Следует запомнить эти рекомендации, чтобы избежать сюрпризов с обработкой файлов в будущем. Сам я о них вовремя не узнал и потерял много времени на выявление постоянно возникавших ошибок.
Изучение вопроса проведем на примере сгенерированного игрушечного набора data (код представлен в конце статьи) о заработке людей из разных городов (идентифицируются по индексу) следующего вида:
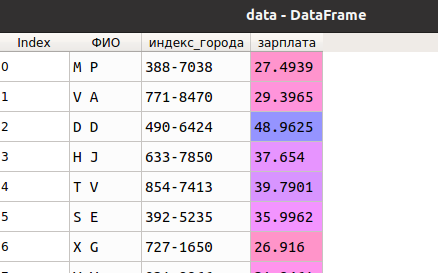
Некорректное распознавание строк
Поле "индекс_города" состоит из семи случайных цифр от 0 до 9, которые в некоторых случаях разделяются символами "/" или "-". После сохранения data в файл и загрузки обратно в df не все значения этого поля корректно распознаются. Например, при выдаче длин строк в ячейках "индекс_города" (всего 100) получаем следующее:

Найдем значения, длины которых не распознаны:
Похоже не распознаны строки с индексами, которые выглядят как числа (то есть не разделены "/" или "-"). Для борьбы с эти следует явно привести столбец к строчному типу:
df['индекс_города'] = df['индекс_города'].astype(str)
Теперь повторно получим длины строк в ячейках "индекс_города" :
Строки из цифр, начинающихся с нуля
То же поле "индекс_города" после сохранения сгенерированных данных в файл и загрузки в таблицу df предоставляет очередной сюрприз. В частности, появляется индекс города, содержащий только 6 символов, что видно из предыдущей картинки.
Оказывается, в первоначальной таблице содержался индекс 0319966, который после сохранения в Excel таблицу и загрузки обратно потерял первый символ. Вероятно, это обусловлено тем фактом, что текстовый процессор воспринимает последовательность цифр как число и не видит смысла в начальном 0. Для справки, если вы попытаетесь в Microsoft Excel или Google Таблицах сохранить в ячейке аналогичную последовательность символов, то 0 будет потерян.
Проблема решается путем чтения файлов функциями Pandas (read_excel или read_csv ) с параметром dtype ='str' . Кстати, этим же способом можно решить и первую проблему.
Числа с плавающей точкой
Поле "зарплата " также заставляет нас помучиться. В частности, процедура выгрузки-загрузки данных приводит к изменениям в количестве сохраняемых символов после запятой. Однако установить это не так просто. Попытаемся вывести все значения зарплаты, которые не совпадают у одних и тех же людей:
Различия не визуализируются, кажется, что сохранение происходит до 4 символа. Однако, если вывести эти же данные в командную строку, получим другой результат:
Если же просмотреть файл с данными, то получим "третью" версию точности сохранения:
Мораль из этого проста - перед сохранением округляем данные до требуемой точности:
data['зарплата'] = np.round(data['зарплата'],2)
Теперь расхождений не будет:
Таким образом, можно сделать следующие выводы:
- в определенных случаях читаем файлы с параметром dtype ='str' и явно приводим поля к соответствующим им типам;
- перед сохранением значений с плавающей точкой, округляем их.
Ниже привожу код для генерации данных:
Код можно скопировать в удобном виде с моей страницы в teletype.in.