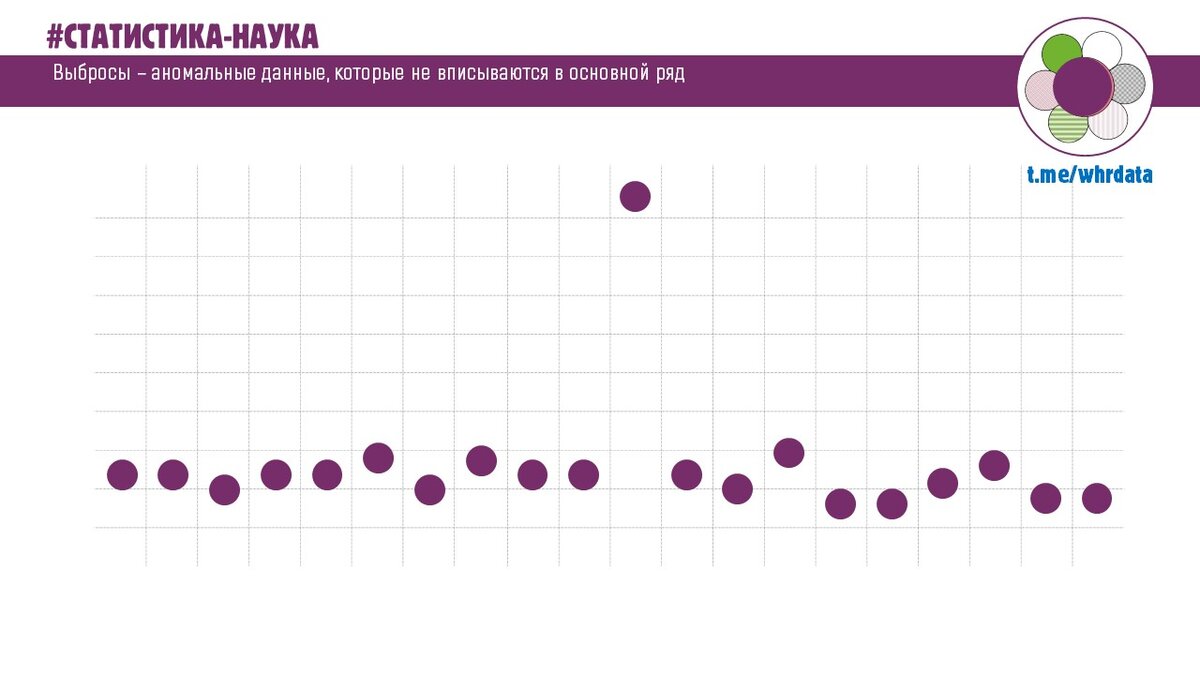
Аномалии, или "выбросы" - это значительные отклонения от тренда.
Причинами аномалий могут быть:
* ошибки в данных, и тогда надо искать причину и устранять ее в источнике данных.
* объективные внешние причины, и тогда это инсайты, которые нам очень интересны.
Аномалии могут быть:
Краткосрочные – мы видим, что динамика кого-то показателя (напр. текучесть по неделям) находится в определенном диапазоне. И тут – бац – растет вверх. И это «аномалия» - или ошибка в данных или повод для дальнейшего исследования.
Долгосрочные – сначала мы видим, что тренд идет скорее на повышение или «боковик» - ни вверх ни вниз. Но затем, график уходит вниз – снова повод разобраться дальше и создать ценность аналитики.
Другая классификация:
у нас может быть аномалия в каком-то конкретном месте, аномалия относительно контекста (был сезонный спад текучести и тут бац – пошла вверх), или в нескольких показателях сразу – текучесть, отказы от офферов и зарплатные ожидания на конкретную позицию.
Последним примером мы намекаем на то, что мог резко ухудшиться бренд работодателя – вышла какая-то негативная новость о нашей компании.
Методы выявления (детектирования) аномалий могут быть:
* визуальные (осмотр ряда данных, графиков и диаграмм, условное форматирование)
* статистические (например, через стандартное отклонение, разницу между процентилями и т.п.)
* машинное обучение (метод DBSCAN и подобное)
Визуальный поиск выбросов - это довольно просто, он виден невооруженным взглядом.
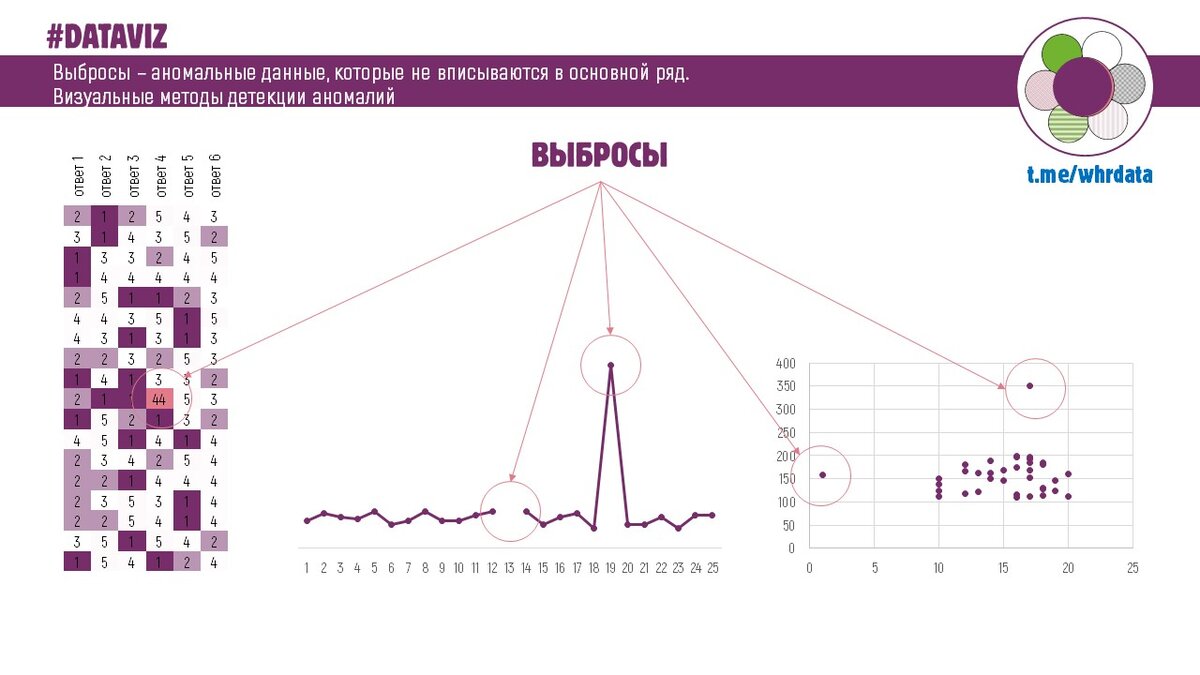
Визуальный поиск выбросов - это довольно просто, он виден невооруженным взглядом.
Главное тут нарисовать правильную картинку из данных, сделать это так, чтобы эти самые выбросы стали заметны.
1. Условное форматирование в Excel
Раскрашивание таблицы данных разными цветами позволяет сделать анализ значений в таблице более простым и быстрым.
(!) Не забывайте, что в excel можно настроить форматирование под свою задачу:
*выбрать 2х и 3х цветную шкалу (https://t.me/whrdata/93)
*подобрать цвета
*использовать разные варианты деления на интервалы
2. Простой линейный график.
"Выколотые" значения на временном ряду покажут отсутствие данных, нулевые значения или аномально большие значения.
И это те значения, с которыми надо разбираться отдельно.
3. Диаграмма рассеяния (точечная диаграмма, scatter plot)
Сильно отклоняющиеся от основного "массива" точки также показывают, что эти данные ведут себя не так как другие и это надо поисследовать.
Статистические методы:
А вот тут пошла жара. Давайте сначала разберемся с понятиями.
Метод 1.
Стандартное отклонение – это способ количественно описать, насколько данные разбросаны вокруг среднего – насколько в среднем ошибается наше среднее. На картинке ниже у красного графика стандартное отклонение низкое (почти все значения сгруппированы вокруг среднего), у синего – высокое (все значения «размазаны» по шкале Х)
Скользящее среднее – это среднее за выбранный период, например, за 3 месяца, которое сдвигается вместе с передвижением нашего «фокуса» - для периода янв-фев-мар оно будет одно, для периода мар-апр-май – другое.
А α – это настраиваемый нами параметр.
В итоге, мы можем говорить «мы будем считать аномалией те данные, которые отклоняются от скользящего среднего более, чем на α стандартных отклонений за этот же период». В меньшую (левая сторона формулы) или в большую (правая сторона) сторону. За α можно принять как 0.5, так и 2 – в первом случае наш цензор будет менее избирательным (все, что хоть немного отклоняется – аномалия), во втором – более избирательными.
Учет стандартного отклонения очень важен – в зависимости от того, насколько наш график «прыгает» (вариативен), критерий для «аномалий» должен быть разный
Такой расчет избавляет нас от необходимости просматривать множество графиков и решать «на глаз». Хотя и не до конца :)
Метод 2.
Сначала «по понятиям»
Квантили – это те же «процентили». То есть квантиль 0,25 или 25 процентиль или первый квартиль (четверть) – то значение в нашей выборке, ниже которого 25% значений. А медиана – это 50-тый процентиль – ниже и выше нее 50 значений.
Межквартильный размах. Тут проще на примере. Допустим, в нашей выборке 25й процентиль = 5, 50й процентиль = 7, 75й процентиль – 8. Межквартильный размах – это разница между 75м процентилем и 25м, между третьей четвертью (квартилем) и первой. В нашем случае это 3.
И в нашем примере если взять альфу 1, то мы будем считать аномалиями те данные, которые ниже нашего 25ого процентиля на один межквартильный размах, то есть ниже 5-3=2.
Или же выше 75ого процентиля на один IQR, то есть выше, чем 8+3=11.
Методы на основе машинного обучения
Метод DBSCAN
А вот тут в ход пошло машинное обучение.
Метод DBSCAN – это метод, который группирует, кластеризует данные, учитывая их плотность. На графике мы видим, что есть две группы данных с определенной «плотностью». Но есть одна точка, которая не только далеко отстоит от этих групп, но еще и не вписывается в паттерн плотности. Согласно паттерну, который здесь определил алгоритм, вокруг каждой точки должно быть Х точек и в определенной близости. Точка-аномалия находится достаточно близко от крайней точки другой группы, но рядом с ней больше нет никого в обозримой близости – значит, она не принадлежит этой группе и оказалось так близко случайно.
Подробнее про этот алгоритм и его объяснение «на пальцах» можно прочитать здесь https://habr.com/ru/post/322034/
а про его сравнение с наиболее простым методом кластеризации «к-средних» можно прочитать здесь https://towardsdatascience.com/k-means-vs-dbscan-clustering-49f8e627de27
Метод Local Outlier Factor
Здесь используется похожий метод, только алгоритм учитывает не общий паттерн плотности по всей выборки, а плотность данных в конкретных местах условного графика. Там, где плотность данных выше (данные кучкуются сильнее) выбросом будут считаться одни значения, там, где плотность данных ниже – другие. Посмотрите на картинку – на ней точка p2 считается выбросом потому что рядом с ней находятся плотные значения. Если бы она была в правом верхнем углу графика – возле группы С1 – она бы выбросом не считалась – там плотность значений.
Итого, кажущиеся сложными методы оказываются удивительно логичны, если уметь их объяснить простыми словами. К сожалению, даже на специальных курсах по анализу данных и машинному обучению такое встречается нечасто. Но кто ищет, тот всегда поймет :)
А еще давайте все повышать свой уровень знаний в анализе данных для того, чтобы наши суждения были столь же обоснованы, как суждения в некоторых других сферах в некоторых других компаниях :)
Артемий Молоснов, HR-аналитик
при поддержки ТГ канала "Красивая аналитика"